 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOnline Decision Transformer
Paper and Code
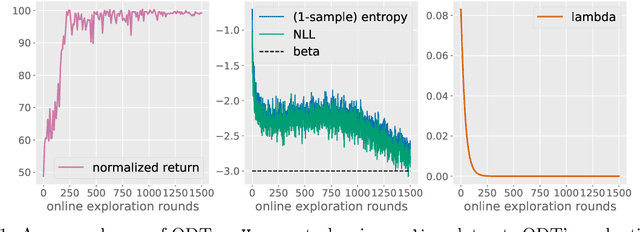
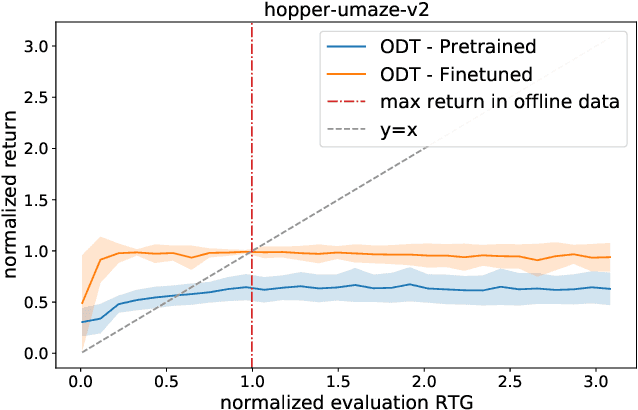
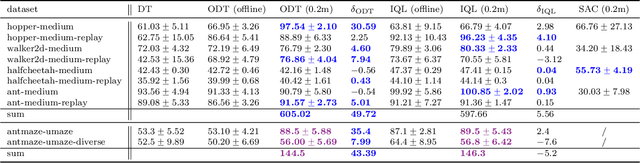
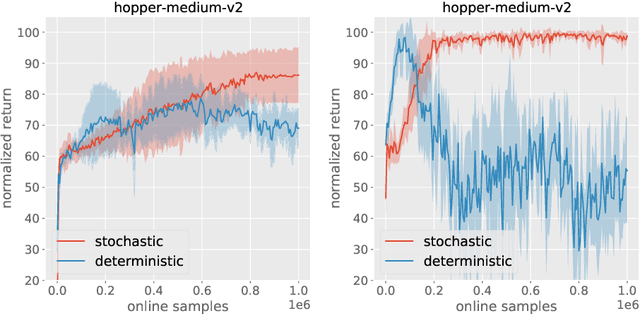
Recent work has shown that offline reinforcement learning (RL) can be formulated as a sequence modeling problem (Chen et al., 2021; Janner et al., 2021) and solved via approaches similar to large-scale language modeling. However, any practical instantiation of RL also involves an online component, where policies pretrained on passive offline datasets are finetuned via taskspecific interactions with the environment. We propose Online Decision Transformers (ODT), an RL algorithm based on sequence modeling that blends offline pretraining with online finetuning in a unified framework. Our framework uses sequence-level entropy regularizers in conjunction with autoregressive modeling objectives for sample-efficient exploration and finetuning. Empirically, we show that ODT is competitive with the state-of-the-art in absolute performance on the D4RL benchmark but shows much more significant gains during the finetuning procedure.