 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Conditional Representation Learning for Drum Sample Retrieval by Vocalisation
Paper and Code

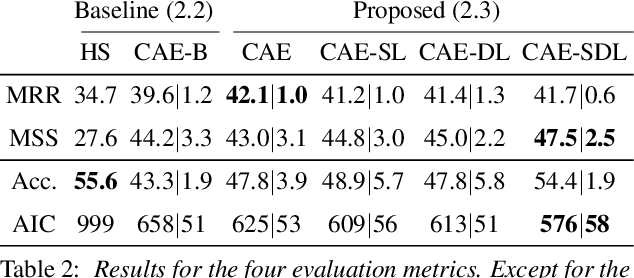
Imitating musical instruments with the human voice is an efficient way of communicating ideas between music producers, from sketching melody lines to clarifying desired sonorities. For this reason, there is an increasing interest in building applications that allow artists to efficiently pick target samples from big sound libraries just by imitating them vocally. In this study, we investigated the potential of conditional autoencoder models to learn informative features for Drum Sample Retrieval by Vocalisation (DSRV). We assessed the usefulness of their embeddings using four evaluation metrics, two of them relative to their acoustic properties and two of them relative to their perceptual properties via human listeners' similarity ratings. Results suggest that models conditioned on both sound-type labels (drum vs imitation) and drum-type labels (kick vs snare vs closed hi-hat vs opened hi-hat) learn the most informative embeddings for DSRV. We finally looked into individual differences in vocal imitation style via the Mantel test and found salient differences among participants, highlighting the importance of user information when designing DSRV systems.