 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLow Resource Audio-to-Lyrics Alignment From Polyphonic Music Recordings
Paper and Code
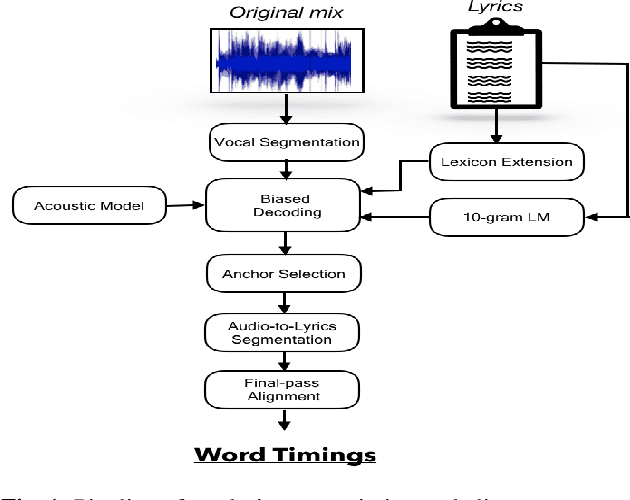
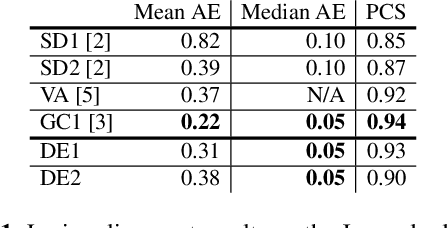
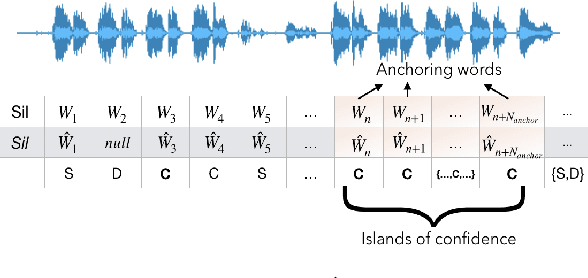
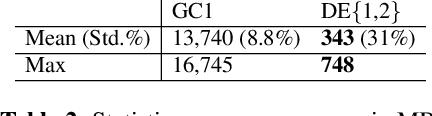
Lyrics alignment in long music recordings can be memory exhaustive when performed in a single pass. In this study, we present a novel method that performs audio-to-lyrics alignment with a low memory consumption footprint regardless of the duration of the music recording. The proposed system first spots the anchoring words within the audio signal. With respect to these anchors, the recording is then segmented and a second-pass alignment is performed to obtain the word timings. We show that our audio-to-lyrics alignment system performs competitively with the state-of-the-art, while requiring much less computational resources. In addition, we utilise our lyrics alignment system to segment the music recordings into sentence-level chunks. Notably on the segmented recordings, we report the lyrics transcription scores on a number of benchmark test sets. Finally, our experiments highlight the importance of the source separation step for good performance on the transcription and alignment tasks. For reproducibility, we publicly share our code with the research community.