 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHigh-Dimensional Distribution Generation Through Deep Neural Networks
Aug 25, 2021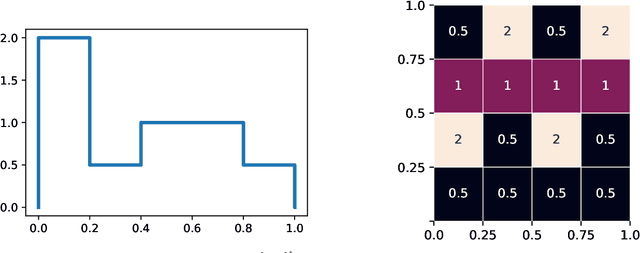
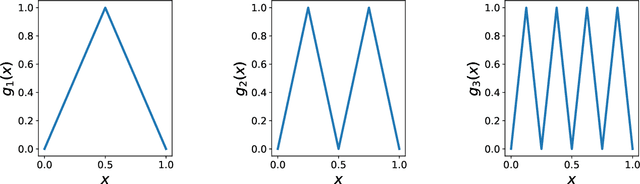
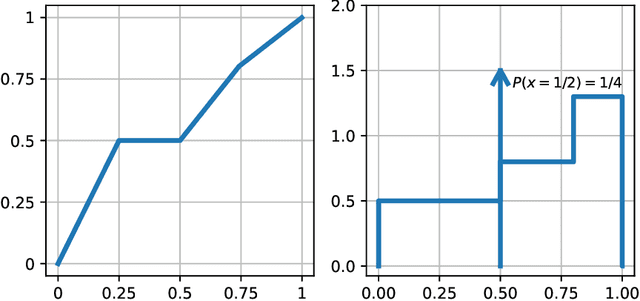
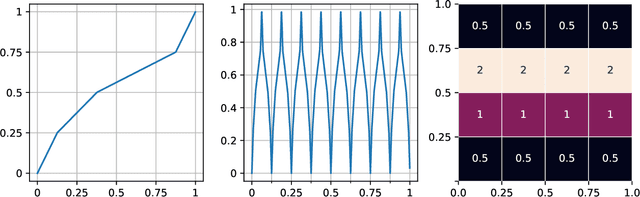
We show that every $d$-dimensional probability distribution of bounded support can be generated through deep ReLU networks out of a $1$-dimensional uniform input distribution. What is more, this is possible without incurring a cost - in terms of approximation error measured in Wasserstein-distance - relative to generating the $d$-dimensional target distribution from $d$ independent random variables. This is enabled by a vast generalization of the space-filling approach discovered in (Bailey & Telgarsky, 2018). The construction we propose elicits the importance of network depth in driving the Wasserstein distance between the target distribution and its neural network approximation to zero. Finally, we find that, for histogram target distributions, the number of bits needed to encode the corresponding generative network equals the fundamental limit for encoding probability distributions as dictated by quantization theory.
Constructive Universal High-Dimensional Distribution Generation through Deep ReLU Networks
Jun 30, 2020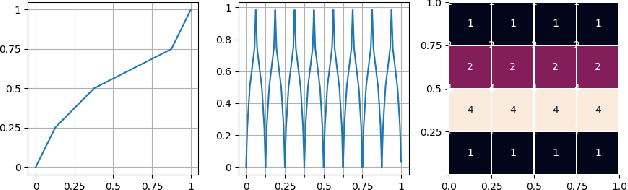

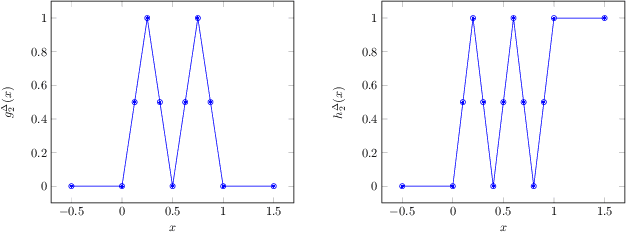
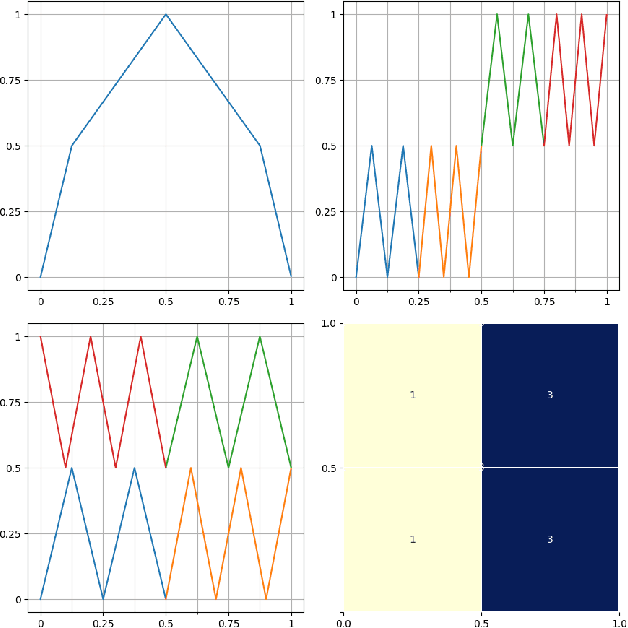
We present an explicit deep neural network construction that transforms uniformly distributed one-dimensional noise into an arbitrarily close approximation of any two-dimensional Lipschitz-continuous target distribution. The key ingredient of our design is a generalization of the "space-filling" property of sawtooth functions discovered in (Bailey & Telgarsky, 2018). We elicit the importance of depth - in our neural network construction - in driving the Wasserstein distance between the target distribution and the approximation realized by the network to zero. An extension to output distributions of arbitrary dimension is outlined. Finally, we show that the proposed construction does not incur a cost - in terms of error measured in Wasserstein-distance - relative to generating $d$-dimensional target distributions from $d$ independent random variables.
Deep Neural Network Approximation Theory
Jan 08, 2019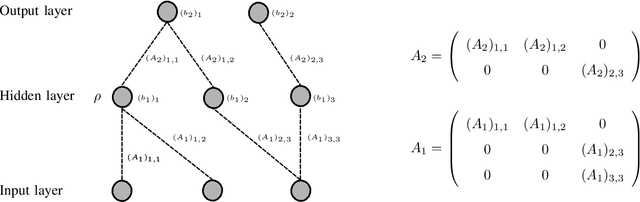
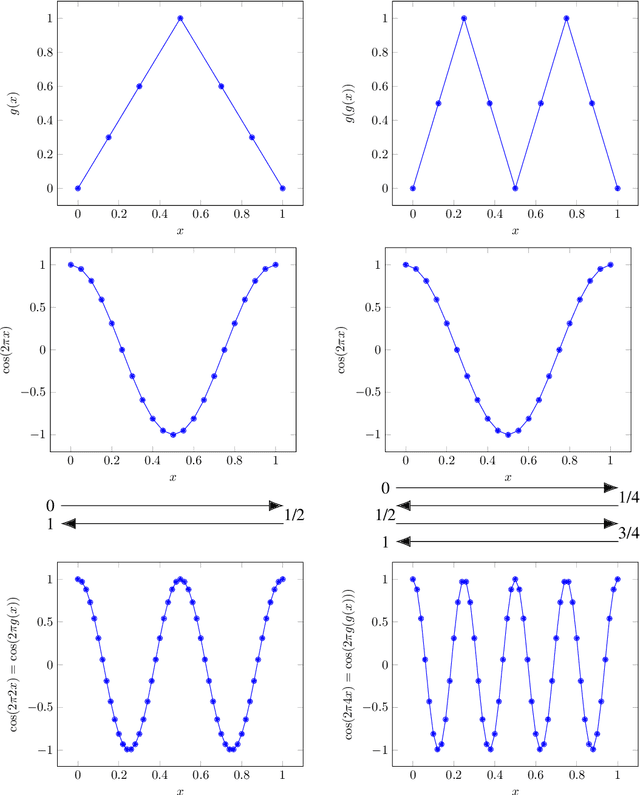
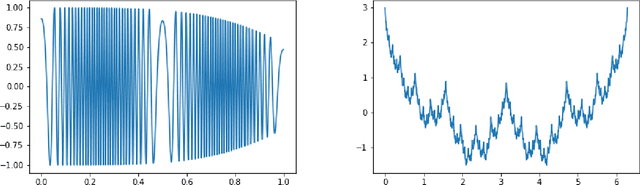
Deep neural networks have become state-of-the-art technology for a wide range of practical machine learning tasks such as image classification, handwritten digit recognition, speech recognition, or game intelligence. This paper develops the fundamental limits of learning in deep neural networks by characterizing what is possible if no constraints on the learning algorithm and the amount of training data are imposed. Concretely, we consider information-theoretically optimal approximation through deep neural networks with the guiding theme being a relation between the complexity of the function (class) to be approximated and the complexity of the approximating network in terms of connectivity and memory requirements for storing the network topology and the associated quantized weights. The theory we develop educes remarkable universality properties of deep networks. Specifically, deep networks are optimal approximants for vastly different function classes such as affine systems and Gabor systems. This universality is afforded by a concurrent invariance property of deep networks to time-shifts, scalings, and frequency-shifts. In addition, deep networks provide exponential approximation accuracy i.e., the approximation error decays exponentially in the number of non-zero weights in the network of vastly different functions such as the squaring operation, multiplication, polynomials, sinusoidal functions, general smooth functions, and even one-dimensional oscillatory textures and fractal functions such as the Weierstrass function, both of which do not have any known methods achieving exponential approximation accuracy. In summary, deep neural networks provide information-theoretically optimal approximation of a very wide range of functions and function classes used in mathematical signal processing.
The universal approximation power of finite-width deep ReLU networks
Jun 05, 2018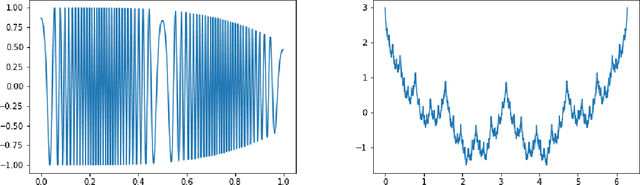
We show that finite-width deep ReLU neural networks yield rate-distortion optimal approximation (B\"olcskei et al., 2018) of polynomials, windowed sinusoidal functions, one-dimensional oscillatory textures, and the Weierstrass function, a fractal function which is continuous but nowhere differentiable. Together with their recently established universal approximation property of affine function systems (B\"olcskei et al., 2018), this shows that deep neural networks approximate vastly different signal structures generated by the affine group, the Weyl-Heisenberg group, or through warping, and even certain fractals, all with approximation error decaying exponentially in the number of neurons. We also prove that in the approximation of sufficiently smooth functions finite-width deep networks require strictly smaller connectivity than finite-depth wide networks.
Convolutional Recurrent Neural Networks for Electrocardiogram Classification
Apr 09, 2018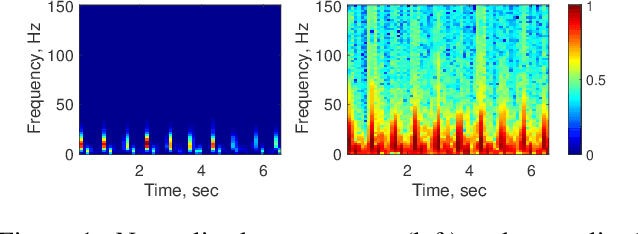
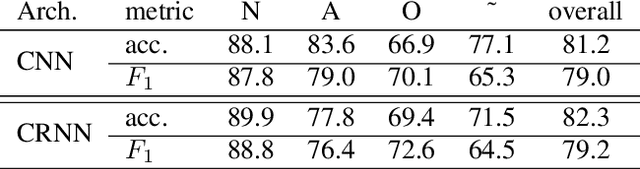
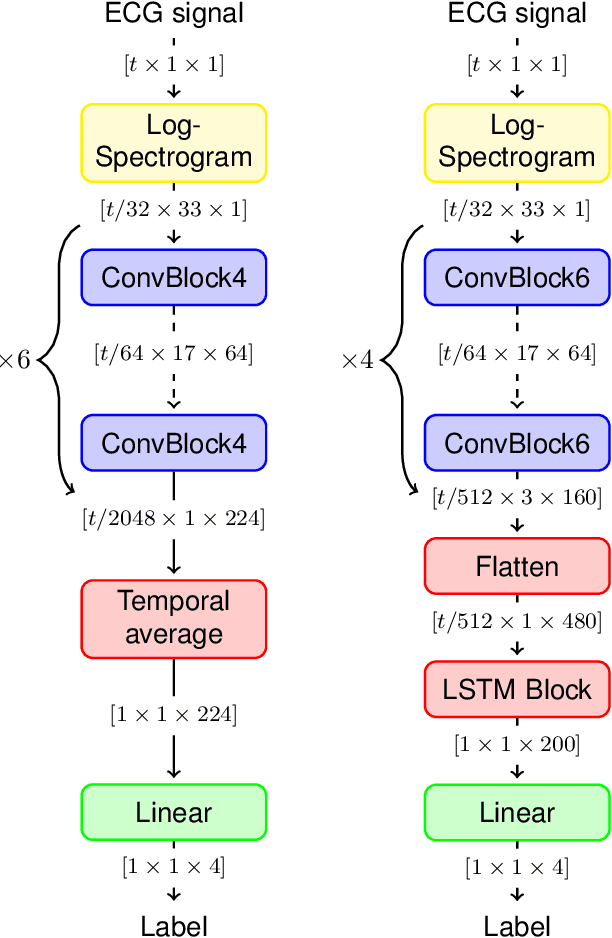
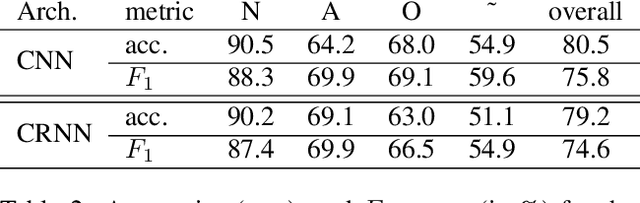
We propose two deep neural network architectures for classification of arbitrary-length electrocardiogram (ECG) recordings and evaluate them on the atrial fibrillation (AF) classification data set provided by the PhysioNet/CinC Challenge 2017. The first architecture is a deep convolutional neural network (CNN) with averaging-based feature aggregation across time. The second architecture combines convolutional layers for feature extraction with long-short term memory (LSTM) layers for temporal aggregation of features. As a key ingredient of our training procedure we introduce a simple data augmentation scheme for ECG data and demonstrate its effectiveness in the AF classification task at hand. The second architecture was found to outperform the first one, obtaining an $F_1$ score of $82.1$% on the hidden challenge testing set.
Faster Coordinate Descent via Adaptive Importance Sampling
Mar 07, 2017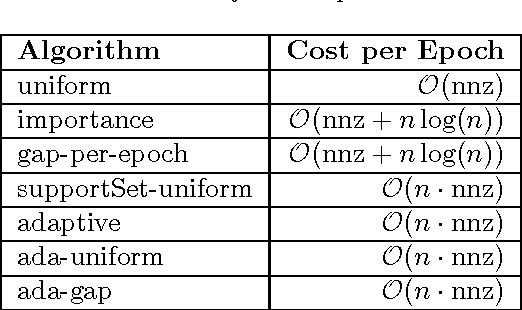
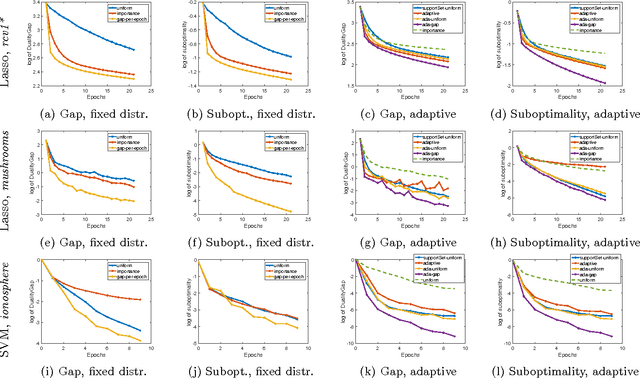
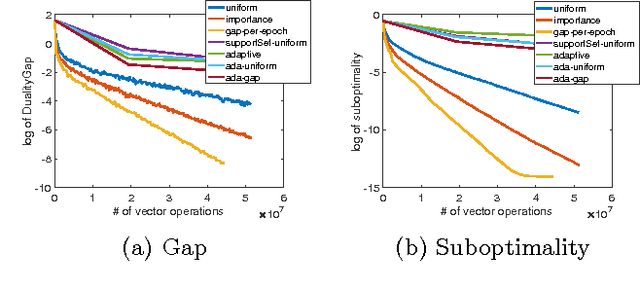
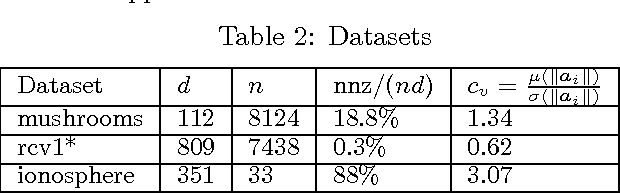
Coordinate descent methods employ random partial updates of decision variables in order to solve huge-scale convex optimization problems. In this work, we introduce new adaptive rules for the random selection of their updates. By adaptive, we mean that our selection rules are based on the dual residual or the primal-dual gap estimates and can change at each iteration. We theoretically characterize the performance of our selection rules and demonstrate improvements over the state-of-the-art, and extend our theory and algorithms to general convex objectives. Numerical evidence with hinge-loss support vector machines and Lasso confirm that the practice follows the theory.