 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAttacking and Defending Machine Learning Applications of Public Cloud
Jul 27, 2020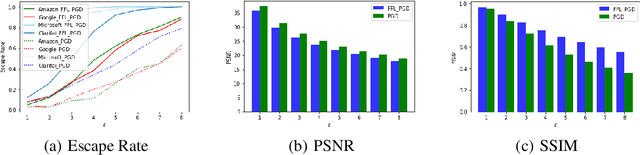


Adversarial attack breaks the boundaries of traditional security defense. For adversarial attack and the characteristics of cloud services, we propose Security Development Lifecycle for Machine Learning applications, e.g., SDL for ML. The SDL for ML helps developers build more secure software by reducing the number and severity of vulnerabilities in ML-as-a-service, while reducing development cost.
Advbox: a toolbox to generate adversarial examples that fool neural networks
Feb 21, 2020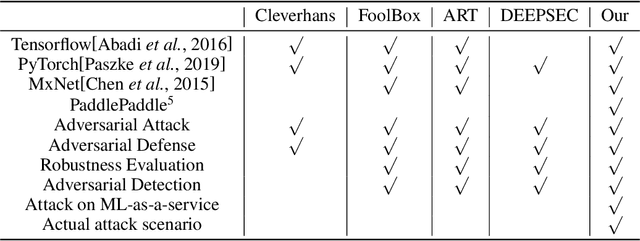



In recent years, neural networks have been extensively deployed for computer vision tasks, particularly visual classification problems, where new algorithms reported to achieve or even surpass the human performance. Recent studies have shown that they are all vulnerable to the attack of adversarial examples. Small and often imperceptible perturbations to the input images are sufficient to fool the most powerful neural networks. \emph{Advbox} is a toolbox to generate adversarial examples that fool neural networks in PaddlePaddle, PyTorch, Caffe2, MxNet, Keras, TensorFlow and it can benchmark the robustness of machine learning models. Compared to previous work, our platform supports black box attacks on Machine-Learning-as-a-service, as well as more attack scenarios, such as Face Recognition Attack, Stealth T-shirt, and DeepFake Face Detect. The code is licensed under the Apache 2.0 and is openly available at https://github.com/advboxes/AdvBox. Advbox now supports Python 3.
FastWordBug: A Fast Method To Generate Adversarial Text Against NLP Applications
Jan 31, 2020
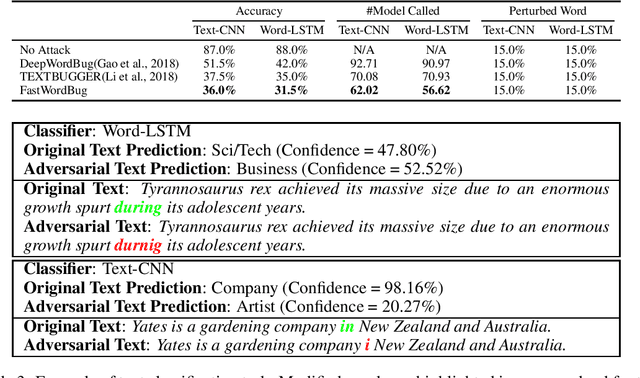


In this paper, we present a novel algorithm, FastWordBug, to efficiently generate small text perturbations in a black-box setting that forces a sentiment analysis or text classification mode to make an incorrect prediction. By combining the part of speech attributes of words, we propose a scoring method that can quickly identify important words that affect text classification. We evaluate FastWordBug on three real-world text datasets and two state-of-the-art machine learning models under black-box setting. The results show that our method can significantly reduce the accuracy of the model, and at the same time, we can call the model as little as possible, with the highest attack efficiency. We also attack two popular real-world cloud services of NLP, and the results show that our method works as well.
Transferability of Adversarial Examples to Attack Cloud-based Image Classifier Service
Jan 20, 2020

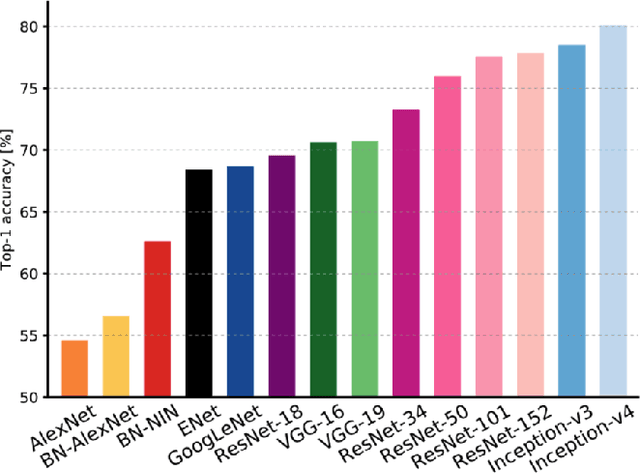
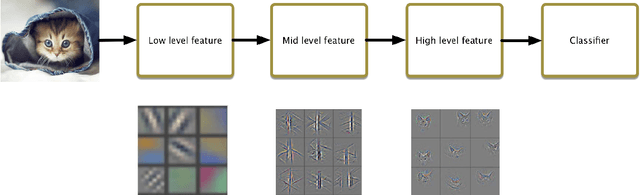
In recent years, Deep Learning(DL) techniques have been extensively deployed for computer vision tasks, particularly visual classification problems, where new algorithms reported to achieve or even surpass the human performance. While many recent works demonstrated that DL models are vulnerable to adversarial examples. Fortunately, generating adversarial examples usually requires white-box access to the victim model, and real-world cloud-based image classification services are more complex than white-box classifier,the architecture and parameters of DL models on cloud platforms cannot be obtained by the attacker. The attacker can only access the APIs opened by cloud platforms. Thus, keeping models in the cloud can usually give a (false) sense of security. In this paper, we mainly focus on studying the security of real-world cloud-based image classification services. Specifically, (1) We propose a novel attack method, Fast Featuremap Loss PGD (FFL-PGD) attack based on Substitution model, which achieves a high bypass rate with a very limited number of queries. Instead of millions of queries in previous studies, our method finds the adversarial examples using only two queries per image; and (2) we make the first attempt to conduct an extensive empirical study of black-box attacks against real-world cloud-based classification services. Through evaluations on four popular cloud platforms including Amazon, Google, Microsoft, Clarifai, we demonstrate that FFL-PGD attack has a success rate over 90\% among different classification services. (3) We discuss the possible defenses to address these security challenges in cloud-based classification services. Our defense technology is mainly divided into model training stage and image preprocessing stage.
Improving Adversarial Robustness via Attention and Adversarial Logit Pairing
Aug 23, 2019
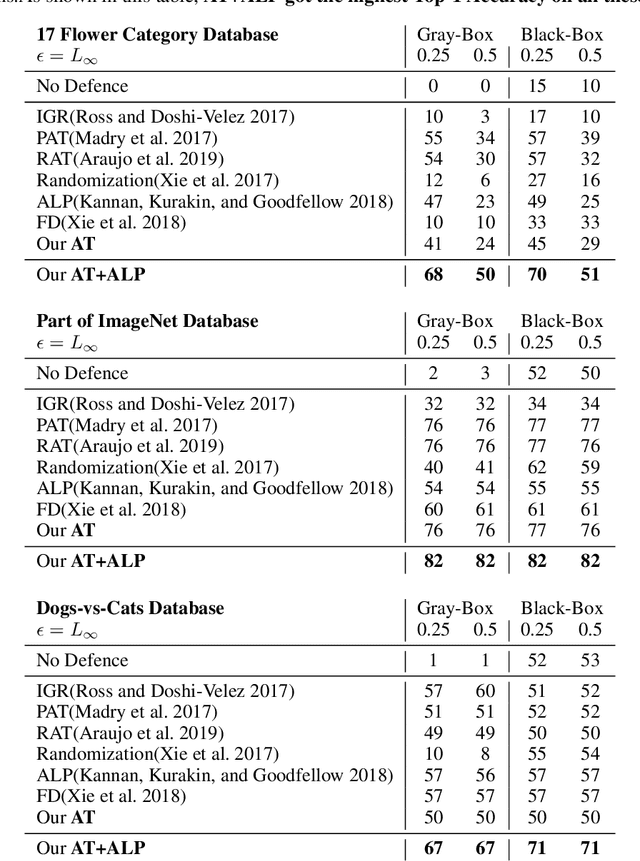
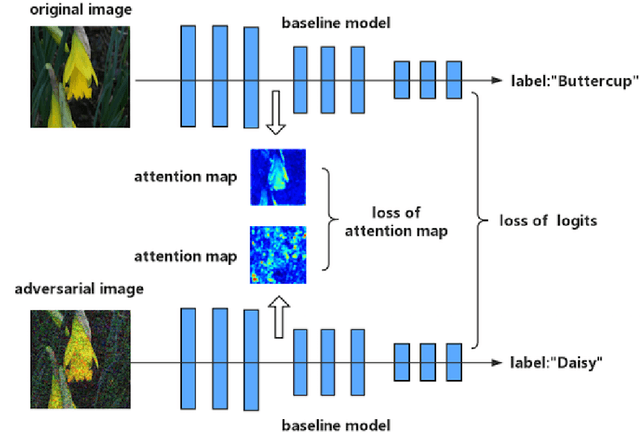
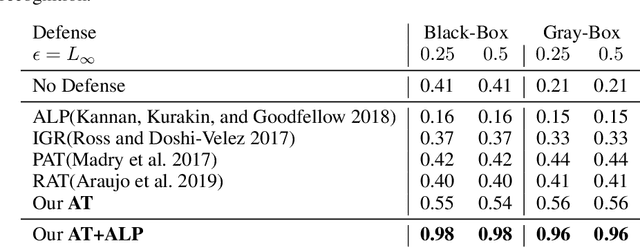
Though deep neural networks have achieved the state of the art performance in visual classification, recent studies have shown that they are all vulnerable to the attack of adversarial examples. In this paper, we develop improved techniques for defending against adversarial examples.First, we introduce enhanced defense using a technique we call \textbf{Attention and Adversarial Logit Pairing(AT+ALP)}, a method that encourages both attention map and logit for pairs of examples to be similar. When applied to clean examples and their adversarial counterparts, \textbf{AT+ALP} improves accuracy on adversarial examples over adversarial training.Next,We show that our \textbf{AT+ALP} can effectively increase the average activations of adversarial examples in the key area and demonstrate that it focuse on more discriminate features to improve the robustness of the model.Finally,we conducte extensive experiments using a wide range of datasets and the experiment results show that our \textbf{AT+ALP} achieves \textbf{the state of the art} defense.For example,on \textbf{17 Flower Category Database}, under strong 200-iteration \textbf{PGD} gray-box and black-box attacks where prior art has 34\% and 39\% accuracy, our method achieves \textbf{50\%} and \textbf{51\%}.Compared with previous work,our work is evaluated under highly challenging PGD attack:the maximum perturbation $\epsilon \in \{0.25,0.5\}$ i.e. $L_\infty \in \{0.25,0.5\}$ with 10 to 200 attack iterations.To our knowledge, such a strong attack has not been previously explored on a wide range of datasets.
Cloud-based Image Classification Service Is Not Robust To Simple Transformations: A Forgotten Battlefield
Jun 19, 2019


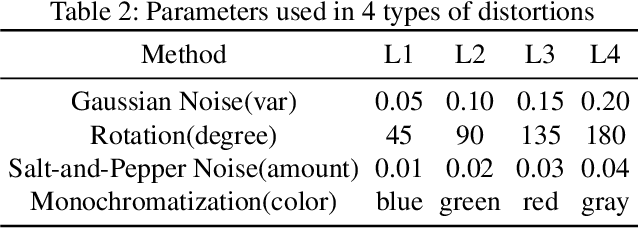
Many recent works demonstrated that Deep Learning models are vulnerable to adversarial examples.Fortunately, generating adversarial examples usually requires white-box access to the victim model, and the attacker can only access the APIs opened by cloud platforms. Thus, keeping models in the cloud can usually give a (false) sense of security.Unfortunately, cloud-based image classification service is not robust to simple transformations such as Gaussian Noise, Salt-and-Pepper Noise, Rotation and Monochromatization. In this paper,(1) we propose one novel attack method called Image Fusion(IF) attack, which achieve a high bypass rate,can be implemented only with OpenCV and is difficult to defend; and (2) we make the first attempt to conduct an extensive empirical study of Simple Transformation (ST) attacks against real-world cloud-based classification services. Through evaluations on four popular cloud platforms including Amazon, Google, Microsoft, Clarifai, we demonstrate that ST attack has a success rate of approximately 100% except Amazon approximately 50%, IF attack have a success rate over 98% among different classification services. (3) We discuss the possible defenses to address these security challenges.Experiments show that our defense technology can effectively defend known ST attacks.