 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVideoThinker: Building Agentic VideoLLMs with LLM-Guided Tool Reasoning
Jan 22, 2026Long-form video understanding remains a fundamental challenge for current Video Large Language Models. Most existing models rely on static reasoning over uniformly sampled frames, which weakens temporal localization and leads to substantial information loss in long videos. Agentic tools such as temporal retrieval, spatial zoom, and temporal zoom offer a natural way to overcome these limitations by enabling adaptive exploration of key moments. However, constructing agentic video understanding data requires models that already possess strong long-form video comprehension, creating a circular dependency. We address this challenge with VideoThinker, an agentic Video Large Language Model trained entirely on synthetic tool interaction trajectories. Our key idea is to convert videos into rich captions and employ a powerful agentic language model to generate multi-step tool use sequences in caption space. These trajectories are subsequently grounded back to video by replacing captions with the corresponding frames, yielding a large-scale interleaved video and tool reasoning dataset without requiring any long-form understanding from the underlying model. Training on this synthetic agentic dataset equips VideoThinker with dynamic reasoning capabilities, adaptive temporal exploration, and multi-step tool use. Remarkably, VideoThinker significantly outperforms both caption-only language model agents and strong video model baselines across long-video benchmarks, demonstrating the effectiveness of tool augmented synthetic data and adaptive retrieval and zoom reasoning for long-form video understanding.
InstructAttribute: Fine-grained Object Attributes editing with Instruction
May 01, 2025Text-to-image (T2I) diffusion models, renowned for their advanced generative abilities, are extensively utilized in image editing applications, demonstrating remarkable effectiveness. However, achieving precise control over fine-grained attributes still presents considerable challenges. Existing image editing techniques either fail to modify the attributes of an object or struggle to preserve its structure and maintain consistency in other areas of the image. To address these challenges, we propose the Structure-Preserving and Attribute Amplification (SPAA), a training-free method which enables precise control over the color and material transformations of objects by editing the self-attention maps and cross-attention values. Furthermore, we constructed the Attribute Dataset, which encompasses nearly all colors and materials associated with various objects, by integrating multimodal large language models (MLLM) to develop an automated pipeline for data filtering and instruction labeling. Training on this dataset, we present our InstructAttribute, an instruction-based model designed to facilitate fine-grained editing of color and material attributes. Extensive experiments demonstrate that our method achieves superior performance in object-level color and material editing, outperforming existing instruction-based image editing approaches.
ColorEdit: Training-free Image-Guided Color editing with diffusion model
Nov 15, 2024
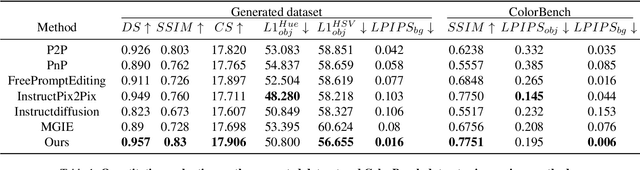


Text-to-image (T2I) diffusion models, with their impressive generative capabilities, have been adopted for image editing tasks, demonstrating remarkable efficacy. However, due to attention leakage and collision between the cross-attention map of the object and the new color attribute from the text prompt, text-guided image editing methods may fail to change the color of an object, resulting in a misalignment between the resulting image and the text prompt. In this paper, we conduct an in-depth analysis on the process of text-guided image synthesizing and what semantic information different cross-attention blocks have learned. We observe that the visual representation of an object is determined in the up-block of the diffusion model in the early stage of the denoising process, and color adjustment can be achieved through value matrices alignment in the cross-attention layer. Based on our findings, we propose a straightforward, yet stable, and effective image-guided method to modify the color of an object without requiring any additional fine-tuning or training. Lastly, we present a benchmark dataset called COLORBENCH, the first benchmark to evaluate the performance of color change methods. Extensive experiments validate the effectiveness of our method in object-level color editing and surpass the performance of popular text-guided image editing approaches in both synthesized and real images.