 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRedistributor: Transforming Empirical Data Distributions
Oct 25, 2022



We present an algorithm and package, Redistributor, which forces a collection of scalar samples to follow a desired distribution. When given independent and identically distributed samples of some random variable $S$ and the continuous cumulative distribution function of some desired target $T$, it provably produces a consistent estimator of the transformation $R$ which satisfies $R(S)=T$ in distribution. As the distribution of $S$ or $T$ may be unknown, we also include algorithms for efficiently estimating these distributions from samples. This allows for various interesting use cases in image processing, where Redistributor serves as a remarkably simple and easy-to-use tool that is capable of producing visually appealing results. The package is implemented in Python and is optimized to efficiently handle large data sets, making it also suitable as a preprocessing step in machine learning. The source code is available at https://gitlab.com/paloha/redistributor.
Adaptive, Distribution-Free Prediction Intervals for Deep Neural Networks
May 25, 2019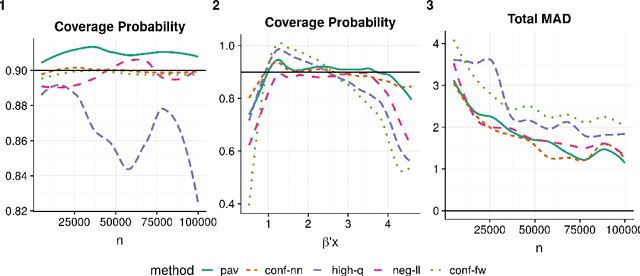
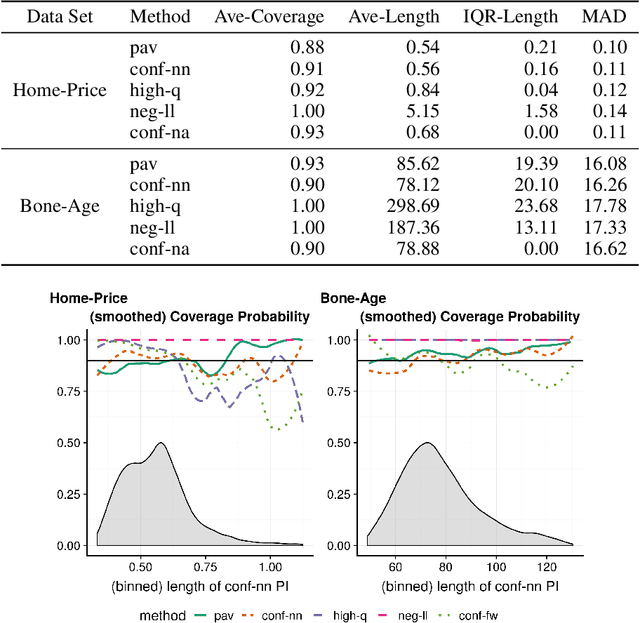
This paper addresses the problem of assessing the variability of predictions from deep neural networks. There is a growing literature on using and improving the predictive accuracy of deep networks, but a concomitant improvement in the quantification of their uncertainty is lacking. We provide a prediction interval network (PI-Network) which is a transparent, tractable modification of the standard predictive loss used to train deep networks. The PI-Network outputs three values instead of a single point estimate and optimizes a loss function inspired by quantile regression. We go beyond merely motivating the construction of these networks and provide two prediction interval methods with provable, finite sample coverage guarantees without any assumptions on the underlying distribution from which our data is drawn. We only require that the observations are independent and identically distributed. Furthermore, our intervals adapt to heteroskedasticity and asymmetry in the conditional distribution of the response given the covariates. The first method leverages the conformal inference framework and provides average coverage. The second method provides a new, stronger guarantee by conditioning on the observed data. Lastly, our loss function does not compromise the predictive accuracy of the network like other prediction interval methods. We demonstrate the ease of use of the PI-Network as well as its improvements over other methods on both simulated and real data. As the PI-Network can be used with a host of deep learning methods with only minor modifications, its use should become standard practice, much like reporting standard errors along with mean estimates.