 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePACE: Defying the Scaling Hypothesis of Exploration in Iterative Alignment for Mathematical Reasoning
Feb 05, 2026Iterative Direct Preference Optimization has emerged as the state-of-the-art paradigm for aligning Large Language Models on reasoning tasks. Standard implementations (DPO-R1) rely on Best-of-N sampling (e.g., $N \ge 8$) to mine golden trajectories from the distribution tail. In this paper, we challenge this scaling hypothesis and reveal a counter-intuitive phenomenon: in mathematical reasoning, aggressive exploration yields diminishing returns and even catastrophic policy collapse. We theoretically demonstrate that scaling $N$ amplifies verifier noise and induces detrimental distribution shifts. To resolve this, we introduce \textbf{PACE} (Proximal Alignment via Corrective Exploration), which replaces brute-force mining with a generation-based corrective strategy. Operating with a minimal budget ($2<N<3$), PACE synthesizes high-fidelity preference pairs from failed explorations. Empirical evaluations show that PACE outperforms DPO-R1 $(N=16)$ while using only about $1/5$ of the compute, demonstrating superior robustness against reward hacking and label noise.
Tool-Augmented Policy Optimization: Synergizing Reasoning and Adaptive Tool Use with Reinforcement Learning
Oct 08, 2025Recent advances in large language models (LLMs) have popularized test-time scaling, where models generate additional reasoning tokens before producing final answers. These approaches have demonstrated significant performance improvements on benchmarks involving mathematical reasoning. However, language models relying solely on direct inference still struggle with tasks demanding up-to-date knowledge or computational tools such as calculators and code interpreters for complex arithmetic operations. To overcome these limitations, we propose Tool-Augmented Policy Optimization (TAPO), a novel reinforcement learning framework that systematically integrates multi-hop reasoning with adaptive tool-calling capabilities. Our approach employs a modified version of Dynamic Sampling Policy Optimization (DAPO), a recently developed RL paradigm, which we adapt specifically for tool invocation scenarios, enabling models to dynamically interleave complex reasoning with on-demand tool usage (including search APIs and Python interpreters). To support this research, we introduce two new datasets: TAPO-easy-60K and TAPO-hard-18K, specifically designed to train and evaluate both fact-based reasoning and mathematical calculation capabilities. Our experiments on Qwen2.5-3B and Qwen2.5-7B models demonstrate the effectiveness of our approach, with both models achieving state-of-the-art performance on tasks requiring external knowledge and mathematical computation among methods with comparable parameters. Notably, TAPO achieves more efficient tool utilization than baseline methods while preventing excessive calls caused by reward hacking. These results highlight the significant potential of combining advanced reasoning with tool usage to enhance model performance in knowledge-intensive and computationally demanding tasks.
Divergence of Empirical Neural Tangent Kernel in Classification Problems
Apr 15, 2025This paper demonstrates that in classification problems, fully connected neural networks (FCNs) and residual neural networks (ResNets) cannot be approximated by kernel logistic regression based on the Neural Tangent Kernel (NTK) under overtraining (i.e., when training time approaches infinity). Specifically, when using the cross-entropy loss, regardless of how large the network width is (as long as it is finite), the empirical NTK diverges from the NTK on the training samples as training time increases. To establish this result, we first demonstrate the strictly positive definiteness of the NTKs for multi-layer FCNs and ResNets. Then, we prove that during training, % with the cross-entropy loss, the neural network parameters diverge if the smallest eigenvalue of the empirical NTK matrix (Gram matrix) with respect to training samples is bounded below by a positive constant. This behavior contrasts sharply with the lazy training regime commonly observed in regression problems. Consequently, using a proof by contradiction, we show that the empirical NTK does not uniformly converge to the NTK across all times on the training samples as the network width increases. We validate our theoretical results through experiments on both synthetic data and the MNIST classification task. This finding implies that NTK theory is not applicable in this context, with significant theoretical implications for understanding neural networks in classification problems.
On the Impacts of the Random Initialization in the Neural Tangent Kernel Theory
Oct 08, 2024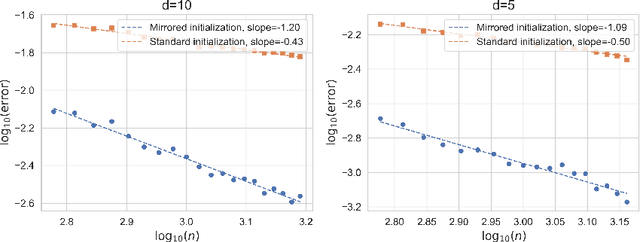


This paper aims to discuss the impact of random initialization of neural networks in the neural tangent kernel (NTK) theory, which is ignored by most recent works in the NTK theory. It is well known that as the network's width tends to infinity, the neural network with random initialization converges to a Gaussian process $f^{\mathrm{GP}}$, which takes values in $L^{2}(\mathcal{X})$, where $\mathcal{X}$ is the domain of the data. In contrast, to adopt the traditional theory of kernel regression, most recent works introduced a special mirrored architecture and a mirrored (random) initialization to ensure the network's output is identically zero at initialization. Therefore, it remains a question whether the conventional setting and mirrored initialization would make wide neural networks exhibit different generalization capabilities. In this paper, we first show that the training dynamics of the gradient flow of neural networks with random initialization converge uniformly to that of the corresponding NTK regression with random initialization $f^{\mathrm{GP}}$. We then show that $\mathbf{P}(f^{\mathrm{GP}} \in [\mathcal{H}^{\mathrm{NT}}]^{s}) = 1$ for any $s < \frac{3}{d+1}$ and $\mathbf{P}(f^{\mathrm{GP}} \in [\mathcal{H}^{\mathrm{NT}}]^{s}) = 0$ for any $s \geq \frac{3}{d+1}$, where $[\mathcal{H}^{\mathrm{NT}}]^{s}$ is the real interpolation space of the RKHS $\mathcal{H}^{\mathrm{NT}}$ associated with the NTK. Consequently, the generalization error of the wide neural network trained by gradient descent is $\Omega(n^{-\frac{3}{d+3}})$, and it still suffers from the curse of dimensionality. On one hand, the result highlights the benefits of mirror initialization. On the other hand, it implies that NTK theory may not fully explain the superior performance of neural networks.
Statistical Optimality of Deep Wide Neural Networks
May 04, 2023In this paper, we consider the generalization ability of deep wide feedforward ReLU neural networks defined on a bounded domain $\mathcal X \subset \mathbb R^{d}$. We first demonstrate that the generalization ability of the neural network can be fully characterized by that of the corresponding deep neural tangent kernel (NTK) regression. We then investigate on the spectral properties of the deep NTK and show that the deep NTK is positive definite on $\mathcal{X}$ and its eigenvalue decay rate is $(d+1)/d$. Thanks to the well established theories in kernel regression, we then conclude that multilayer wide neural networks trained by gradient descent with proper early stopping achieve the minimax rate, provided that the regression function lies in the reproducing kernel Hilbert space (RKHS) associated with the corresponding NTK. Finally, we illustrate that the overfitted multilayer wide neural networks can not generalize well on $\mathbb S^{d}$.