 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHigh-Dimensional Distribution Generation Through Deep Neural Networks
Paper and Code
Aug 25, 2021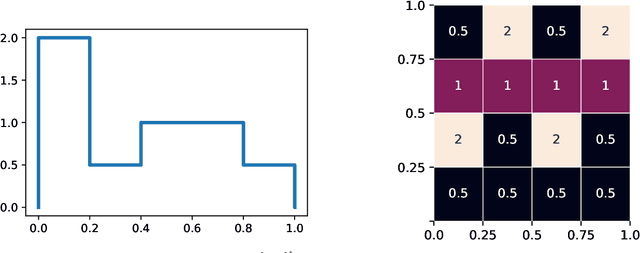
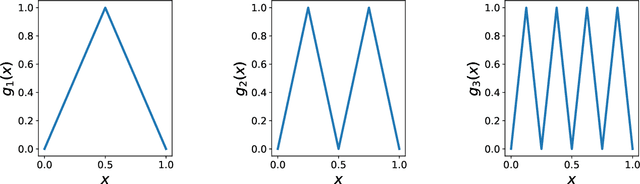
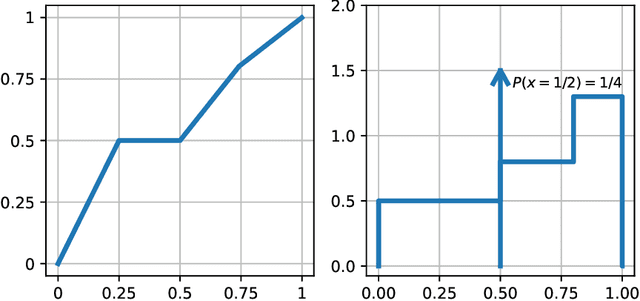
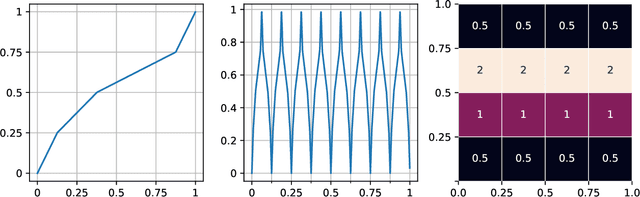
We show that every $d$-dimensional probability distribution of bounded support can be generated through deep ReLU networks out of a $1$-dimensional uniform input distribution. What is more, this is possible without incurring a cost - in terms of approximation error measured in Wasserstein-distance - relative to generating the $d$-dimensional target distribution from $d$ independent random variables. This is enabled by a vast generalization of the space-filling approach discovered in (Bailey & Telgarsky, 2018). The construction we propose elicits the importance of network depth in driving the Wasserstein distance between the target distribution and its neural network approximation to zero. Finally, we find that, for histogram target distributions, the number of bits needed to encode the corresponding generative network equals the fundamental limit for encoding probability distributions as dictated by quantization theory.