 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBasic Filters for Convolutional Neural Networks Applied to Music: Training or Design?
Sep 19, 2018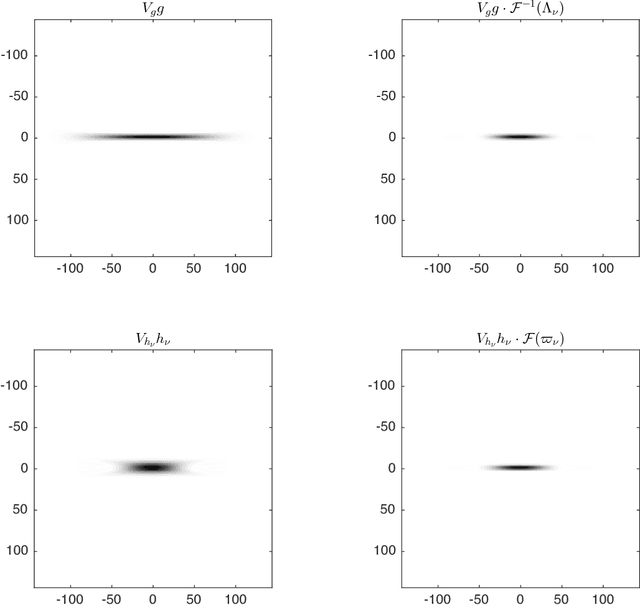
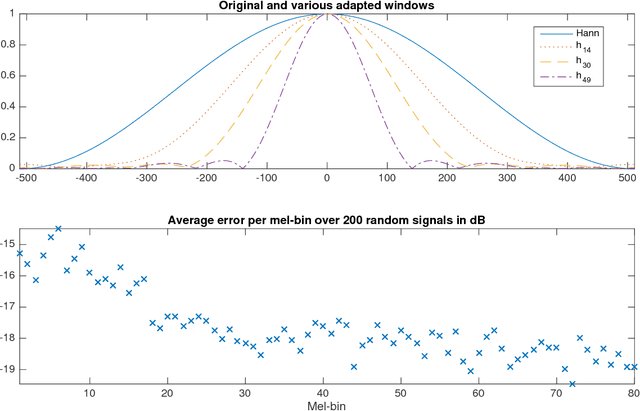
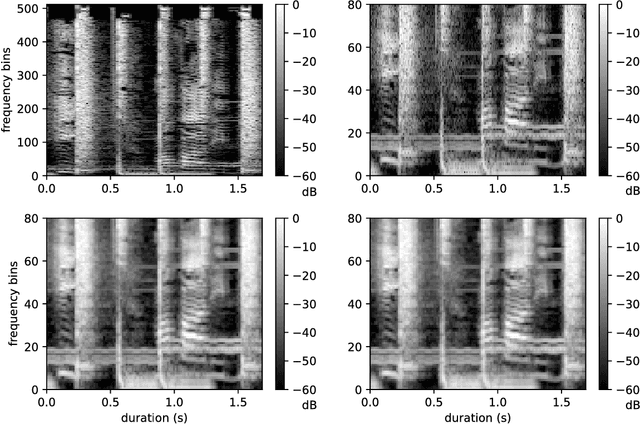
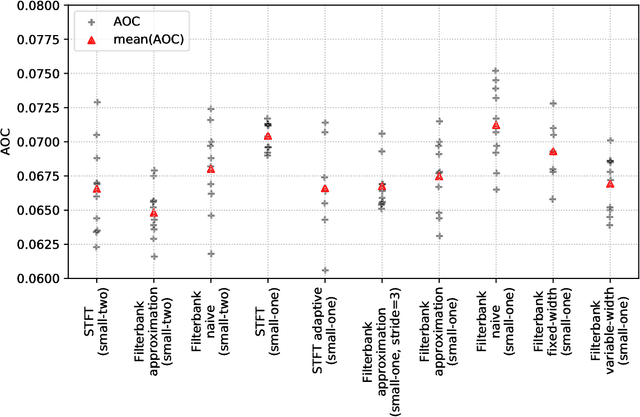
When convolutional neural networks are used to tackle learning problems based on music or, more generally, time series data, raw one-dimensional data are commonly pre-processed to obtain spectrogram or mel-spectrogram coefficients, which are then used as input to the actual neural network. In this contribution, we investigate, both theoretically and experimentally, the influence of this pre-processing step on the network's performance and pose the question, whether replacing it by applying adaptive or learned filters directly to the raw data, can improve learning success. The theoretical results show that approximately reproducing mel-spectrogram coefficients by applying adaptive filters and subsequent time-averaging is in principle possible. We also conducted extensive experimental work on the task of singing voice detection in music. The results of these experiments show that for classification based on Convolutional Neural Networks the features obtained from adaptive filter banks followed by time-averaging perform better than the canonical Fourier-transform-based mel-spectrogram coefficients. Alternative adaptive approaches with center frequencies or time-averaging lengths learned from training data perform equally well.