 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaCodec: A Predictive Visual Code for Video MLLMs
Jun 01, 2026Video is temporally redundant: adjacent frames usually share most objects, background, and layout. Yet existing video multimodal large language models (video MLLMs) usually encode each sampled frame as an independent RGB image, causing visual tokens to repeat content already present in earlier frames. This suggests a more direct video interface: send a full reference frame only when the scene cannot be predicted well from prior context, and otherwise transmit a compact description of inter-frame changes. We call this interface a \emph{predictive visual code}, and instantiate it for video MLLMs as \textbf{AdaCodec}. AdaCodec spends full visual tokens on a reference frame only when its conditional predictive cost is high; otherwise, it encodes inter-frame changes, including motion and prediction residuals, as compact P-tokens. Across all eleven benchmarks, AdaCodec improves over the Qwen3-VL-8B per-frame RGB baseline at a matched visual-token budget. Even at $1/7$ the budget, AdaCodec with 32k tokens surpasses the 224k baseline on all long-video benchmarks; on five general-video benchmarks, it raises the average score while substantially cutting time-to-first-token from 9.26s to 1.62s.
Not only where, But when: Temporal Scheduling for RLVR
May 25, 2026Reinforcement learning with verifiable rewards (RLVR) has become a core technique for post-training of Large Language Models (LLMs). While policy optimization is driven by all sampled tokens under a globally broadcast scalar reward, the heterogeneous policy behaviors exhibited along trajectories are largely overlooked without differentiation. Existing works address this by credit allocation, including token-level advantage reweighting, and selective token optimization, however, the allocation criterion are principally stagnant throughout training, limiting resilient policy evolution. In this work, we argue that \textit{when} learning signals are scheduled can be as important as \textit{where} they are allocated across tokens, and introduce the temporal dimension that scheduling the credit allocation criteria over the course of RLVR optimization. We find that prioritizing targeted tokens emphasized with specific policy behaviors, and gradually attenuating toward general optimization leads to more stable and efficient learning dynamics. Furthermore, we show that simple trajectory percentiles provide a natural perspective for distinguishing policy behaviors, and works effectively with temporal scheduling. Our analysis reveals that standard optimization substantially sacrifices policy entropy when simultaneously accommodating heterogeneous behaviors, whereas temporal scheduling yields healthier policy evolution dynamics. Experiments across mathematical and general reasoning benchmarks demonstrate consistent improvements, suggesting that temporal scheduling constitutes a promising optimization dimension.
Enhancing Pretrained Model-based Continual Representation Learning via Guided Random Projection
Mar 19, 2026Recent paradigms in Random Projection Layer (RPL)-based continual representation learning have demonstrated superior performance when building upon a pre-trained model (PTM). These methods insert a randomly initialized RPL after a PTM to enhance feature representation in the initial stage. Subsequently, a linear classification head is used for analytic updates in the continual learning stage. However, under severe domain gaps between pre-trained representations and target domains, a randomly initialized RPL exhibits limited expressivity under large domain shifts. While largely scaling up the RPL dimension can improve expressivity, it also induces an ill-conditioned feature matrix, thereby destabilizing the recursive analytic updates of the linear head. To this end, we propose the Stochastic Continual Learner with MemoryGuard Supervisory Mechanism (SCL-MGSM). Unlike random initialization, MGSM constructs the projection layer via a principled, data-guided mechanism that progressively selects target-aligned random bases to adapt the PTM representation to downstream tasks. This facilitates the construction of a compact yet expressive RPL while improving the numerical stability of analytic updates. Extensive experiments on multiple exemplar-free Class Incremental Learning (CIL) benchmarks demonstrate that SCL-MGSM achieves superior performance compared to state-of-the-art methods.
VideoThinker: Building Agentic VideoLLMs with LLM-Guided Tool Reasoning
Jan 22, 2026Long-form video understanding remains a fundamental challenge for current Video Large Language Models. Most existing models rely on static reasoning over uniformly sampled frames, which weakens temporal localization and leads to substantial information loss in long videos. Agentic tools such as temporal retrieval, spatial zoom, and temporal zoom offer a natural way to overcome these limitations by enabling adaptive exploration of key moments. However, constructing agentic video understanding data requires models that already possess strong long-form video comprehension, creating a circular dependency. We address this challenge with VideoThinker, an agentic Video Large Language Model trained entirely on synthetic tool interaction trajectories. Our key idea is to convert videos into rich captions and employ a powerful agentic language model to generate multi-step tool use sequences in caption space. These trajectories are subsequently grounded back to video by replacing captions with the corresponding frames, yielding a large-scale interleaved video and tool reasoning dataset without requiring any long-form understanding from the underlying model. Training on this synthetic agentic dataset equips VideoThinker with dynamic reasoning capabilities, adaptive temporal exploration, and multi-step tool use. Remarkably, VideoThinker significantly outperforms both caption-only language model agents and strong video model baselines across long-video benchmarks, demonstrating the effectiveness of tool augmented synthetic data and adaptive retrieval and zoom reasoning for long-form video understanding.
MiroThinker: Pushing the Performance Boundaries of Open-Source Research Agents via Model, Context, and Interactive Scaling
Nov 18, 2025We present MiroThinker v1.0, an open-source research agent designed to advance tool-augmented reasoning and information-seeking capabilities. Unlike previous agents that only scale up model size or context length, MiroThinker explores interaction scaling at the model level, systematically training the model to handle deeper and more frequent agent-environment interactions as a third dimension of performance improvement. Unlike LLM test-time scaling, which operates in isolation and risks degradation with longer reasoning chains, interactive scaling leverages environment feedback and external information acquisition to correct errors and refine trajectories. Through reinforcement learning, the model achieves efficient interaction scaling: with a 256K context window, it can perform up to 600 tool calls per task, enabling sustained multi-turn reasoning and complex real-world research workflows. Across four representative benchmarks-GAIA, HLE, BrowseComp, and BrowseComp-ZH-the 72B variant achieves up to 81.9%, 37.7%, 47.1%, and 55.6% accuracy respectively, surpassing previous open-source agents and approaching commercial counterparts such as GPT-5-high. Our analysis reveals that MiroThinker benefits from interactive scaling consistently: research performance improves predictably as the model engages in deeper and more frequent agent-environment interactions, demonstrating that interaction depth exhibits scaling behaviors analogous to model size and context length. These findings establish interaction scaling as a third critical dimension for building next-generation open research agents, complementing model capacity and context windows.
Brain-JEPA: Brain Dynamics Foundation Model with Gradient Positioning and Spatiotemporal Masking
Sep 28, 2024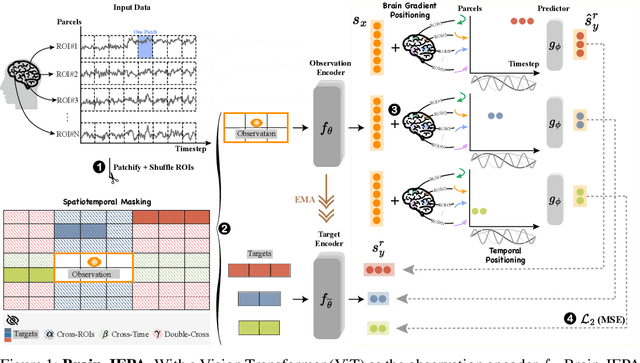
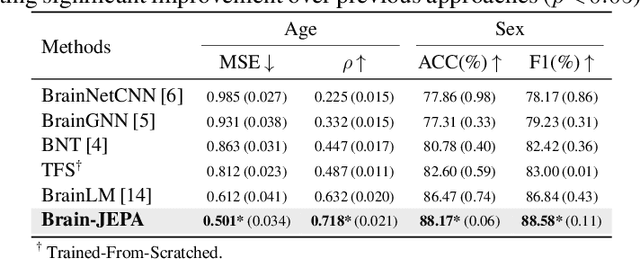
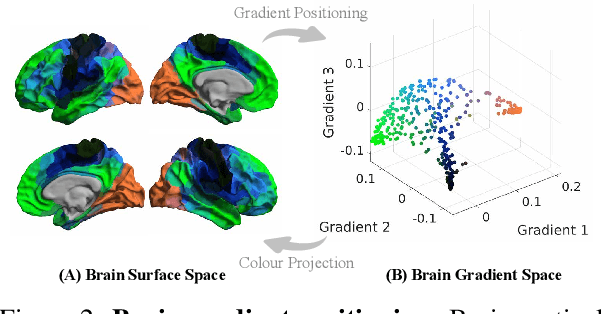
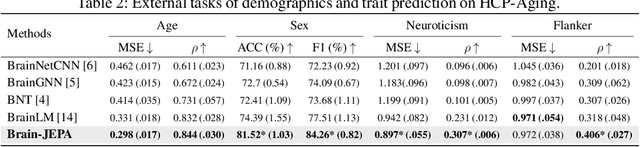
We introduce Brain-JEPA, a brain dynamics foundation model with the Joint-Embedding Predictive Architecture (JEPA). This pioneering model achieves state-of-the-art performance in demographic prediction, disease diagnosis/prognosis, and trait prediction through fine-tuning. Furthermore, it excels in off-the-shelf evaluations (e.g., linear probing) and demonstrates superior generalizability across different ethnic groups, surpassing the previous large model for brain activity significantly. Brain-JEPA incorporates two innovative techniques: Brain Gradient Positioning and Spatiotemporal Masking. Brain Gradient Positioning introduces a functional coordinate system for brain functional parcellation, enhancing the positional encoding of different Regions of Interest (ROIs). Spatiotemporal Masking, tailored to the unique characteristics of fMRI data, addresses the challenge of heterogeneous time-series patches. These methodologies enhance model performance and advance our understanding of the neural circuits underlying cognition. Overall, Brain-JEPA is paving the way to address pivotal questions of building brain functional coordinate system and masking brain activity at the AI-neuroscience interface, and setting a potentially new paradigm in brain activity analysis through downstream adaptation.
A Decomposition-Based Hybrid Ensemble CNN Framework for Improving Cross-Subject EEG Decoding Performance
Mar 14, 2022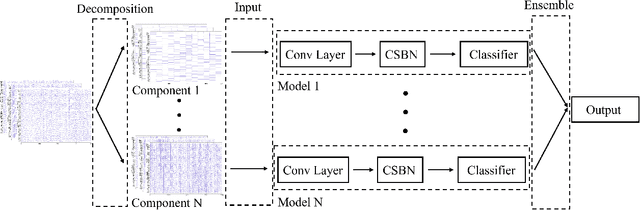

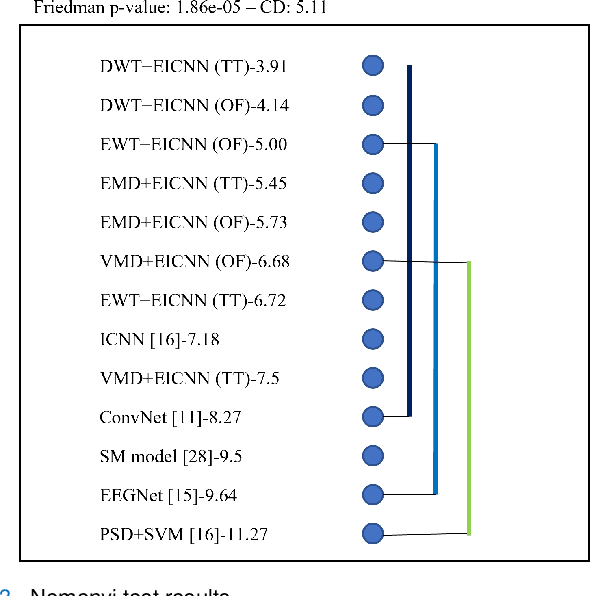
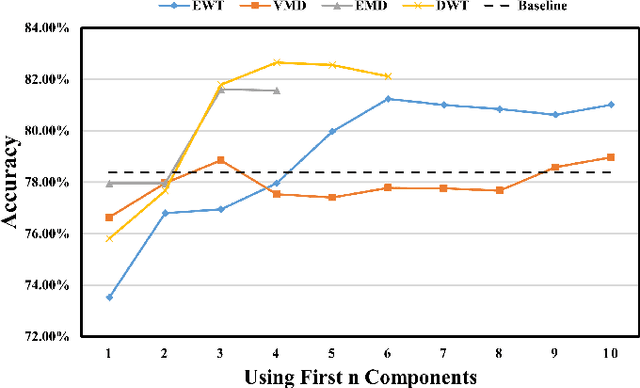
Electroencephalogram (EEG) signals are complex, non-linear, and non-stationary in nature. However, previous studies that applied decomposition to minimize the complexity mainly exploited the hand-engineering features, limiting the information learned in EEG decoding. Therefore, extracting additional primary features from different disassembled components to improve the EEG-based recognition performance remains challenging. On the other hand, attempts have been made to use a single model to learn the hand-engineering features. Less work has been done to improve the generalization ability through ensemble learning. In this work, we propose a novel decomposition-based hybrid ensemble convolutional neural network (CNN) framework to enhance the capability of decoding EEG signals. CNNs, in particular, automatically learn the primary features from raw disassembled components but not handcraft features. The first option is to fuse the obtained score before the Softmax layer and execute back-propagation on the entire ensemble network, whereas the other is to fuse the probability output of the Softmax layer. Moreover, a component-specific batch normalization (CSBN) layer is employed to reduce subject variability. Against the challenging cross-subject driver fatigue-related situation awareness (SA) recognition task, eight models are proposed under the framework, which all showed superior performance than the strong baselines. The performance of different decomposition methods and ensemble modes were further compared. Results indicated that discrete wavelet transform (DWT)-based ensemble CNN achieves the best 82.11% among the proposed models. Our framework can be simply extended to any CNN architecture and applied in any EEG-related sectors, opening the possibility of extracting more preliminary information from complex EEG data.
The Mirror Langevin Algorithm Converges with Vanishing Bias
Oct 11, 2021The technique of modifying the geometry of a problem from Euclidean to Hessian metric has proved to be quite effective in optimization, and has been the subject of study for sampling. The Mirror Langevin Diffusion (MLD) is a sampling analogue of mirror flow in continuous time, and it has nice convergence properties under log-Sobolev or Poincare inequalities relative to the Hessian metric, as shown by Chewi et al. (2020). In discrete time, a simple discretization of MLD is the Mirror Langevin Algorithm (MLA) studied by Zhang et al. (2020), who showed a biased convergence bound with a non-vanishing bias term (does not go to zero as step size goes to zero). This raised the question of whether we need a better analysis or a better discretization to achieve a vanishing bias. Here we study the basic Mirror Langevin Algorithm and show it indeed has a vanishing bias. We apply mean-square analysis based on Li et al. (2019) and Li et al. (2021) to show the mixing time bound for MLA under the modified self-concordance condition introduced by Zhang et al. (2020).
Sqrt(d) Dimension Dependence of Langevin Monte Carlo
Sep 23, 2021

This article considers the popular MCMC method of unadjusted Langevin Monte Carlo (LMC) and provides a non-asymptotic analysis of its sampling error in 2-Wasserstein distance. The proof is based on a mean-square analysis framework refined from Li et al. (2019), which works for a large class of sampling algorithms based on discretizations of contractive SDEs. We establish an $\tilde{O}(\sqrt{d}/\epsilon)$ mixing time bound for LMC, without warm start, under the common log-smooth and log-strongly-convex conditions, plus a growth condition on the 3rd-order derivative of the potential of target measures. This bound improves the best previously known $\tilde{O}(d/\epsilon)$ result and is optimal (in terms of order) in both dimension $d$ and accuracy tolerance $\epsilon$ for target measures satisfying the aforementioned assumptions. Our theoretical analysis is further validated by numerical experiments.
A Compact and Interpretable Convolutional Neural Network for Cross-Subject Driver Drowsiness Detection from Single-Channel EEG
May 30, 2021
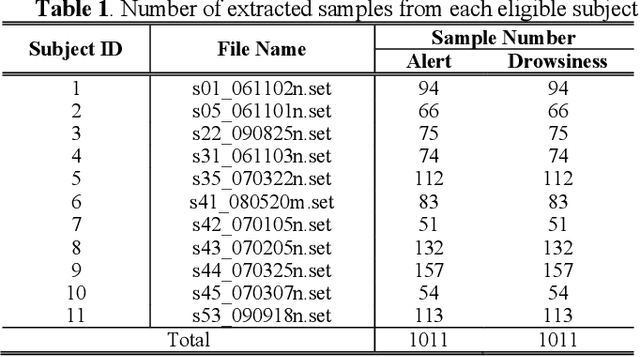


Driver drowsiness is one of main factors leading to road fatalities and hazards in the transportation industry. Electroencephalography (EEG) has been considered as one of the best physiological signals to detect drivers drowsy states, since it directly measures neurophysiological activities in the brain. However, designing a calibration-free system for driver drowsiness detection with EEG is still a challenging task, as EEG suffers from serious mental and physical drifts across different subjects. In this paper, we propose a compact and interpretable Convolutional Neural Network (CNN) to discover shared EEG features across different subjects for driver drowsiness detection. We incorporate the Global Average Pooling (GAP) layer in the model structure, allowing the Class Activation Map (CAM) method to be used for localizing regions of the input signal that contribute most for classification. Results show that the proposed model can achieve an average accuracy of 73.22% on 11 subjects for 2-class cross-subject EEG signal classification, which is higher than conventional machine learning methods and other state-of-art deep learning methods. It is revealed by the visualization technique that the model has learned biologically explainable features, e.g., Alpha spindles and Theta burst, as evidence for the drowsy state. It is also interesting to see that the model uses artifacts that usually dominate the wakeful EEG, e.g., muscle artifacts and sensor drifts, to recognize the alert state. The proposed model illustrates a potential direction to use CNN models as a powerful tool to discover shared features related to different mental states across different subjects from EEG signals.