 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptive, Distribution-Free Prediction Intervals for Deep Neural Networks
May 25, 2019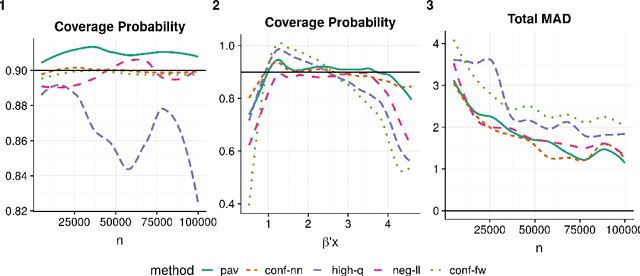
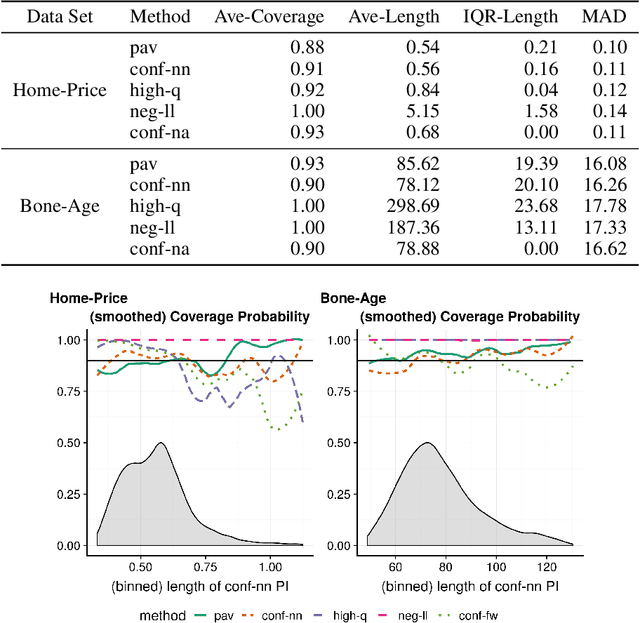
This paper addresses the problem of assessing the variability of predictions from deep neural networks. There is a growing literature on using and improving the predictive accuracy of deep networks, but a concomitant improvement in the quantification of their uncertainty is lacking. We provide a prediction interval network (PI-Network) which is a transparent, tractable modification of the standard predictive loss used to train deep networks. The PI-Network outputs three values instead of a single point estimate and optimizes a loss function inspired by quantile regression. We go beyond merely motivating the construction of these networks and provide two prediction interval methods with provable, finite sample coverage guarantees without any assumptions on the underlying distribution from which our data is drawn. We only require that the observations are independent and identically distributed. Furthermore, our intervals adapt to heteroskedasticity and asymmetry in the conditional distribution of the response given the covariates. The first method leverages the conformal inference framework and provides average coverage. The second method provides a new, stronger guarantee by conditioning on the observed data. Lastly, our loss function does not compromise the predictive accuracy of the network like other prediction interval methods. We demonstrate the ease of use of the PI-Network as well as its improvements over other methods on both simulated and real data. As the PI-Network can be used with a host of deep learning methods with only minor modifications, its use should become standard practice, much like reporting standard errors along with mean estimates.
The Oracle of DLphi
Jan 27, 2019We present a novel technique based on deep learning and set theory which yields exceptional classification and prediction results. Having access to a sufficiently large amount of labelled training data, our methodology is capable of predicting the labels of the test data almost always even if the training data is entirely unrelated to the test data. In other words, we prove in a specific setting that as long as one has access to enough data points, the quality of the data is irrelevant.