 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOrder Independence With Finetuning
Paper and Code
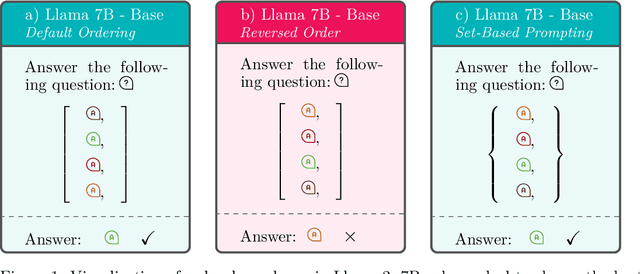

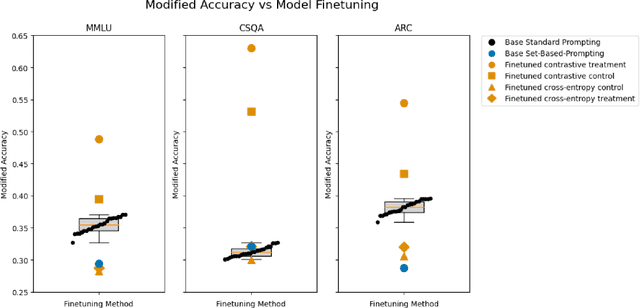

Large language models (LLMs) demonstrate remarkable performance on many NLP tasks, yet often exhibit order dependence: simply reordering semantically identical tokens (e.g., answer choices in multiple-choice questions) can lead to inconsistent predictions. Recent work proposes Set-Based Prompting (SBP) as a way to remove order information from designated token subsets, thereby mitigating positional biases. However, applying SBP on base models induces an out-of-distribution input format, which can degrade in-distribution performance. We introduce a fine-tuning strategy that integrates SBP into the training process, "pulling" these set-formatted prompts closer to the model's training manifold. We show that SBP can be incorporated into a model via fine-tuning. Our experiments on in-distribution (MMLU) and out-of-distribution (CSQA, ARC Challenge) multiple-choice tasks show that SBP fine-tuning significantly improves accuracy and robustness to answer-order permutations, all while preserving broader language modeling capabilities. We discuss the broader implications of order-invariant modeling and outline future directions for building fairer, more consistent LLMs.