 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeneration of Consistent Sets of Multi-Label Classification Rules with a Multi-Objective Evolutionary Algorithm
Mar 27, 2020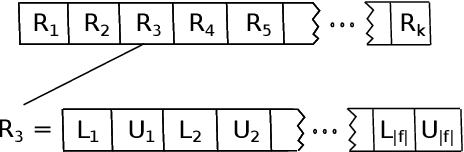
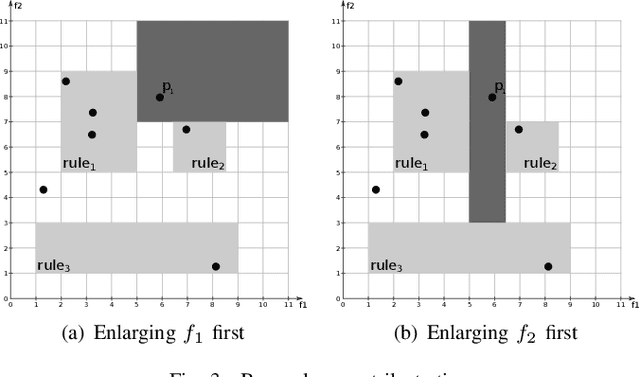
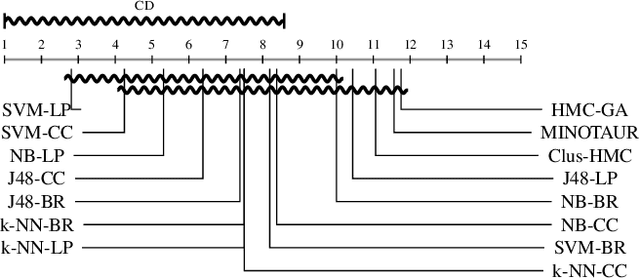
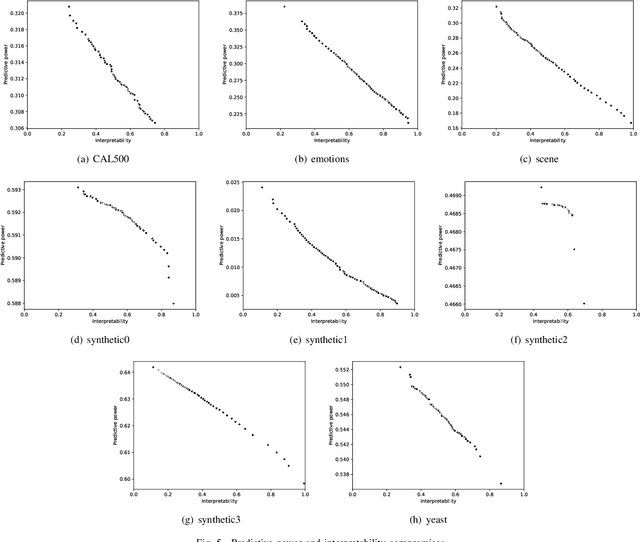
Multi-label classification consists in classifying an instance into two or more classes simultaneously. It is a very challenging task present in many real-world applications, such as classification of biology, image, video, audio, and text. Recently, the interest in interpretable classification models has grown, partially as a consequence of regulations such as the General Data Protection Regulation. In this context, we propose a multi-objective evolutionary algorithm that generates multiple rule-based multi-label classification models, allowing users to choose among models that offer different compromises between predictive power and interpretability. An important contribution of this work is that different from most algorithms, which usually generate models based on lists (ordered collections) of rules, our algorithm generates models based on sets (unordered collections) of rules, increasing interpretability. Also, by employing a conflict avoidance algorithm during the rule-creation, every rule within a given model is guaranteed to be consistent with every other rule in the same model. Thus, no conflict resolution strategy is required, evolving simpler models. We conducted experiments on synthetic and real-world datasets and compared our results with state-of-the-art algorithms in terms of predictive performance (F-Score) and interpretability (model size), and demonstrate that our best models had comparable F-Score and smaller model sizes.
Preventing the Generation of Inconsistent Sets of Classification Rules
Aug 23, 2019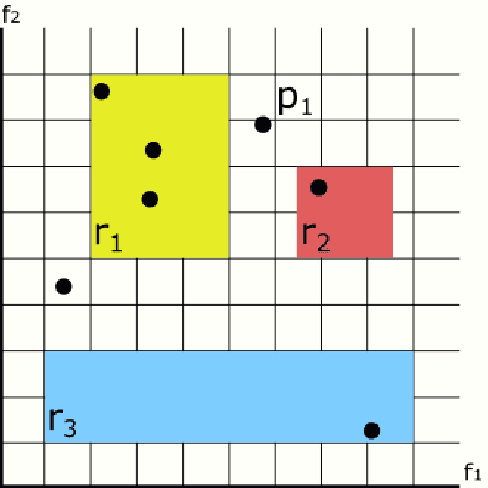
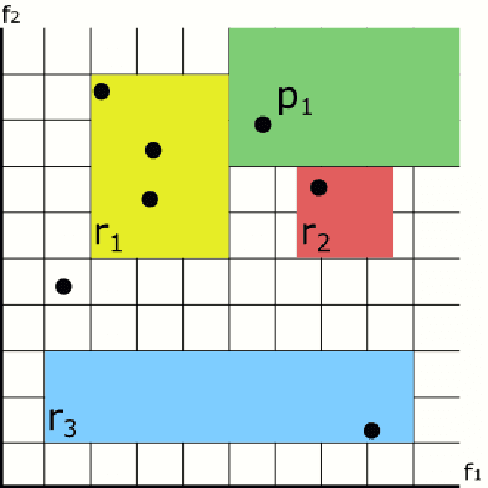
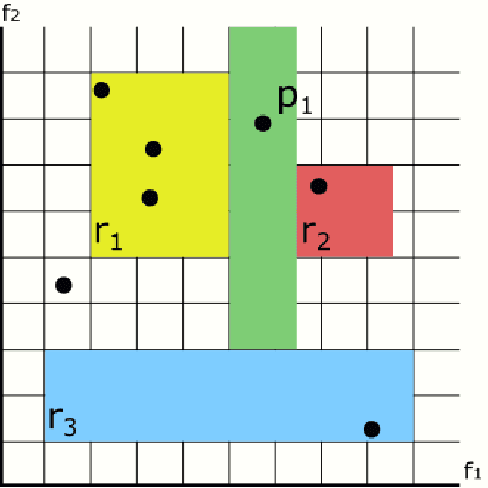
In recent years, the interest in interpretable classification models has grown. One of the proposed ways to improve the interpretability of a rule-based classification model is to use sets (unordered collections) of rules, instead of lists (ordered collections) of rules. One of the problems associated with sets is that multiple rules may cover a single instance, but predict different classes for it, thus requiring a conflict resolution strategy. In this work, we propose two algorithms capable of finding feature-space regions inside which any created rule would be consistent with the already existing rules, preventing inconsistencies from arising. Our algorithms do not generate classification models, but are instead meant to enhance algorithms that do so, such as Learning Classifier Systems. Both algorithms are described and analyzed exclusively from a theoretical perspective, since we have not modified a model-generating algorithm to incorporate our proposed solutions yet. This work presents the novelty of using conflict avoidance strategies instead of conflict resolution strategies.