 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDecision-Point Guided Safe Policy Improvement
Paper and Code
Oct 12, 2024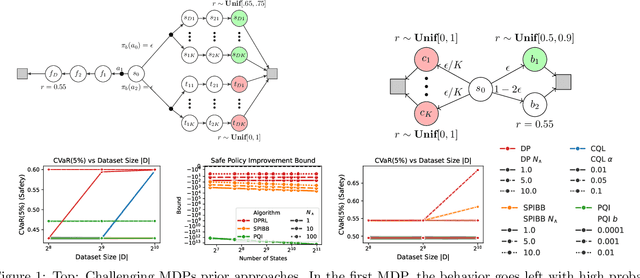
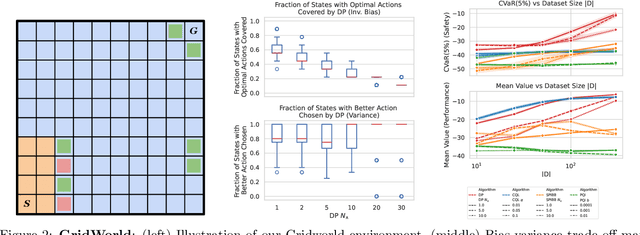

Within batch reinforcement learning, safe policy improvement (SPI) seeks to ensure that the learnt policy performs at least as well as the behavior policy that generated the dataset. The core challenge in SPI is seeking improvements while balancing risk when many state-action pairs may be infrequently visited. In this work, we introduce Decision Points RL (DPRL), an algorithm that restricts the set of state-action pairs (or regions for continuous states) considered for improvement. DPRL ensures high-confidence improvement in densely visited states (i.e. decision points) while still utilizing data from sparsely visited states. By appropriately limiting where and how we may deviate from the behavior policy, we achieve tighter bounds than prior work; specifically, our data-dependent bounds do not scale with the size of the state and action spaces. In addition to the analysis, we demonstrate that DPRL is both safe and performant on synthetic and real datasets.