 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConserWeightive Behavioral Cloning for Reliable Offline Reinforcement Learning
Paper and Code
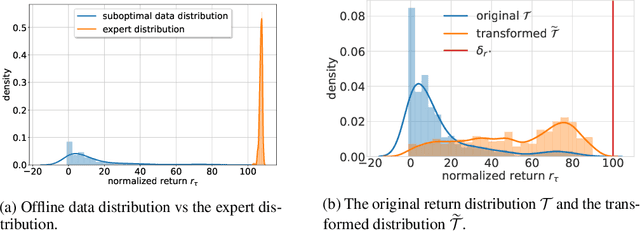
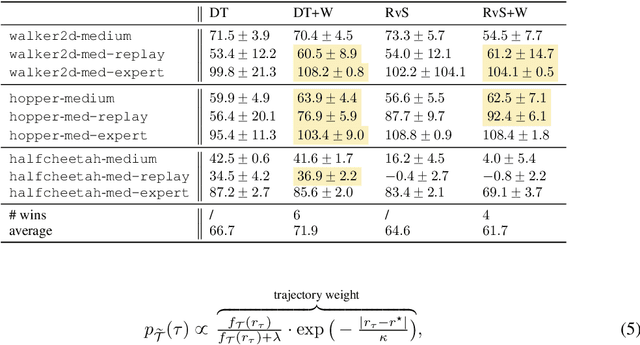
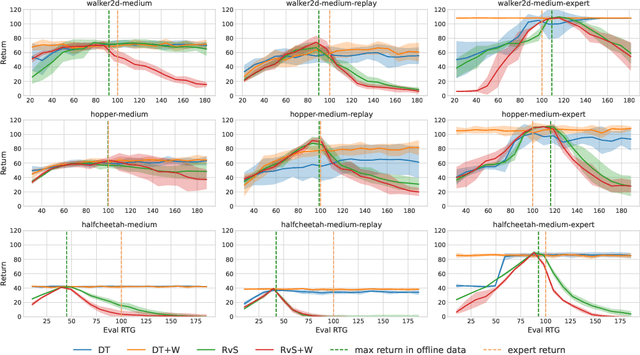
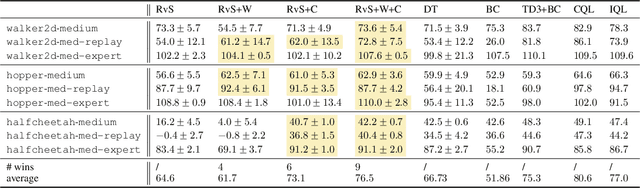
The goal of offline reinforcement learning (RL) is to learn near-optimal policies from static logged datasets, thus sidestepping expensive online interactions. Behavioral cloning (BC) provides a straightforward solution to offline RL by mimicking offline trajectories via supervised learning. Recent advances (Chen et al., 2021; Janner et al., 2021; Emmons et al., 2021) have shown that by conditioning on desired future returns, BC can perform competitively to their value-based counterparts, while enjoying much more simplicity and training stability. However, the distribution of returns in the offline dataset can be arbitrarily skewed and suboptimal, which poses a unique challenge for conditioning BC on expert returns at test time. We propose ConserWeightive Behavioral Cloning (CWBC), a simple and effective method for improving the performance of conditional BC for offline RL with two key components: trajectory weighting and conservative regularization. Trajectory weighting addresses the bias-variance tradeoff in conditional BC and provides a principled mechanism to learn from both low return trajectories (typically plentiful) and high return trajectories (typically few). Further, we analyze the notion of conservatism in existing BC methods, and propose a novel conservative regularize that explicitly encourages the policy to stay close to the data distribution. The regularizer helps achieve more reliable performance, and removes the need for ad-hoc tuning of the conditioning value during evaluation. We instantiate CWBC in the context of Reinforcement Learning via Supervised Learning (RvS) (Emmons et al., 2021) and Decision Transformer (DT) (Chen et al., 2021), and empirically show that it significantly boosts the performance and stability of prior methods on various offline RL benchmarks. Code is available at https://github.com/tung-nd/cwbc.