 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBlood vessel segmentation in en-face OCTA images: a frequency based method
Sep 13, 2021
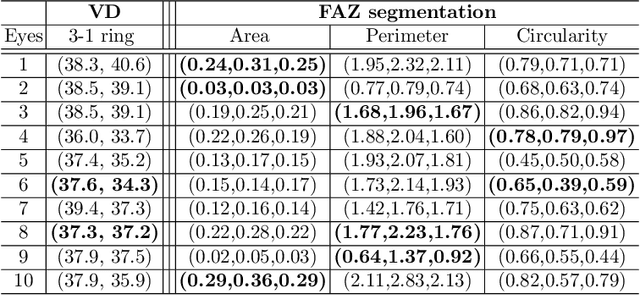
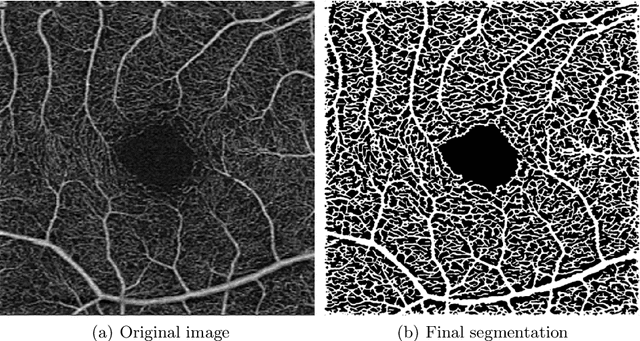
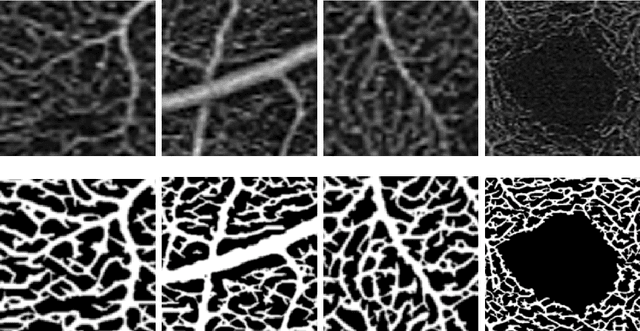
Optical coherence tomography angiography (OCTA) is a novel noninvasive imaging modality for visualization of retinal blood flow in the human retina. Using specific OCTA imaging biomarkers for the identification of pathologies, automated image segmentations of the blood vessels can improve subsequent analysis and diagnosis. We present a novel method for the vessel identification based on frequency representations of the image, in particular, using so-called Gabor filter banks. The algorithm is evaluated on an OCTA image data set from $10$ eyes acquired by a Cirrus HD-OCT device. The segmentation outcomes received very good qualitative visual evaluation feedback and coincide well with device-specific values concerning vessel density. Concerning locality our segmentations are even more reliable and accurate. Therefore, we suggest the computation of adaptive local vessel density maps that allow straightforward analysis of retinal blood flow.
An amplified-target loss approach for photoreceptor layer segmentation in pathological OCT scans
Aug 02, 2019
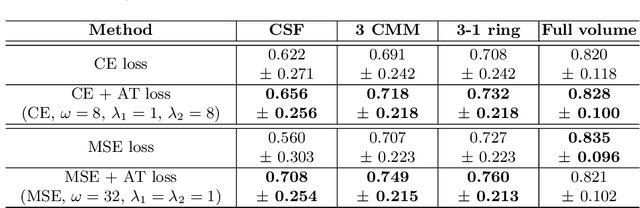


Segmenting anatomical structures such as the photoreceptor layer in retinal optical coherence tomography (OCT) scans is challenging in pathological scenarios. Supervised deep learning models trained with standard loss functions are usually able to characterize only the most common disease appeareance from a training set, resulting in suboptimal performance and poor generalization when dealing with unseen lesions. In this paper we propose to overcome this limitation by means of an augmented target loss function framework. We introduce a novel amplified-target loss that explicitly penalizes errors within the central area of the input images, based on the observation that most of the challenging disease appeareance is usually located in this area. We experimentally validated our approach using a data set with OCT scans of patients with macular diseases. We observe increased performance compared to the models that use only the standard losses. Our proposed loss function strongly supports the segmentation model to better distinguish photoreceptors in highly pathological scenarios.
Using CycleGANs for effectively reducing image variability across OCT devices and improving retinal fluid segmentation
Jan 25, 2019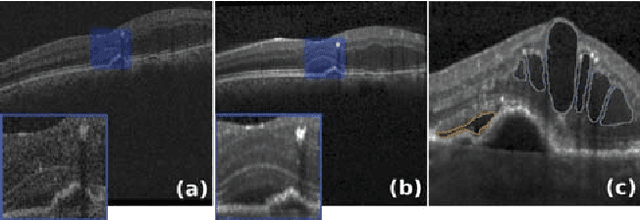

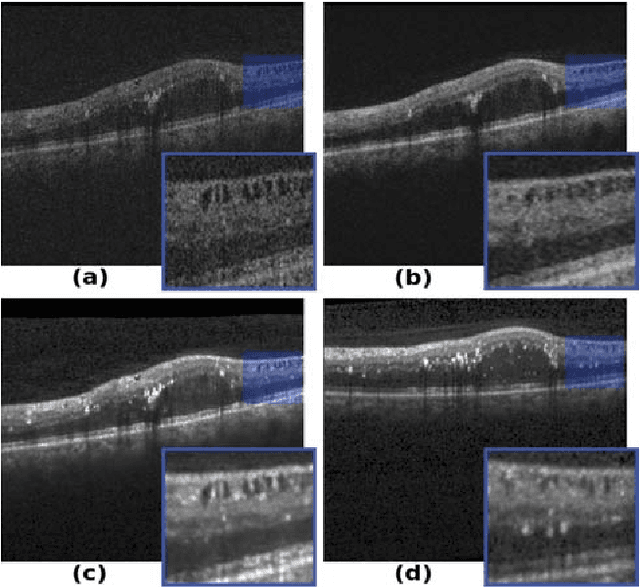
Optical coherence tomography (OCT) has become the most important imaging modality in ophthalmology. A substantial amount of research has recently been devoted to the development of machine learning (ML) models for the identification and quantification of pathological features in OCT images. Among the several sources of variability the ML models have to deal with, a major factor is the acquisition device, which can limit the ML model's generalizability. In this paper, we propose to reduce the image variability across different OCT devices (Spectralis and Cirrus) by using CycleGAN, an unsupervised unpaired image transformation algorithm. The usefulness of this approach is evaluated in the setting of retinal fluid segmentation, namely intraretinal cystoid fluid (IRC) and subretinal fluid (SRF). First, we train a segmentation model on images acquired with a source OCT device. Then we evaluate the model on (1) source, (2) target and (3) transformed versions of the target OCT images. The presented transformation strategy shows an F1 score of 0.4 (0.51) for IRC (SRF) segmentations. Compared with traditional transformation approaches, this means an F1 score gain of 0.2 (0.12).
U2-Net: A Bayesian U-Net model with epistemic uncertainty feedback for photoreceptor layer segmentation in pathological OCT scans
Jan 23, 2019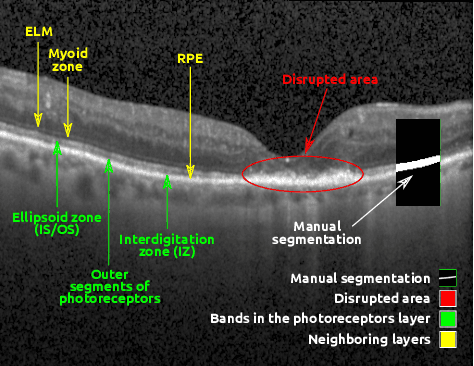
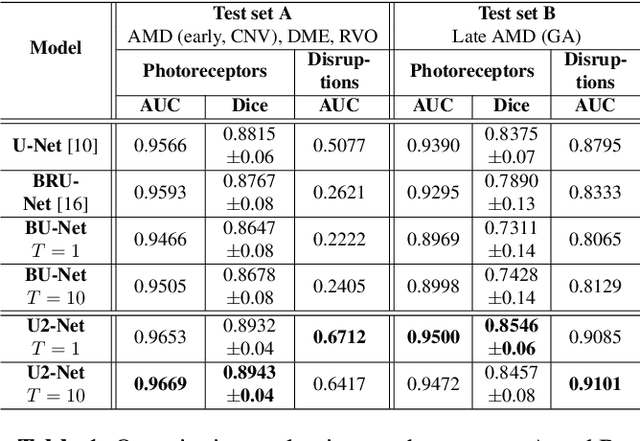
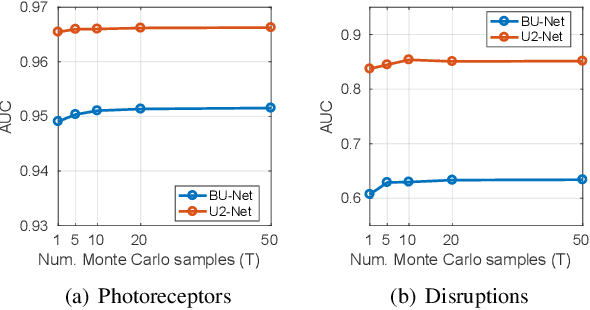
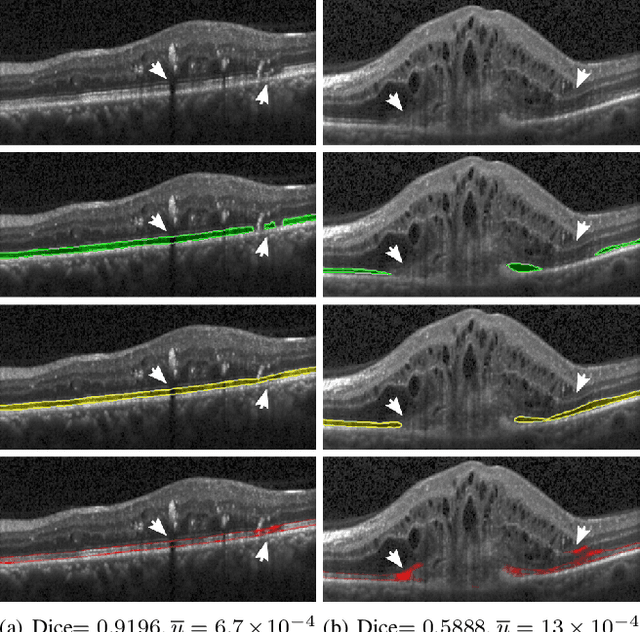
In this paper, we introduce a Bayesian deep learning based model for segmenting the photoreceptor layer in pathological OCT scans. Our architecture provides accurate segmentations of the photoreceptor layer and produces pixel-wise epistemic uncertainty maps that highlight potential areas of pathologies or segmentation errors. We empirically evaluated this approach in two sets of pathological OCT scans of patients with age-related macular degeneration, retinal vein oclussion and diabetic macular edema, improving the performance of the baseline U-Net both in terms of the Dice index and the area under the precision/recall curve. We also observed that the uncertainty estimates were inversely correlated with the model performance, underlying its utility for highlighting areas where manual inspection/correction might be needed.
* Accepted for publication at IEEE International Symposium on Biomedical Imaging (ISBI) 2019
On orthogonal projections for dimension reduction and applications in variational loss functions for learning problems
Jan 22, 2019
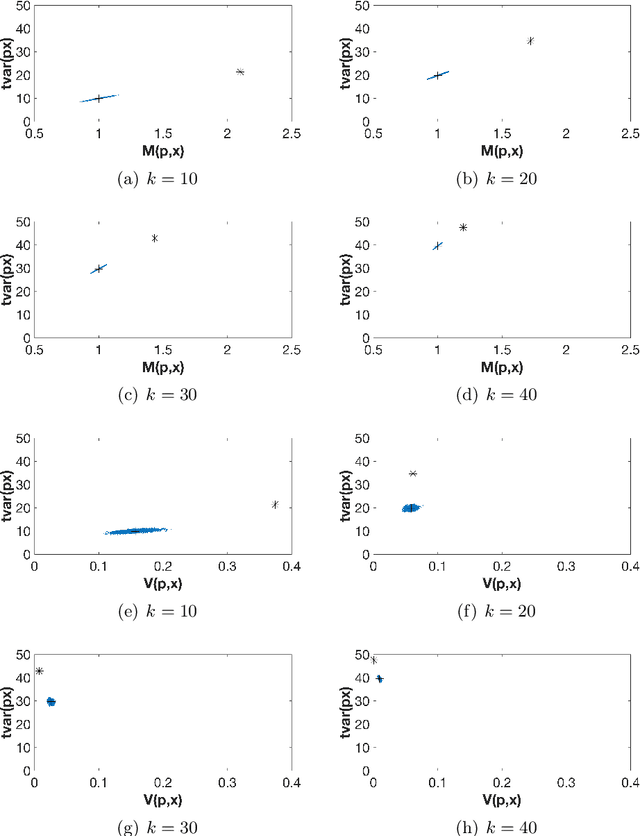
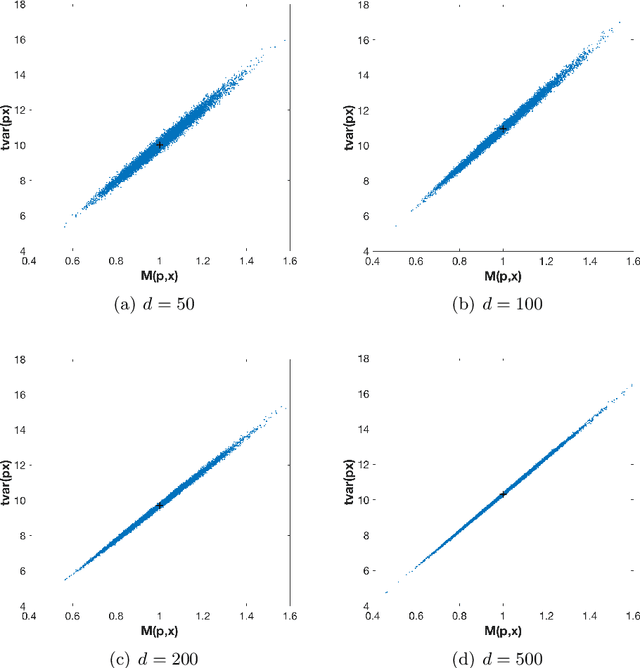
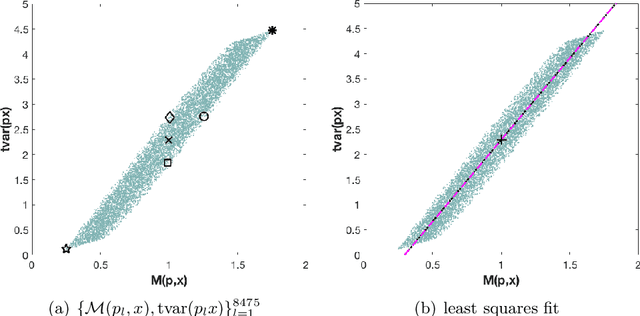
The use of orthogonal projections on high-dimensional input and target data in learning frameworks is studied. First, we investigate the relations between two standard objectives in dimension reduction, maximizing variance and preservation of pairwise relative distances. The derivation of their asymptotic correlation and numerical experiments tell that a projection usually cannot satisfy both objectives. In a standard classification problem we determine projections on the input data that balance them and compare subsequent results. Next, we extend our application of orthogonal projections to deep learning frameworks. We introduce new variational loss functions that enable integration of additional information via transformations and projections of the target data. In two supervised learning problems, clinical image segmentation and music information classification, the application of the proposed loss functions increase the accuracy.
Unsupervised Identification of Disease Marker Candidates in Retinal OCT Imaging Data
Oct 31, 2018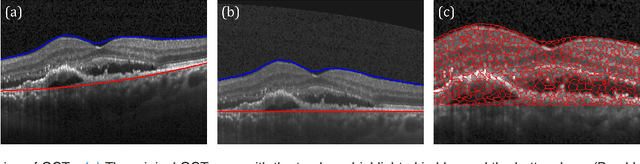
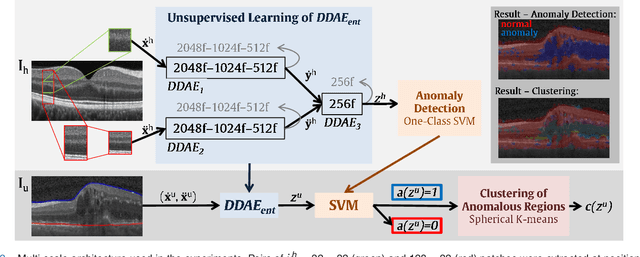
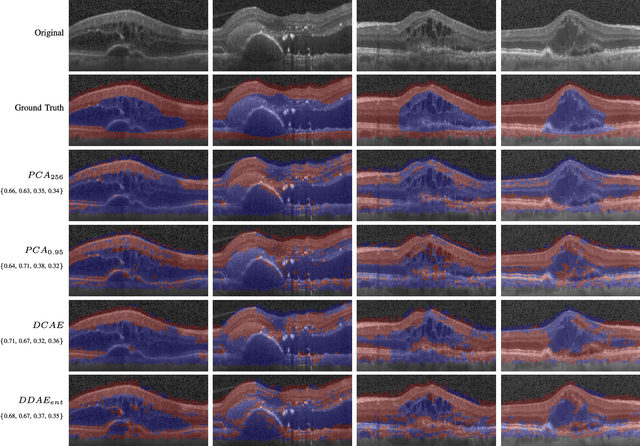
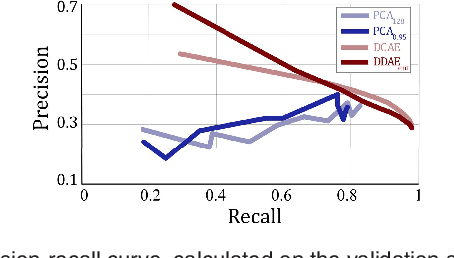
The identification and quantification of markers in medical images is critical for diagnosis, prognosis, and disease management. Supervised machine learning enables the detection and exploitation of findings that are known a priori after annotation of training examples by experts. However, supervision does not scale well, due to the amount of necessary training examples, and the limitation of the marker vocabulary to known entities. In this proof-of-concept study, we propose unsupervised identification of anomalies as candidates for markers in retinal Optical Coherence Tomography (OCT) imaging data without a constraint to a priori definitions. We identify and categorize marker candidates occurring frequently in the data, and demonstrate that these markers show predictive value in the task of detecting disease. A careful qualitative analysis of the identified data driven markers reveals how their quantifiable occurrence aligns with our current understanding of disease course, in early- and late age-related macular degeneration (AMD) patients. A multi-scale deep denoising autoencoder is trained on healthy images, and a one-class support vector machine identifies anomalies in new data. Clustering in the anomalies identifies stable categories. Using these markers to classify healthy-, early AMD- and late AMD cases yields an accuracy of 81.40%. In a second binary classification experiment on a publicly available data set (healthy vs. intermediate AMD) the model achieves an area under the ROC curve of 0.944.
Identifying and Categorizing Anomalies in Retinal Imaging Data
Dec 02, 2016
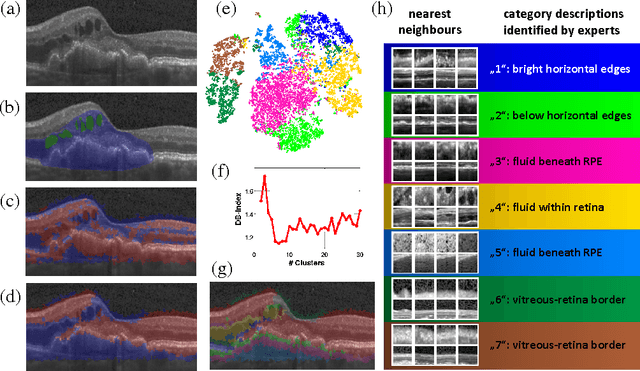
The identification and quantification of markers in medical images is critical for diagnosis, prognosis and management of patients in clinical practice. Supervised- or weakly supervised training enables the detection of findings that are known a priori. It does not scale well, and a priori definition limits the vocabulary of markers to known entities reducing the accuracy of diagnosis and prognosis. Here, we propose the identification of anomalies in large-scale medical imaging data using healthy examples as a reference. We detect and categorize candidates for anomaly findings untypical for the observed data. A deep convolutional autoencoder is trained on healthy retinal images. The learned model generates a new feature representation, and the distribution of healthy retinal patches is estimated by a one-class support vector machine. Results demonstrate that we can identify pathologic regions in images without using expert annotations. A subsequent clustering categorizes findings into clinically meaningful classes. In addition the learned features outperform standard embedding approaches in a classification task.