Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSYMPLEX: Controllable Symbolic Music Generation using Simplex Diffusion with Vocabulary Priors
Paper and Code
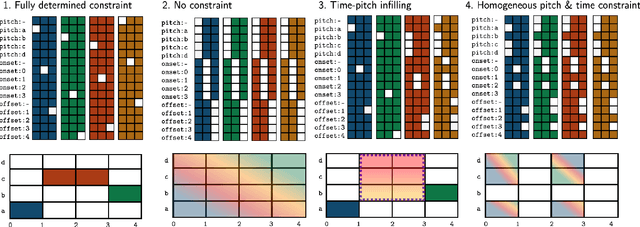
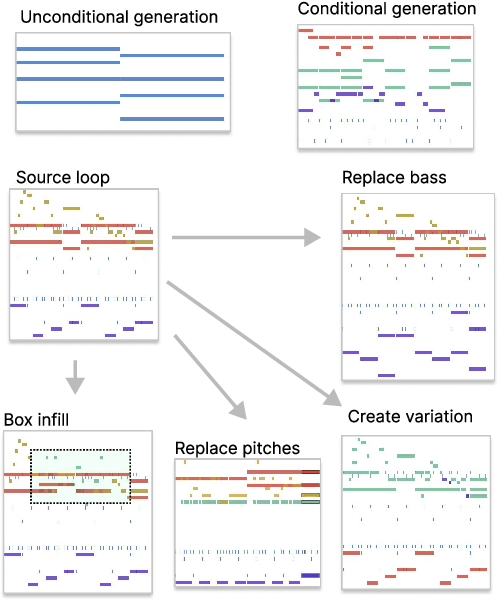
We present a new approach for fast and controllable generation of symbolic music based on the simplex diffusion, which is essentially a diffusion process operating on probabilities rather than the signal space. This objective has been applied in domains such as natural language processing but here we apply it to generating 4-bar multi-instrument music loops using an orderless representation. We show that our model can be steered with vocabulary priors, which affords a considerable level control over the music generation process, for instance, infilling in time and pitch and choice of instrumentation -- all without task-specific model adaptation or applying extrinsic control.
View paper on