Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTimbreCLIP: Connecting Timbre to Text and Images
Paper and Code
Nov 21, 2022


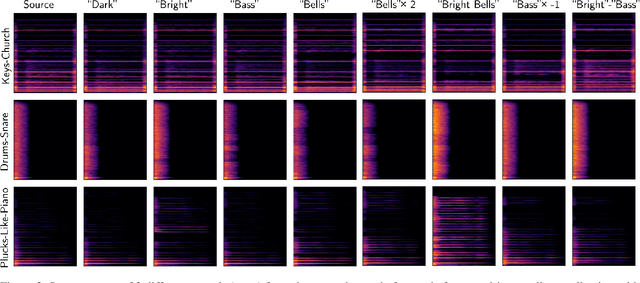
We present work in progress on TimbreCLIP, an audio-text cross modal embedding trained on single instrument notes. We evaluate the models with a cross-modal retrieval task on synth patches. Finally, we demonstrate the application of TimbreCLIP on two tasks: text-driven audio equalization and timbre to image generation.
* Submitted to AAAI workshop on creative AI across modalities
View paper on