 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Analytical Formula for Spectrum Reconstruction
May 30, 2020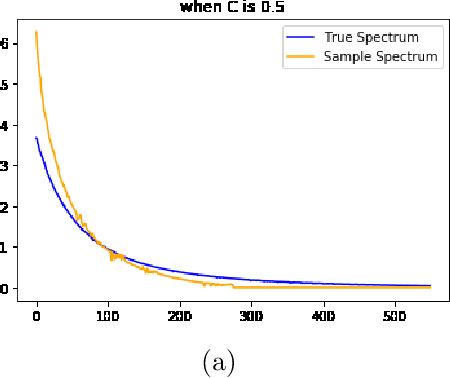
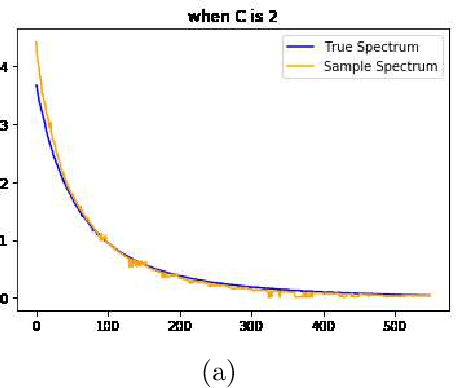
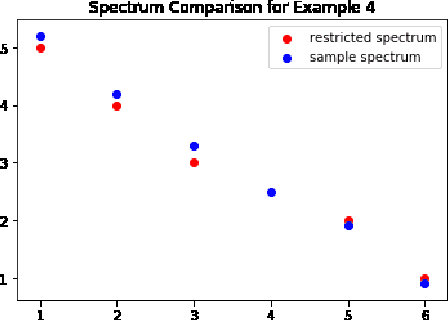
We study the spectrum reconstruction technique. As is known to all, eigenvalues play an important role in many research fields and are foundation to many practical techniques such like PCA(Principal Component Analysis). We believe that related algorithms should perform better with more accurate spectrum estimation. There was an approximation formula proposed, however, they didn't give any proof. In our research, we show why the formula works. And when both number of features and dimension of space go to infinity, we find the order of error for the approximation formula, which is related to a constant $c$-the ratio of dimension of space and number of features.
A cost-reducing partial labeling estimator in text classification problem
Jun 10, 2019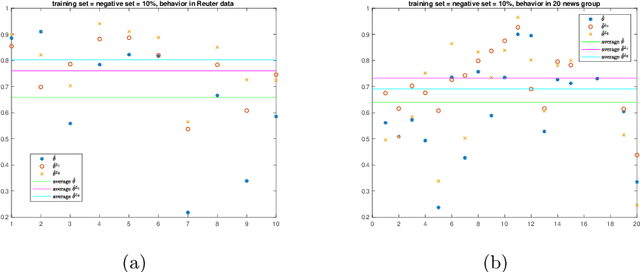
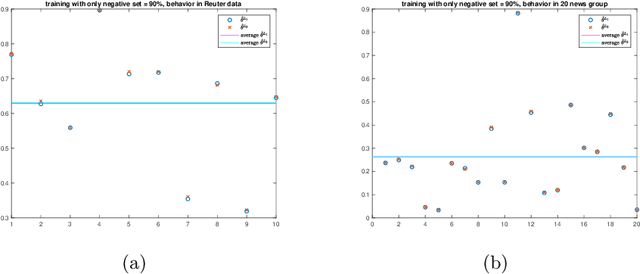
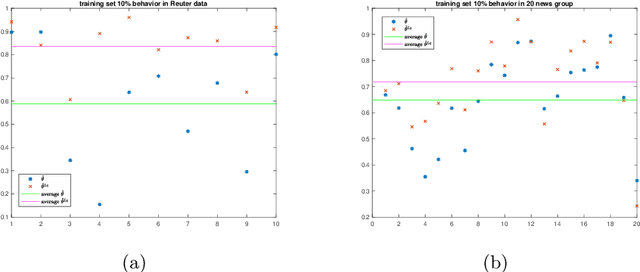
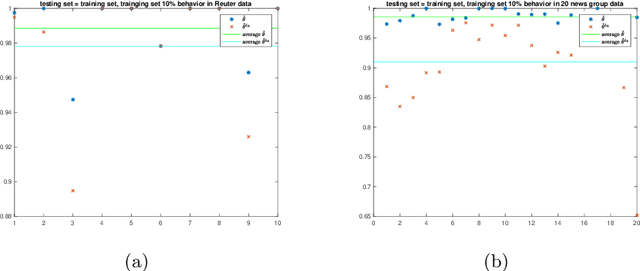
We propose a new approach to address the text classification problems when learning with partial labels is beneficial. Instead of offering each training sample a set of candidate labels, we assign negative-oriented labels to the ambiguous training examples if they are unlikely fall into certain classes. We construct our new maximum likelihood estimators with self-correction property, and prove that under some conditions, our estimators converge faster. Also we discuss the advantages of applying one of our estimator to a fully supervised learning problem. The proposed method has potential applicability in many areas, such as crowdsourcing, natural language processing and medical image analysis.
Naive Bayes with Correlation Factor for Text Classification Problem
May 08, 2019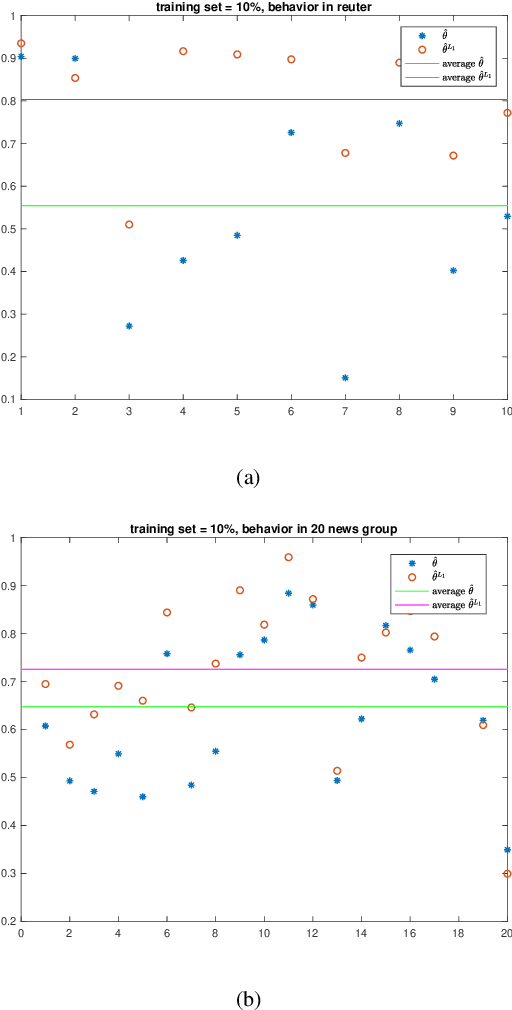
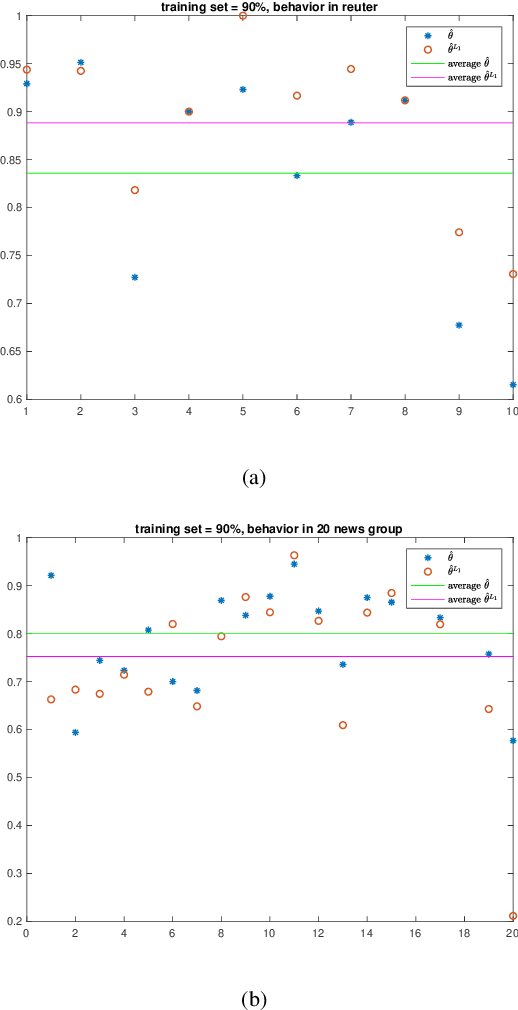
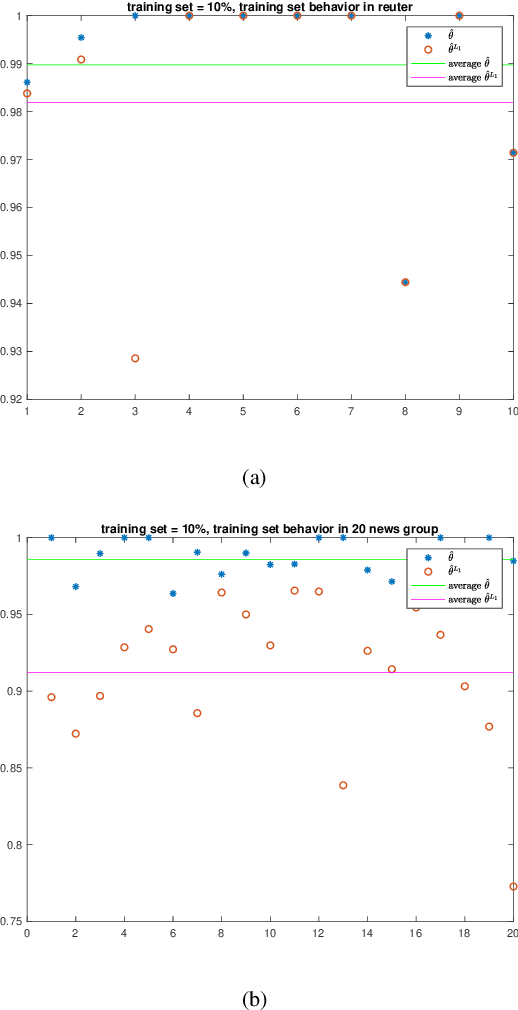
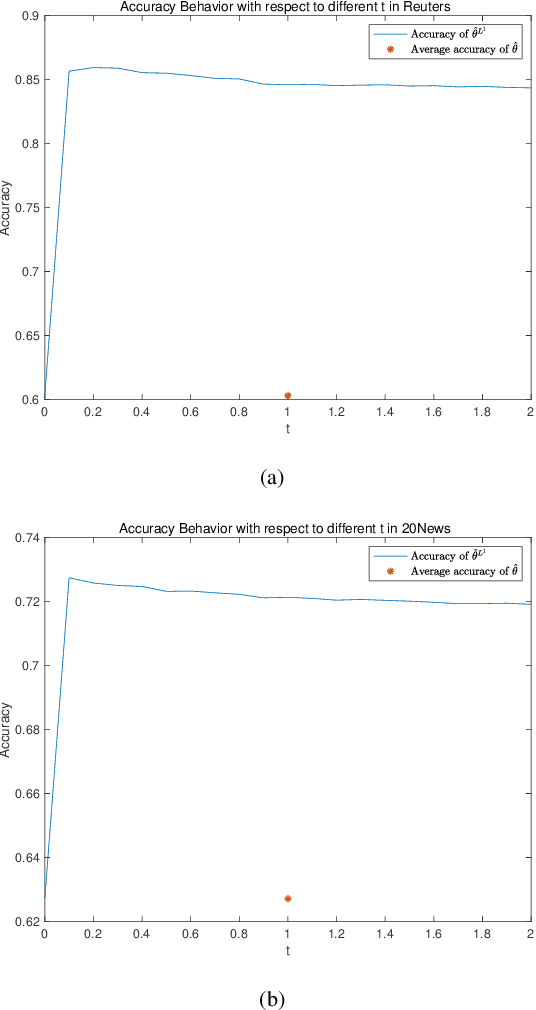
Naive Bayes estimator is widely used in text classification problems. However, it doesn't perform well with small-size training dataset. We propose a new method based on Naive Bayes estimator to solve this problem. A correlation factor is introduced to incorporate the correlation among different classes. Experimental results show that our estimator achieves a better accuracy compared with traditional Naive Bayes in real world data.