 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDBMIF: a deep balanced multimodal iterative fusion framework for air- and bone-conduction speech enhancement
Mar 03, 2026The performance of conventional speech enhancement systems degrades sharply in extremely low signal-to-noise ratio (SNR) environments where air-conduction (AC) microphones are overwhelmed by ambient noise. Although bone-conduction (BC) sensors offer complementary, noise-tolerant information, existing fusion approaches struggle to maintain consistent performance across a wide range of SNR conditions. To address this limitation, we propose the Deep Balanced Multimodal Iterative Fusion Framework (DBMIF), a three-branch architecture designed to reconstruct high-fidelity speech through rigorous cross-modal interaction. Specifically, grounded in a multi-scale interactive encoder-decoder backbone, the framework orchestrates an iterative attention module and a cross-branch gated module to facilitate adaptive weighting and bidirectional exchange. To complement this dynamic interaction, a balanced-interaction bottleneck is further integrated to learn a compact, stable fused representation. Extensive experiments demonstrate that DBMIF achieves competitive performance compared with recent unimodal and multimodal baselines in both speech quality and intelligibility across diverse noise types. In downstream ASR tasks, the proposed method reduces the character error rate by at least 2.5 percent compared to competing approaches. These results confirm that DBMIF effectively harnesses the robustness of BC speech while preserving the naturalness of AC speech, ensuring reliability in real-world scenarios. The source code is publicly available at github.com/wyl516w/dbmif.
Standardized Evaluation of Automatic Methods for Perivascular Spaces Segmentation in MRI -- MICCAI 2024 Challenge Results
Dec 20, 2025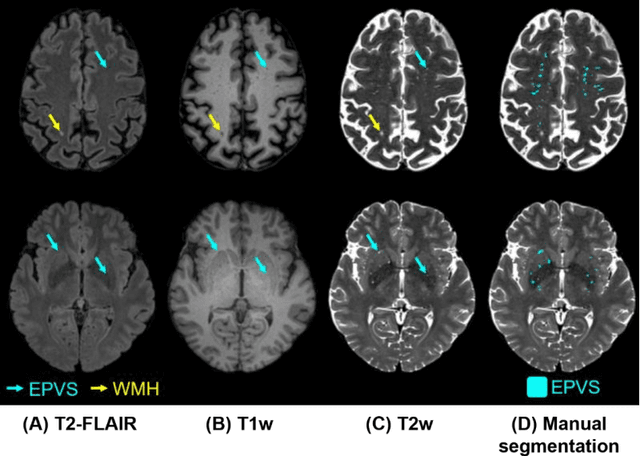
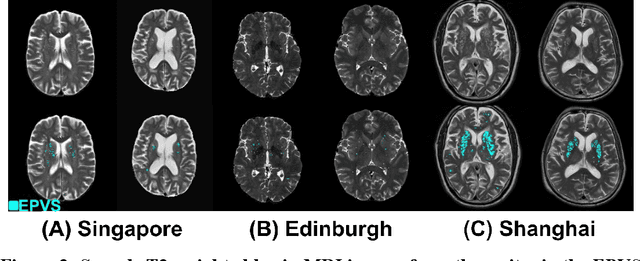
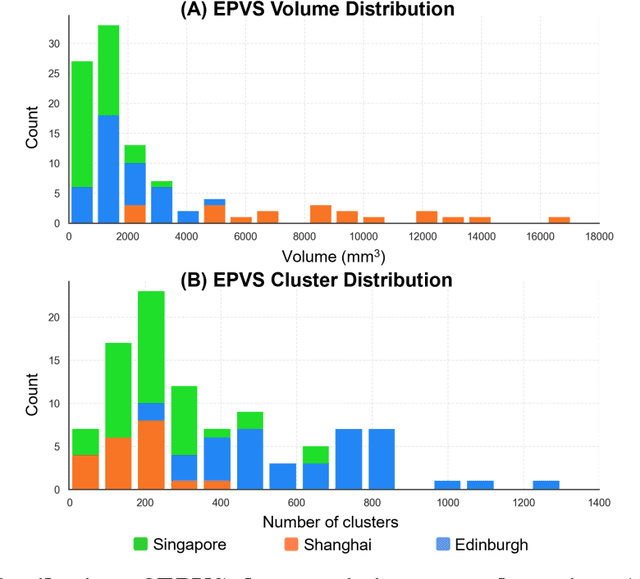
Perivascular spaces (PVS), when abnormally enlarged and visible in magnetic resonance imaging (MRI) structural sequences, are important imaging markers of cerebral small vessel disease and potential indicators of neurodegenerative conditions. Despite their clinical significance, automatic enlarged PVS (EPVS) segmentation remains challenging due to their small size, variable morphology, similarity with other pathological features, and limited annotated datasets. This paper presents the EPVS Challenge organized at MICCAI 2024, which aims to advance the development of automated algorithms for EPVS segmentation across multi-site data. We provided a diverse dataset comprising 100 training, 50 validation, and 50 testing scans collected from multiple international sites (UK, Singapore, and China) with varying MRI protocols and demographics. All annotations followed the STRIVE protocol to ensure standardized ground truth and covered the full brain parenchyma. Seven teams completed the full challenge, implementing various deep learning approaches primarily based on U-Net architectures with innovations in multi-modal processing, ensemble strategies, and transformer-based components. Performance was evaluated using dice similarity coefficient, absolute volume difference, recall, and precision metrics. The winning method employed MedNeXt architecture with a dual 2D/3D strategy for handling varying slice thicknesses. The top solutions showed relatively good performance on test data from seen datasets, but significant degradation of performance was observed on the previously unseen Shanghai cohort, highlighting cross-site generalization challenges due to domain shift. This challenge establishes an important benchmark for EPVS segmentation methods and underscores the need for the continued development of robust algorithms that can generalize in diverse clinical settings.
Brain-JEPA: Brain Dynamics Foundation Model with Gradient Positioning and Spatiotemporal Masking
Sep 28, 2024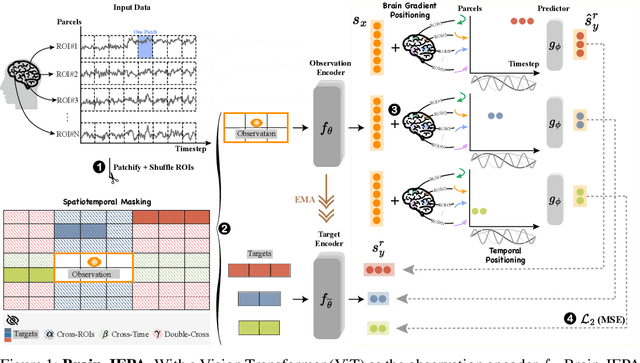
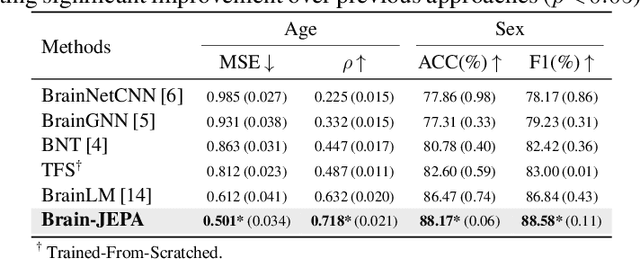
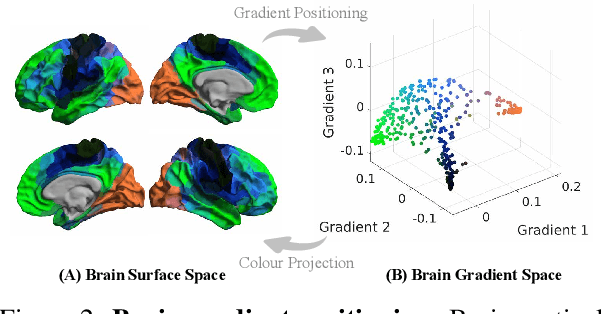
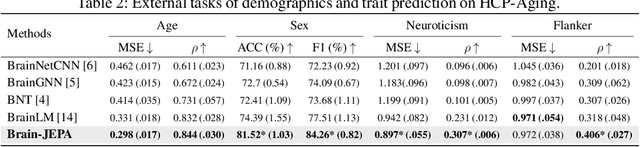
We introduce Brain-JEPA, a brain dynamics foundation model with the Joint-Embedding Predictive Architecture (JEPA). This pioneering model achieves state-of-the-art performance in demographic prediction, disease diagnosis/prognosis, and trait prediction through fine-tuning. Furthermore, it excels in off-the-shelf evaluations (e.g., linear probing) and demonstrates superior generalizability across different ethnic groups, surpassing the previous large model for brain activity significantly. Brain-JEPA incorporates two innovative techniques: Brain Gradient Positioning and Spatiotemporal Masking. Brain Gradient Positioning introduces a functional coordinate system for brain functional parcellation, enhancing the positional encoding of different Regions of Interest (ROIs). Spatiotemporal Masking, tailored to the unique characteristics of fMRI data, addresses the challenge of heterogeneous time-series patches. These methodologies enhance model performance and advance our understanding of the neural circuits underlying cognition. Overall, Brain-JEPA is paving the way to address pivotal questions of building brain functional coordinate system and masking brain activity at the AI-neuroscience interface, and setting a potentially new paradigm in brain activity analysis through downstream adaptation.
Prompt Your Brain: Scaffold Prompt Tuning for Efficient Adaptation of fMRI Pre-trained Model
Aug 20, 2024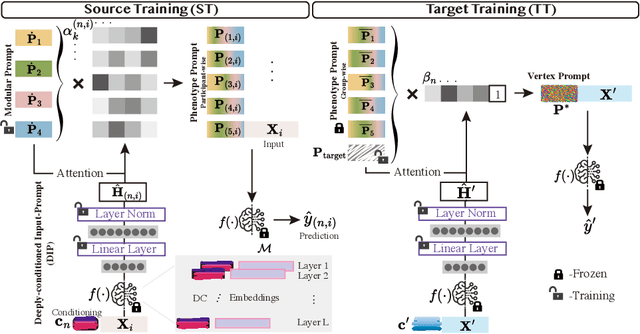
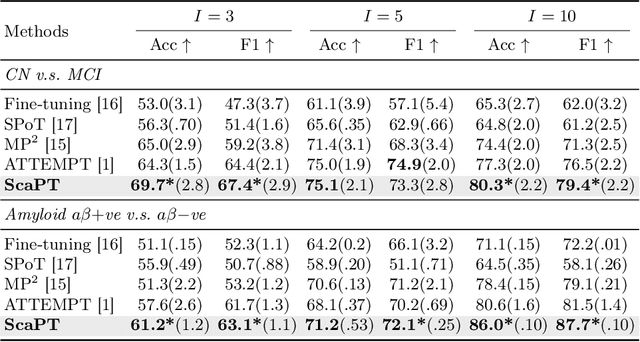
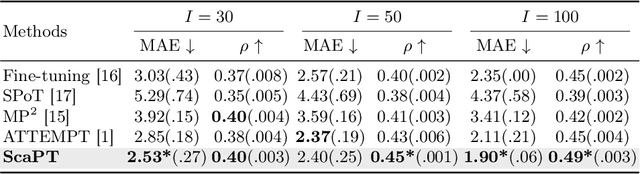
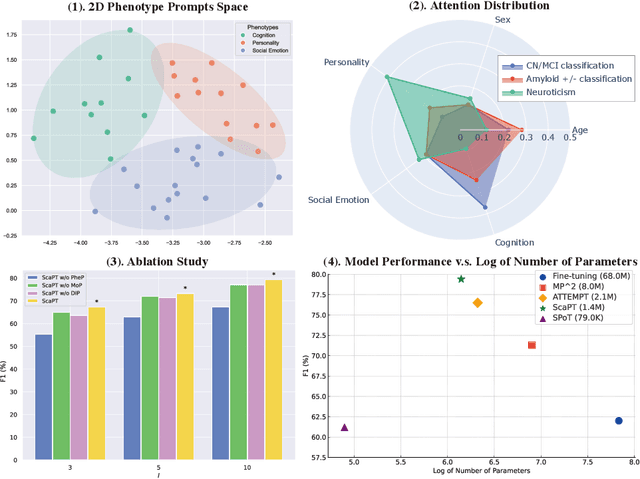
We introduce Scaffold Prompt Tuning (ScaPT), a novel prompt-based framework for adapting large-scale functional magnetic resonance imaging (fMRI) pre-trained models to downstream tasks, with high parameter efficiency and improved performance compared to fine-tuning and baselines for prompt tuning. The full fine-tuning updates all pre-trained parameters, which may distort the learned feature space and lead to overfitting with limited training data which is common in fMRI fields. In contrast, we design a hierarchical prompt structure that transfers the knowledge learned from high-resource tasks to low-resource ones. This structure, equipped with a Deeply-conditioned Input-Prompt (DIP) mapping module, allows for efficient adaptation by updating only 2% of the trainable parameters. The framework enhances semantic interpretability through attention mechanisms between inputs and prompts, and it clusters prompts in the latent space in alignment with prior knowledge. Experiments on public resting state fMRI datasets reveal ScaPT outperforms fine-tuning and multitask-based prompt tuning in neurodegenerative diseases diagnosis/prognosis and personality trait prediction, even with fewer than 20 participants. It highlights ScaPT's efficiency in adapting pre-trained fMRI models to low-resource tasks.
Mixup Your Own Pairs
Sep 29, 2023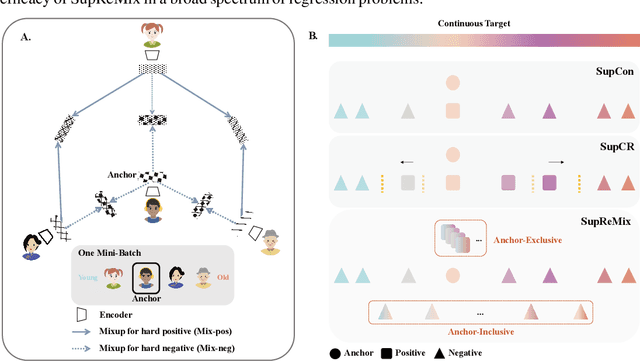
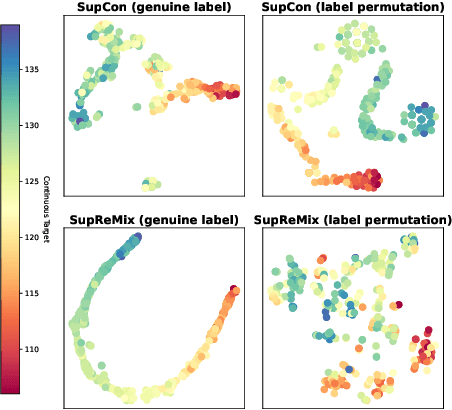
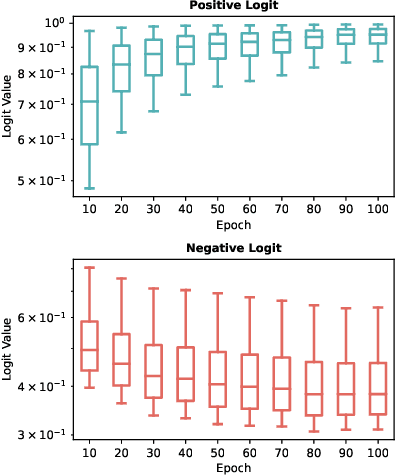
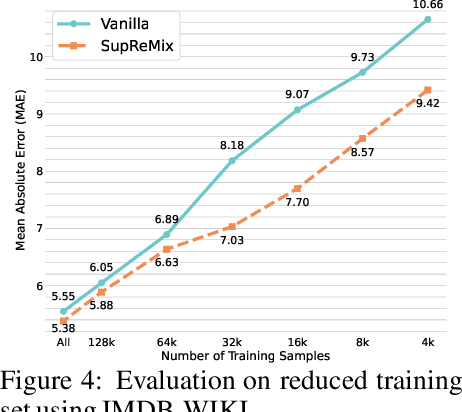
In representation learning, regression has traditionally received less attention than classification. Directly applying representation learning techniques designed for classification to regression often results in fragmented representations in the latent space, yielding sub-optimal performance. In this paper, we argue that the potential of contrastive learning for regression has been overshadowed due to the neglect of two crucial aspects: ordinality-awareness and hardness. To address these challenges, we advocate "mixup your own contrastive pairs for supervised contrastive regression", instead of relying solely on real/augmented samples. Specifically, we propose Supervised Contrastive Learning for Regression with Mixup (SupReMix). It takes anchor-inclusive mixtures (mixup of the anchor and a distinct negative sample) as hard negative pairs and anchor-exclusive mixtures (mixup of two distinct negative samples) as hard positive pairs at the embedding level. This strategy formulates harder contrastive pairs by integrating richer ordinal information. Through extensive experiments on six regression datasets including 2D images, volumetric images, text, tabular data, and time-series signals, coupled with theoretical analysis, we demonstrate that SupReMix pre-training fosters continuous ordered representations of regression data, resulting in significant improvement in regression performance. Furthermore, SupReMix is superior to other approaches in a range of regression challenges including transfer learning, imbalanced training data, and scenarios with fewer training samples.
Beyond the Snapshot: Brain Tokenized Graph Transformer for Longitudinal Brain Functional Connectome Embedding
Jul 13, 2023

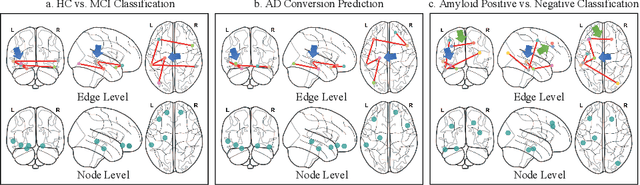
Under the framework of network-based neurodegeneration, brain functional connectome (FC)-based Graph Neural Networks (GNN) have emerged as a valuable tool for the diagnosis and prognosis of neurodegenerative diseases such as Alzheimer's disease (AD). However, these models are tailored for brain FC at a single time point instead of characterizing FC trajectory. Discerning how FC evolves with disease progression, particularly at the predementia stages such as cognitively normal individuals with amyloid deposition or individuals with mild cognitive impairment (MCI), is crucial for delineating disease spreading patterns and developing effective strategies to slow down or even halt disease advancement. In this work, we proposed the first interpretable framework for brain FC trajectory embedding with application to neurodegenerative disease diagnosis and prognosis, namely Brain Tokenized Graph Transformer (Brain TokenGT). It consists of two modules: 1) Graph Invariant and Variant Embedding (GIVE) for generation of node and spatio-temporal edge embeddings, which were tokenized for downstream processing; 2) Brain Informed Graph Transformer Readout (BIGTR) which augments previous tokens with trainable type identifiers and non-trainable node identifiers and feeds them into a standard transformer encoder to readout. We conducted extensive experiments on two public longitudinal fMRI datasets of the AD continuum for three tasks, including differentiating MCI from controls, predicting dementia conversion in MCI, and classification of amyloid positive or negative cognitively normal individuals. Based on brain FC trajectory, the proposed Brain TokenGT approach outperformed all the other benchmark models and at the same time provided excellent interpretability. The code is available at https://github.com/ZijianD/Brain-TokenGT.git
Pruning variable selection ensembles
Apr 26, 2017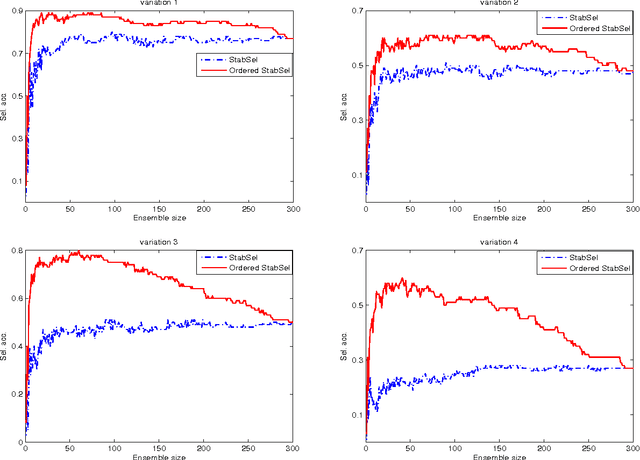
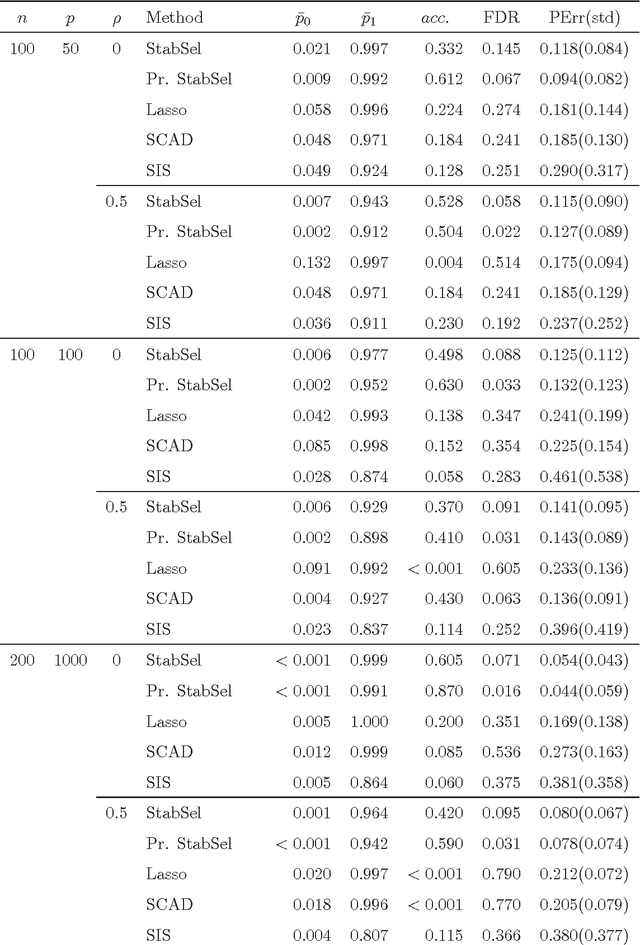
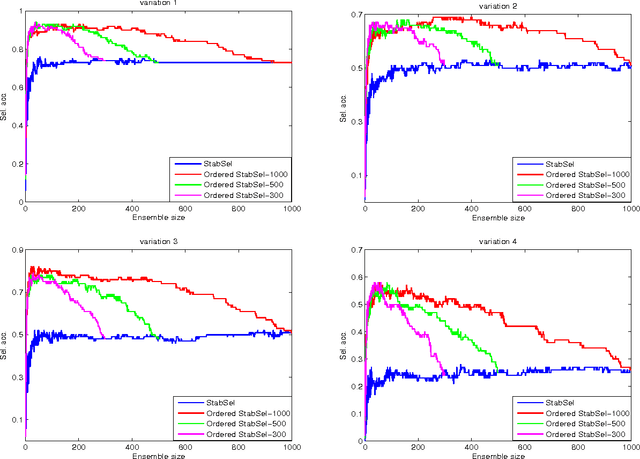
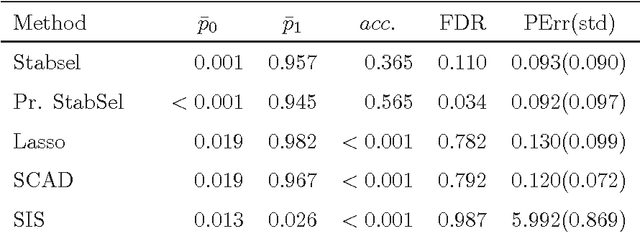
In the context of variable selection, ensemble learning has gained increasing interest due to its great potential to improve selection accuracy and to reduce false discovery rate. A novel ordering-based selective ensemble learning strategy is designed in this paper to obtain smaller but more accurate ensembles. In particular, a greedy sorting strategy is proposed to rearrange the order by which the members are included into the integration process. Through stopping the fusion process early, a smaller subensemble with higher selection accuracy can be obtained. More importantly, the sequential inclusion criterion reveals the fundamental strength-diversity trade-off among ensemble members. By taking stability selection (abbreviated as StabSel) as an example, some experiments are conducted with both simulated and real-world data to examine the performance of the novel algorithm. Experimental results demonstrate that pruned StabSel generally achieves higher selection accuracy and lower false discovery rates than StabSel and several other benchmark methods.