Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUser Response and Sentiment Prediction for Automatic Dialogue Evaluation
Paper and Code
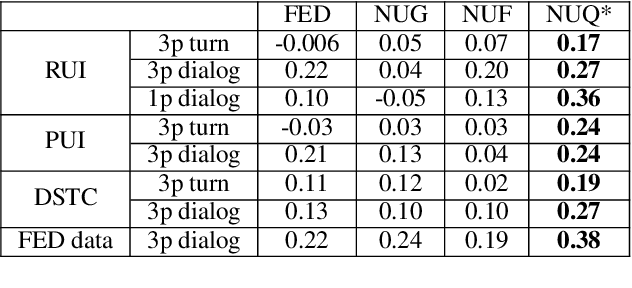
Automatic evaluation is beneficial for open-domain dialog system development. However, standard word-overlap metrics (BLEU, ROUGE) do not correlate well with human judgements of open-domain dialog systems. In this work we propose to use the sentiment of the next user utterance for turn or dialog level evaluation. Specifically we propose three methods: one that predicts the next sentiment directly, and two others that predict the next user utterance using an utterance or a feedback generator model and then classify its sentiment. Experiments show our model outperforming existing automatic evaluation metrics on both written and spoken open-domain dialogue datasets.
* Accepted at EMNLP 2021 Evaluations and Assessments of Neural
Conversation Systems Workshop. 2 pages, 1 table
View paper on