 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProdromal Diagnosis of Lewy Body Diseases Based on the Assessment of Graphomotor and Handwriting Difficulties
Jan 20, 2023To this date, studies focusing on the prodromal diagnosis of Lewy body diseases (LBDs) based on quantitative analysis of graphomotor and handwriting difficulties are missing. In this work, we enrolled 18 subjects diagnosed with possible or probable mild cognitive impairment with Lewy bodies (MCI-LB), 7 subjects having more than 50% probability of developing Parkinson's disease (PD), 21 subjects with both possible/probable MCI-LB and probability of PD > 50%, and 37 age- and gender-matched healthy controls (HC). Each participant performed three tasks: Archimedean spiral drawing (to quantify graphomotor difficulties), sentence writing task (to quantify handwriting difficulties), and pentagon copying test (to quantify cognitive decline). Next, we parameterized the acquired data by various temporal, kinematic, dynamic, spatial, and task-specific features. And finally, we trained classification models for each task separately as well as a model for their combination to estimate the predictive power of the features for the identification of LBDs. Using this approach we were able to identify prodromal LBDs with 74% accuracy and showed the promising potential of computerized objective and non-invasive diagnosis of LBDs based on the assessment of graphomotor and handwriting difficulties.
* Print ISBN 978-3-031-19744-4
Exploration of Various Fractional Order Derivatives in Parkinson's Disease Dysgraphia Analysis
Jan 20, 2023Parkinson's disease (PD) is a common neurodegenerative disorder with a prevalence rate estimated to 2.0% for people aged over 65 years. Cardinal motor symptoms of PD such as rigidity and bradykinesia affect the muscles involved in the handwriting process resulting in handwriting abnormalities called PD dysgraphia. Nowadays, online handwritten signal (signal with temporal information) acquired by the digitizing tablets is the most advanced approach of graphomotor difficulties analysis. Although the basic kinematic features were proved to effectively quantify the symptoms of PD dysgraphia, a recent research identified that the theory of fractional calculus can be used to improve the graphomotor difficulties analysis. Therefore, in this study, we follow up on our previous research, and we aim to explore the utilization of various approaches of fractional order derivative (FD) in the analysis of PD dysgraphia. For this purpose, we used the repetitive loops task from the Parkinson's disease handwriting database (PaHaW). Handwritten signals were parametrized by the kinematic features employing three FD approximations: Gr\"unwald-Letnikov's, Riemann-Liouville's, and Caputo's. Results of the correlation analysis revealed a significant relationship between the clinical state and the handwriting features based on the velocity. The extracted features by Caputo's FD approximation outperformed the rest of the analyzed FD approaches. This was also confirmed by the results of the classification analysis, where the best model trained by Caputo's handwriting features resulted in a balanced accuracy of 79.73% with a sensitivity of 83.78% and a specificity of 75.68%.
* Print ISBN 978-3-031-19744-4
Perceptual Features as Markers of Parkinson's Disease: The Issue of Clinical Interpretability
Mar 21, 2022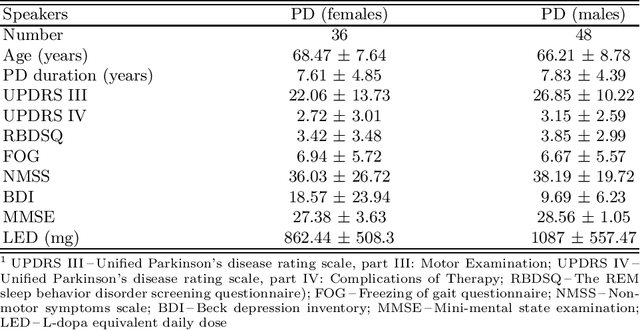
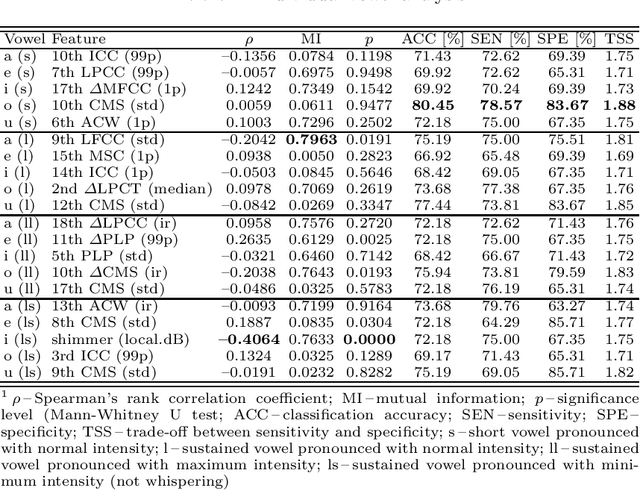
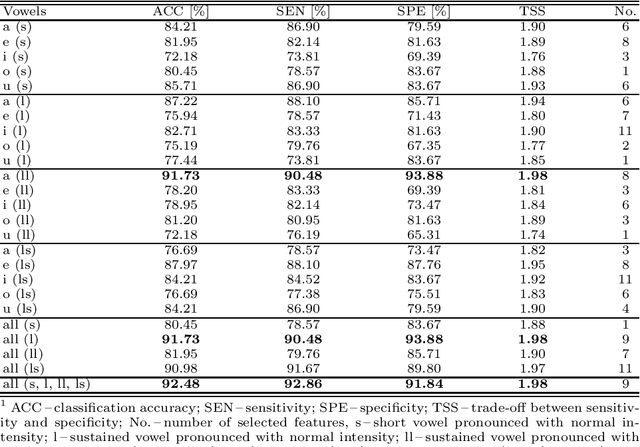

Up to 90% of patients with Parkinson's disease (PD) suffer from hypokinetic dysathria (HD) which is also manifested in the field of phonation. Clinical signs of HD like monoloudness, monopitch or hoarse voice are usually quantified by conventional clinical interpretable features (jitter, shimmer, harmonic-to-noise ratio, etc.). This paper provides large and robust insight into perceptual analysis of 5 Czech vowels of 84 PD patients and proves that despite the clinical inexplicability the perceptual features outperform the conventional ones, especially in terms of discrimination power (classification accuracy ACC = 92 %, sensitivity SEN = 93 %, specificity SPE = 92 %) and partial correlation with clinical scores like UPDRS (Unified Parkinson's disease rating scale), MMSE (Mini-mental state examination) or FOG (Freezing of gait questionnaire), where p < 0.0001.
* 8 pages, published in International Conference on NONLINEAR SPEECH PROCESSING, NOLISP 2015 jointly organized with the 25th Italian Workshop on Neural Networks, WIRN 2015, held at May 2015, Vietri sul Mare, Salerno, Italy
Identification of Hypokinetic Dysarthria Using Acoustic Analysis of Poem Recitation
Mar 18, 2022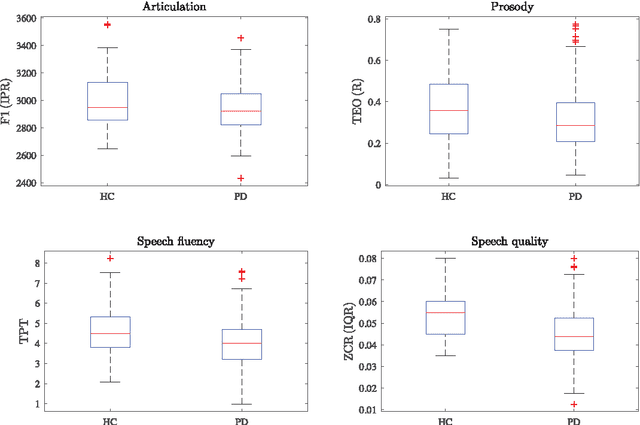

Up to 90 % of patients with Parkinson's disease (PD) suffer from hypokinetic dysarthria (HD). In this work, we analysed the power of conventional speech features quantifying imprecise articulation, dysprosody, speech dysfluency and speech quality deterioration extracted from a specialized poem recitation task to discriminate dysarthric and healthy speech. For this purpose, 152 speakers (53 healthy speakers, 99 PD patients) were examined. Only mildly strong correlation between speech features and clinical status of the speakers was observed. In the case of univariate classification analysis, sensitivity of 62.63% (imprecise articulation), 61.62% (dysprosody), 71.72% (speech dysfluency) and 59.60% (speech quality deterioration) was achieved. Multivariate classification analysis improved the classification performance. Sensitivity of 83.42% using only two features describing imprecise articulation and speech quality deterioration in HD was achieved. We showed the promising potential of the selected speech features and especially the use of poem recitation task to quantify and identify HD in PD.
Robust and Complex Approach of Pathological Speech Signal Analysis
Mar 17, 2022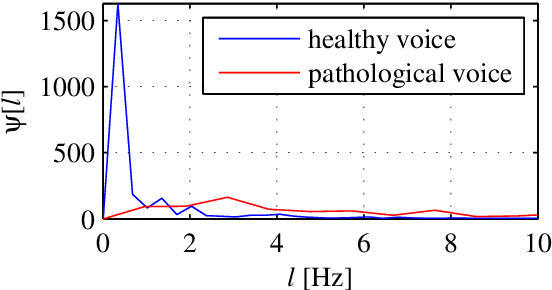

This paper presents a study of the approaches in the state-of-the-art in the field of pathological speech signal analysis with a special focus on parametrization techniques. It provides a description of 92 speech features where some of them are already widely used in this field of science and some of them have not been tried yet (they come from different areas of speech signal processing like speech recognition or coding). As an original contribution, this work introduces 36 completely new pathological voice measures based on modulation spectra, inferior colliculus coefficients, bicepstrum, sample and approximate entropy and empirical mode decomposition. The significance of these features was tested on 3 (English, Spanish and Czech) pathological voice databases with respect to classification accuracy, sensitivity and specificity.
* 41 pages, published in Neurocomputing, Volume 167, 2015, Pages 94-111, ISSN 0925-2312
Assessing Progress of Parkinson s Disease Using Acoustic Analysis of Phonation
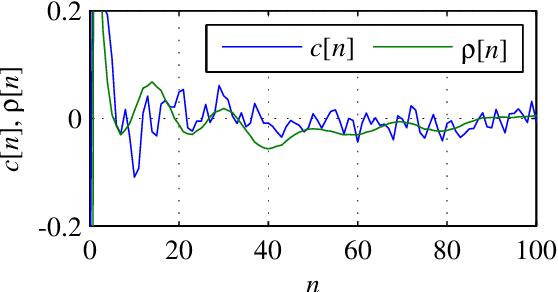
Mar 17, 2022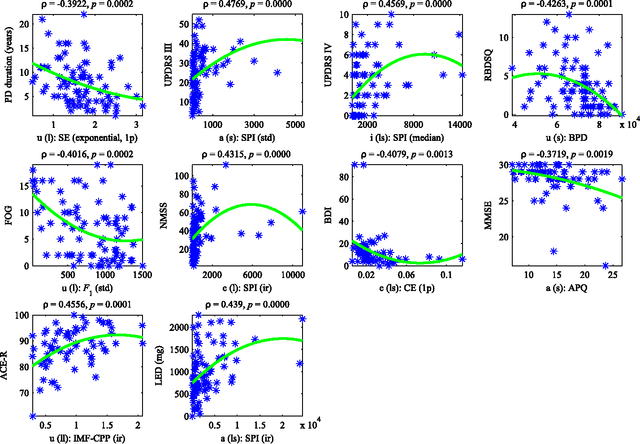
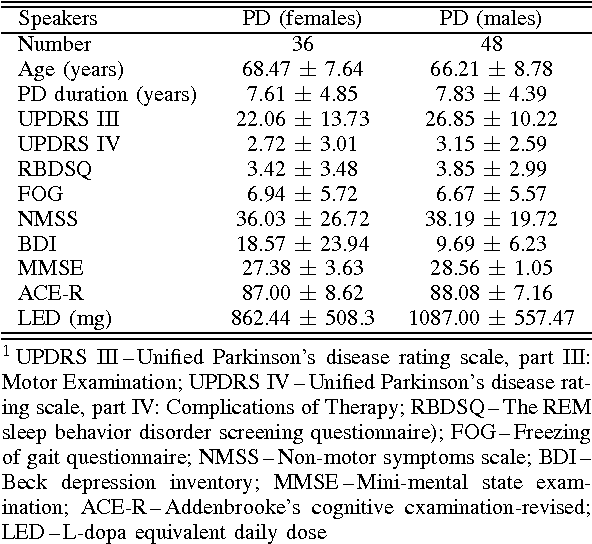
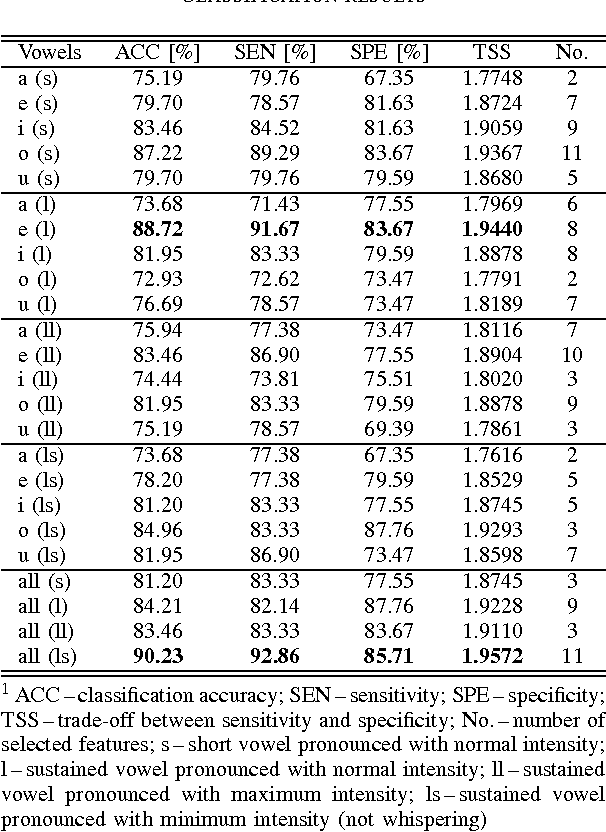
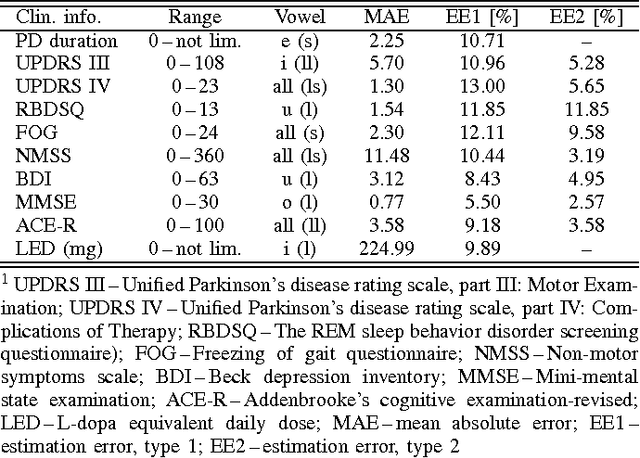
This paper deals with a complex acoustic analysis of phonation in patients with Parkinson's disease (PD) with a special focus on estimation of disease progress that is described by 7 different clinical scales ,e. g. Unified Parkinson's disease rating scale or Beck depression inventory. The analysis is based on parametrization of 5 Czech vowels pronounced by 84 PD patients. Using classification and regression trees we estimated all clinical scores with maximal error lower or equal to 13 %. Best estimation was observed in the case of Mini-mental state examination (MAE = 0.77, estimation error 5.50 %. Finally, we proposed a binary classification based on random forests that is able to identify Parkinson's disease with sensitivity SEN = 92.86 % (SPE = 85.71 %). The parametrization process was based on extraction of 107 speech features quantifying different clinical signs of hypokinetic dysarthria present in PD.
* 8 pages published in the 4th IEEE IWOBI 2015, pp. 115-122, 10-12 June, 2015 Donostia-San Sebastian. ISBN: 978-84-606-8733-7
The reliability of a deep learning model in clinical out-of-distribution MRI data: a multicohort study
Nov 01, 2019



Deep learning (DL) methods have in recent years yielded impressive results in medical imaging, with the potential to function as clinical aid to radiologists. However, DL models in medical imaging are often trained on public research cohorts with images acquired with a single scanner or with strict protocol harmonization, which is not representative of a clinical setting. The aim of this study was to investigate how well a DL model performs in unseen clinical data sets---collected with different scanners, protocols and disease populations---and whether more heterogeneous training data improves generalization. In total, 3117 MRI scans of brains from multiple dementia research cohorts and memory clinics, that had been visually rated by a neuroradiologist according to Scheltens' scale of medial temporal atrophy (MTA), were included in this study. By training multiple versions of a convolutional neural network on different subsets of this data to predict MTA ratings, we assessed the impact of including images from a wider distribution during training had on performance in external memory clinic data. Our results showed that our model generalized well to data sets acquired with similar protocols as the training data, but substantially worse in clinical cohorts with visibly different tissue contrasts in the images. This implies that future DL studies investigating performance in out-of-distribution (OOD) MRI data need to assess multiple external cohorts for reliable results. Further, by including data from a wider range of scanners and protocols the performance improved in OOD data, which suggests that more heterogeneous training data makes the model generalize better. To conclude, this is the most comprehensive study to date investigating the domain shift in deep learning on MRI data, and we advocate rigorous evaluation of DL models on clinical data prior to being certified for deployment.