 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Historical Context for Data Streams
Oct 18, 2023Machine learning from data streams is an active and growing research area. Research on learning from streaming data typically makes strict assumptions linked to computational resource constraints, including requirements for stream mining algorithms to inspect each instance not more than once and be ready to give a prediction at any time. Here we review the historical context of data streams research placing the common assumptions used in machine learning over data streams in their historical context.
Fairness-aware machine learning: a perspective
Aug 02, 2017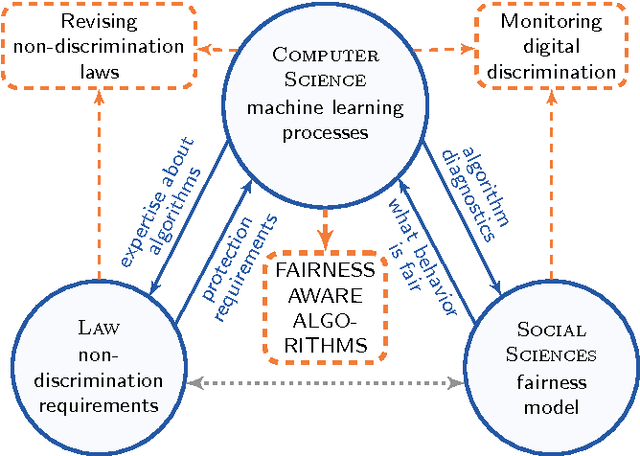
Algorithms learned from data are increasingly used for deciding many aspects in our life: from movies we see, to prices we pay, or medicine we get. Yet there is growing evidence that decision making by inappropriately trained algorithms may unintentionally discriminate people. For example, in automated matching of candidate CVs with job descriptions, algorithms may capture and propagate ethnicity related biases. Several repairs for selected algorithms have already been proposed, but the underlying mechanisms how such discrimination happens from the computational perspective are not yet scientifically understood. We need to develop theoretical understanding how algorithms may become discriminatory, and establish fundamental machine learning principles for prevention. We need to analyze machine learning process as a whole to systematically explain the roots of discrimination occurrence, which will allow to devise global machine learning optimization criteria for guaranteed prevention, as opposed to pushing empirical constraints into existing algorithms case-by-case. As a result, the state-of-the-art will advance from heuristic repairing, to proactive and theoretically supported prevention. This is needed not only because law requires to protect vulnerable people. Penetration of big data initiatives will only increase, and computer science needs to provide solid explanations and accountability to the public, before public concerns lead to unnecessarily restrictive regulations against machine learning.
A note on adjusting $R^2$ for using with cross-validation
May 05, 2016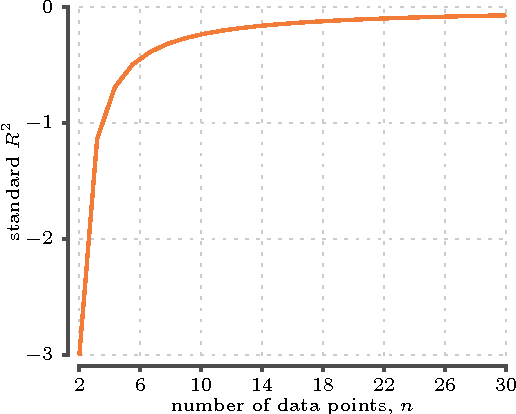
We show how to adjust the coefficient of determination ($R^2$) when used for measuring predictive accuracy via leave-one-out cross-validation.
Optimal estimates for short horizon travel time prediction in urban areas
Aug 10, 2015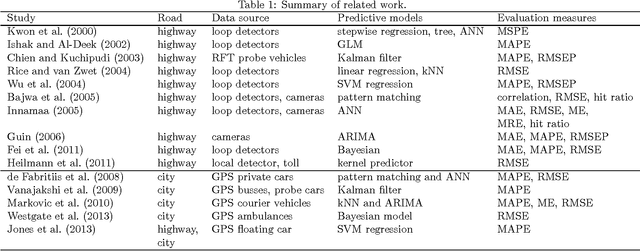
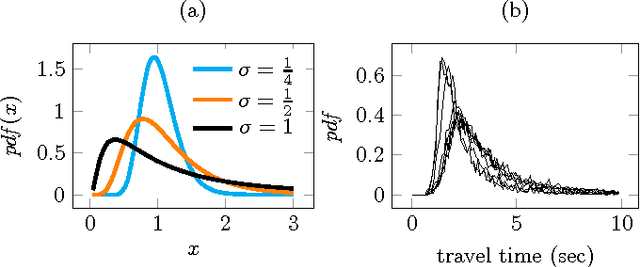
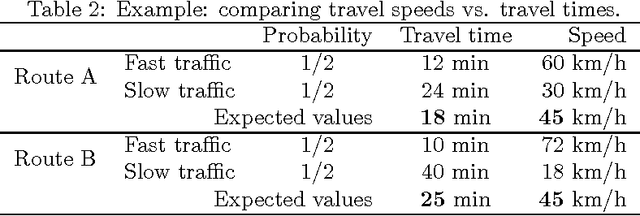
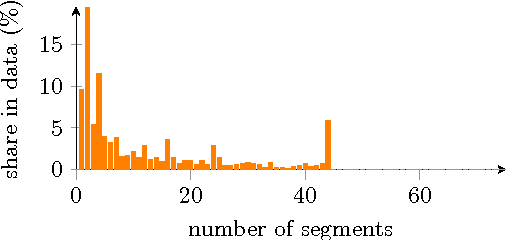
Increasing popularity of mobile route planning applications based on GPS technology provides opportunities for collecting traffic data in urban environments. One of the main challenges for travel time estimation and prediction in such a setting is how to aggregate data from vehicles that have followed different routes, and predict travel time for other routes of interest. One approach is to predict travel times for route segments, and sum those estimates to obtain a prediction for the whole route. We study how to obtain optimal predictions in this scenario. It appears that the optimal estimate, minimizing the expected mean absolute error, is a combination of the mean and the median travel times on each segment, where the combination function depends on the number of segments in the route of interest. We present a methodology for obtaining such predictions, and demonstrate its effectiveness with a case study using travel time data from a district of St. Petersburg collected over one year. The proposed methodology can be applied for real-time prediction of expected travel times in an urban road network.
Predicting respiratory motion for real-time tumour tracking in radiotherapy
Aug 04, 2015
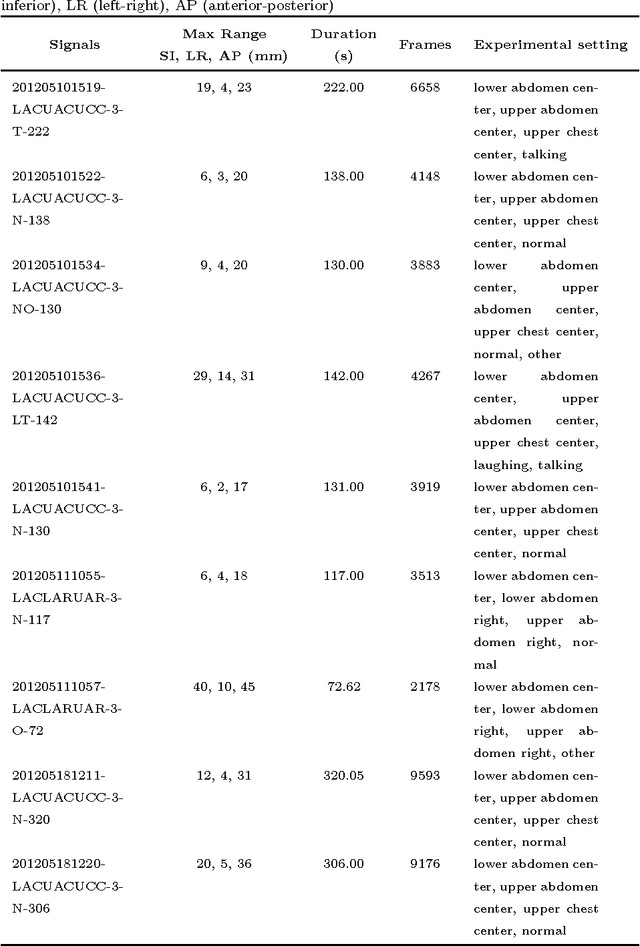
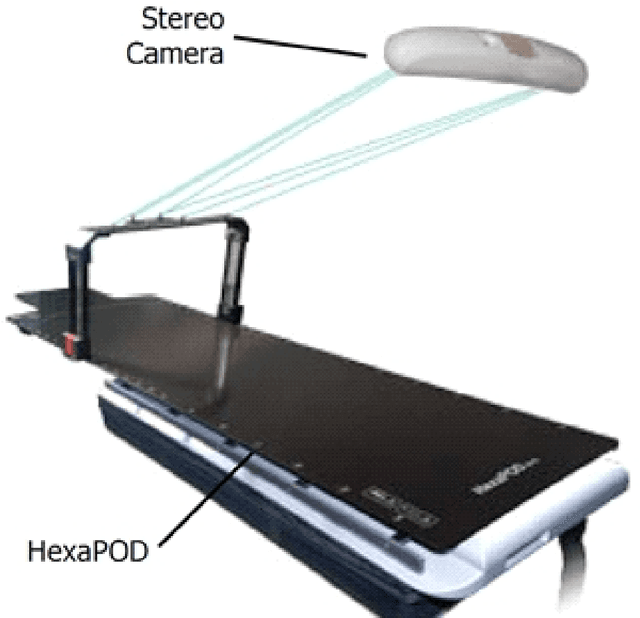
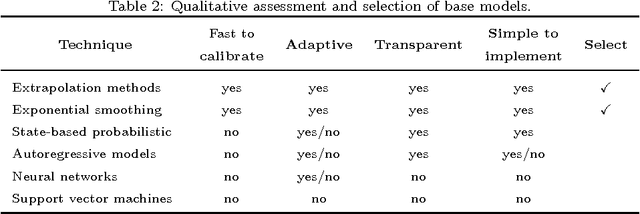
Purpose. Radiation therapy is a local treatment aimed at cells in and around a tumor. The goal of this study is to develop an algorithmic solution for predicting the position of a target in 3D in real time, aiming for the short fixed calibration time for each patient at the beginning of the procedure. Accurate predictions of lung tumor motion are expected to improve the precision of radiation treatment by controlling the position of a couch or a beam in order to compensate for respiratory motion during radiation treatment. Methods. For developing the algorithmic solution, data mining techniques are used. A model form from the family of exponential smoothing is assumed, and the model parameters are fitted by minimizing the absolute disposition error, and the fluctuations of the prediction signal (jitter). The predictive performance is evaluated retrospectively on clinical datasets capturing different behavior (being quiet, talking, laughing), and validated in real-time on a prototype system with respiratory motion imitation. Results. An algorithmic solution for respiratory motion prediction (called ExSmi) is designed. ExSmi achieves good accuracy of prediction (error $4-9$ mm/s) with acceptable jitter values (5-7 mm/s), as tested on out-of-sample data. The datasets, the code for algorithms and the experiments are openly available for research purposes on a dedicated website. Conclusions. The developed algorithmic solution performs well to be prototyped and deployed in applications of radiotherapy.
On the relation between accuracy and fairness in binary classification
May 21, 2015
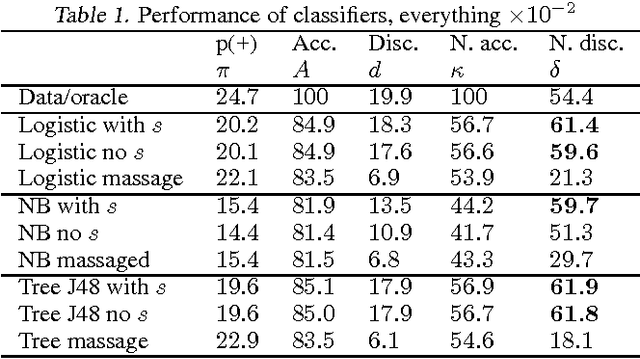

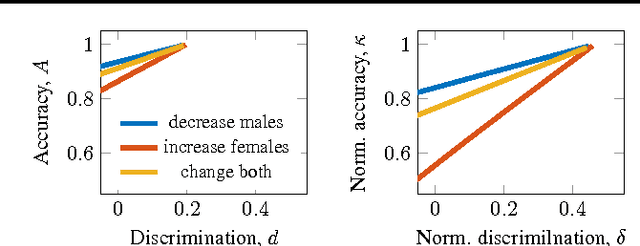
Our study revisits the problem of accuracy-fairness tradeoff in binary classification. We argue that comparison of non-discriminatory classifiers needs to account for different rates of positive predictions, otherwise conclusions about performance may be misleading, because accuracy and discrimination of naive baselines on the same dataset vary with different rates of positive predictions. We provide methodological recommendations for sound comparison of non-discriminatory classifiers, and present a brief theoretical and empirical analysis of tradeoffs between accuracy and non-discrimination.
Predictive User Modeling with Actionable Attributes
Dec 23, 2013

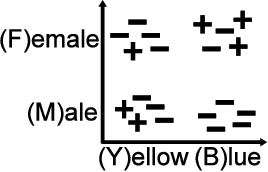
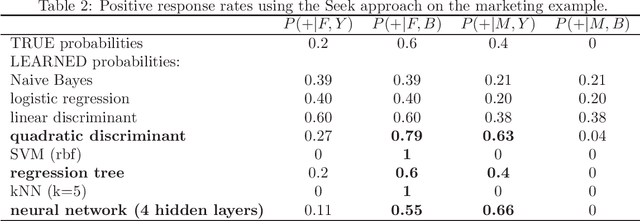
Different machine learning techniques have been proposed and used for modeling individual and group user needs, interests and preferences. In the traditional predictive modeling instances are described by observable variables, called attributes. The goal is to learn a model for predicting the target variable for unseen instances. For example, for marketing purposes a company consider profiling a new user based on her observed web browsing behavior, referral keywords or other relevant information. In many real world applications the values of some attributes are not only observable, but can be actively decided by a decision maker. Furthermore, in some of such applications the decision maker is interested not only to generate accurate predictions, but to maximize the probability of the desired outcome. For example, a direct marketing manager can choose which type of a special offer to send to a client (actionable attribute), hoping that the right choice will result in a positive response with a higher probability. We study how to learn to choose the value of an actionable attribute in order to maximize the probability of a desired outcome in predictive modeling. We emphasize that not all instances are equally sensitive to changes in actions. Accurate choice of an action is critical for those instances, which are on the borderline (e.g. users who do not have a strong opinion one way or the other). We formulate three supervised learning approaches for learning to select the value of an actionable attribute at an instance level. We also introduce a focused training procedure which puts more emphasis on the situations where varying the action is the most likely to take the effect. The proof of concept experimental validation on two real-world case studies in web analytics and e-learning domains highlights the potential of the proposed approaches.
How good is the Electricity benchmark for evaluating concept drift adaptation
Jan 15, 2013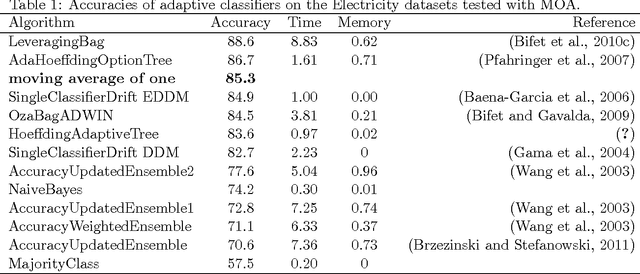
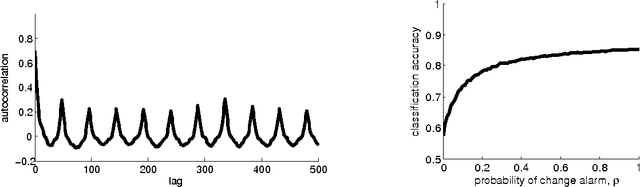
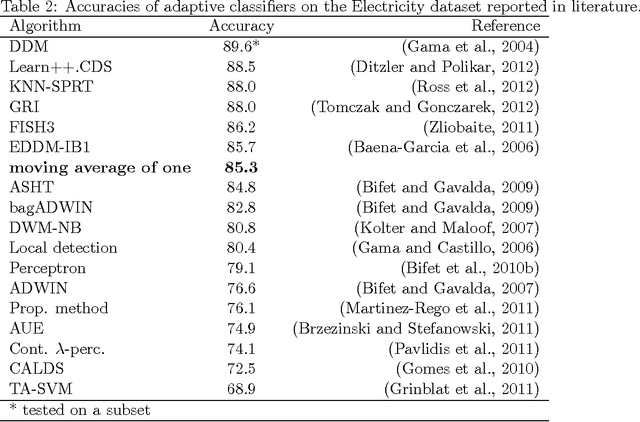
In this correspondence, we will point out a problem with testing adaptive classifiers on autocorrelated data. In such a case random change alarms may boost the accuracy figures. Hence, we cannot be sure if the adaptation is working well.