 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHybrid Reinforcement Learning Framework for Mixed-Variable Problems
May 30, 2024Optimization problems characterized by both discrete and continuous variables are common across various disciplines, presenting unique challenges due to their complex solution landscapes and the difficulty of navigating mixed-variable spaces effectively. To Address these challenges, we introduce a hybrid Reinforcement Learning (RL) framework that synergizes RL for discrete variable selection with Bayesian Optimization for continuous variable adjustment. This framework stands out by its strategic integration of RL and continuous optimization techniques, enabling it to dynamically adapt to the problem's mixed-variable nature. By employing RL for exploring discrete decision spaces and Bayesian Optimization to refine continuous parameters, our approach not only demonstrates flexibility but also enhances optimization performance. Our experiments on synthetic functions and real-world machine learning hyperparameter tuning tasks reveal that our method consistently outperforms traditional RL, random search, and standalone Bayesian optimization in terms of effectiveness and efficiency.
Personalized Entity Resolution with Dynamic Heterogeneous Knowledge Graph Representations
Apr 14, 2021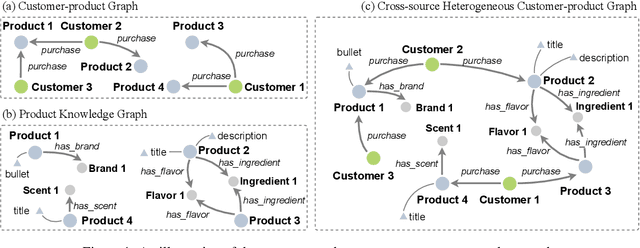
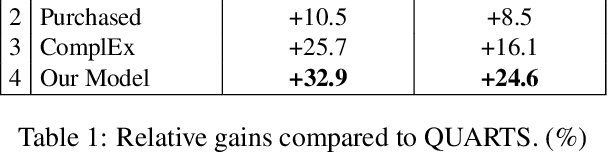
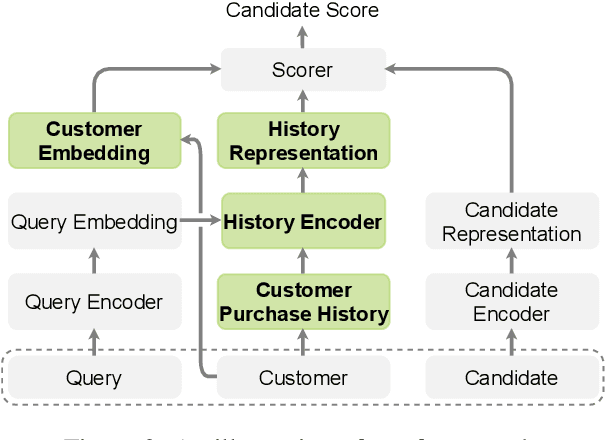
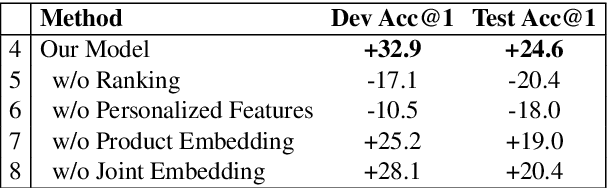
The growing popularity of Virtual Assistants poses new challenges for Entity Resolution, the task of linking mentions in text to their referent entities in a knowledge base. Specifically, in the shopping domain, customers tend to use implicit utterances (e.g., "organic milk") rather than explicit names, leading to a large number of candidate products. Meanwhile, for the same query, different customers may expect different results. For example, with "add milk to my cart", a customer may refer to a certain organic product, while some customers may want to re-order products they regularly purchase. To address these issues, we propose a new framework that leverages personalized features to improve the accuracy of product ranking. We first build a cross-source heterogeneous knowledge graph from customer purchase history and product knowledge graph to jointly learn customer and product embeddings. After that, we incorporate product, customer, and history representations into a neural reranking model to predict which candidate is most likely to be purchased for a specific customer. Experiments show that our model substantially improves the accuracy of the top ranked candidates by 24.6% compared to the state-of-the-art product search model.
A cost-reducing partial labeling estimator in text classification problem
Jun 10, 2019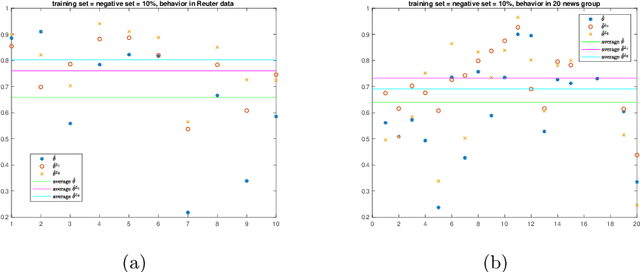
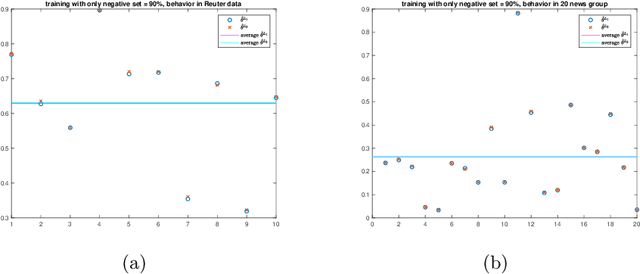
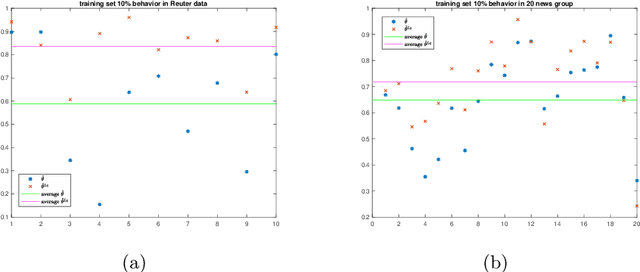
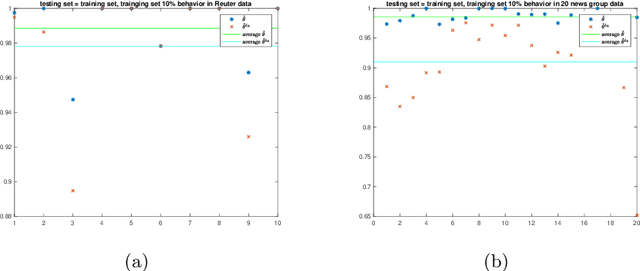
We propose a new approach to address the text classification problems when learning with partial labels is beneficial. Instead of offering each training sample a set of candidate labels, we assign negative-oriented labels to the ambiguous training examples if they are unlikely fall into certain classes. We construct our new maximum likelihood estimators with self-correction property, and prove that under some conditions, our estimators converge faster. Also we discuss the advantages of applying one of our estimator to a fully supervised learning problem. The proposed method has potential applicability in many areas, such as crowdsourcing, natural language processing and medical image analysis.
Naive Bayes with Correlation Factor for Text Classification Problem
May 08, 2019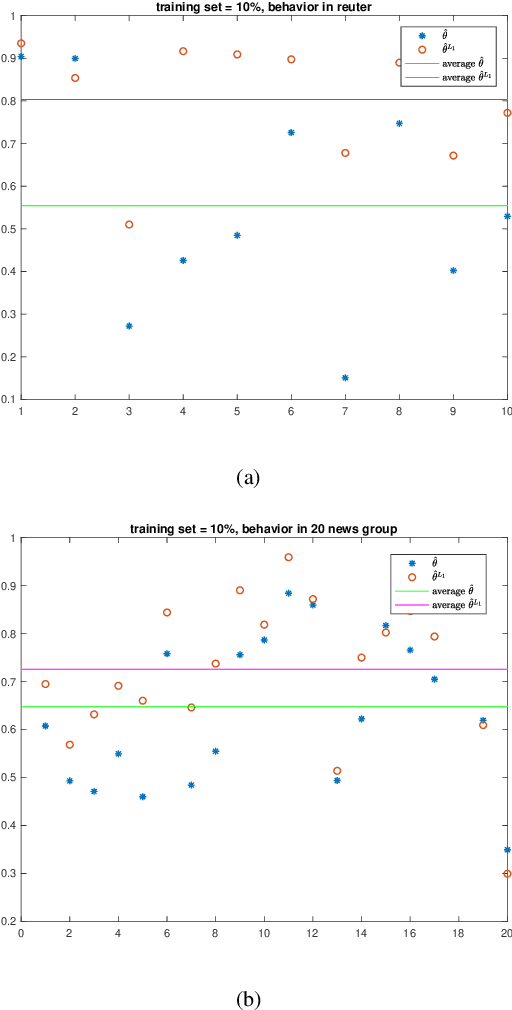
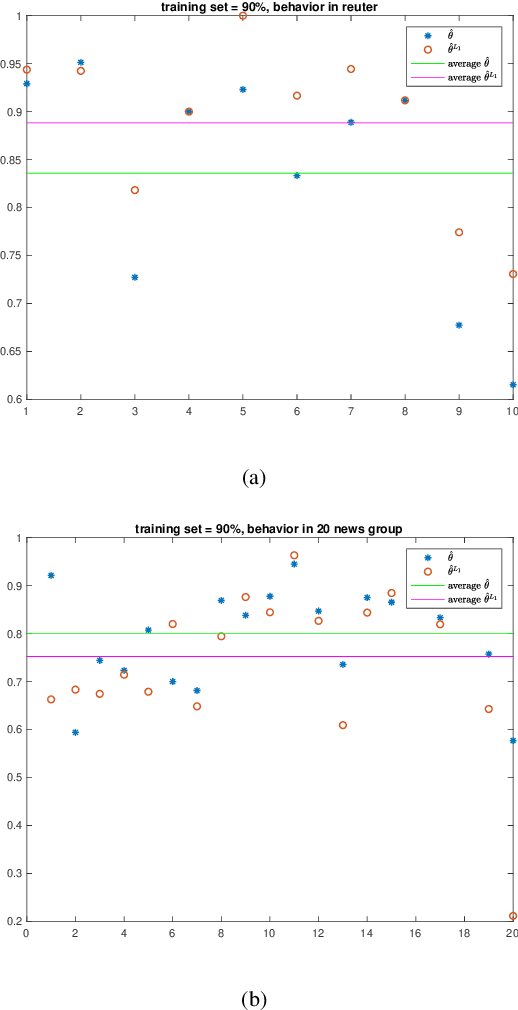
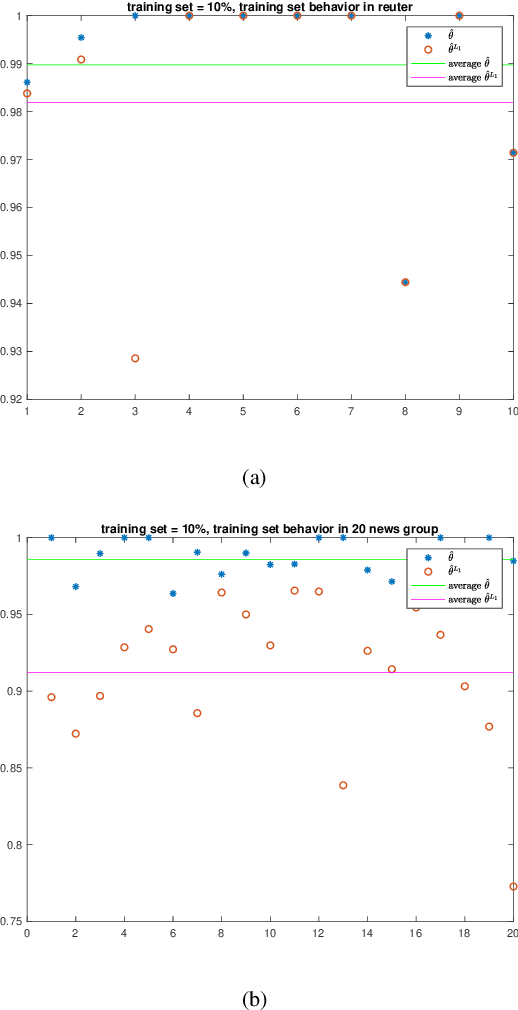
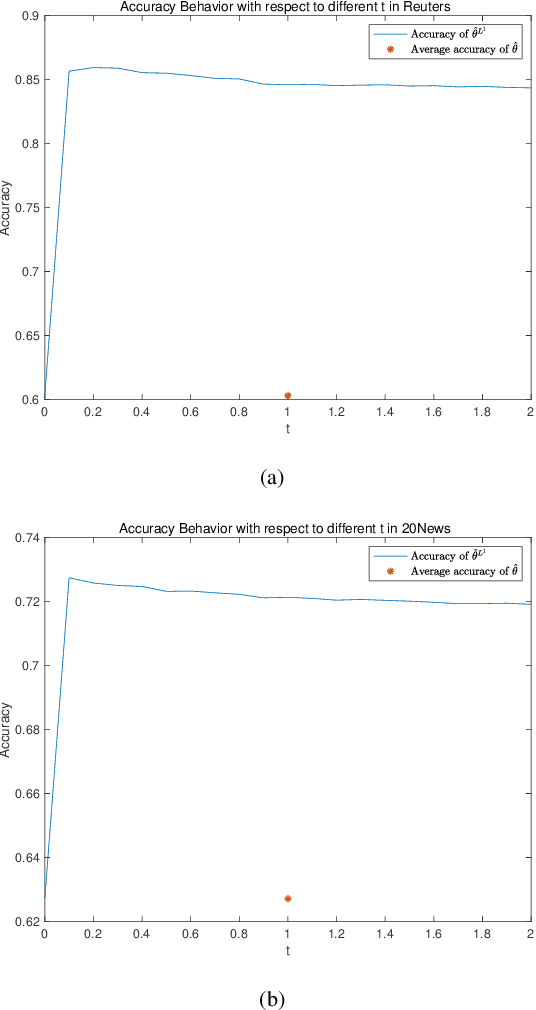
Naive Bayes estimator is widely used in text classification problems. However, it doesn't perform well with small-size training dataset. We propose a new method based on Naive Bayes estimator to solve this problem. A correlation factor is introduced to incorporate the correlation among different classes. Experimental results show that our estimator achieves a better accuracy compared with traditional Naive Bayes in real world data.
Centroid estimation based on symmetric KL divergence for Multinomial text classification problem
Oct 24, 2018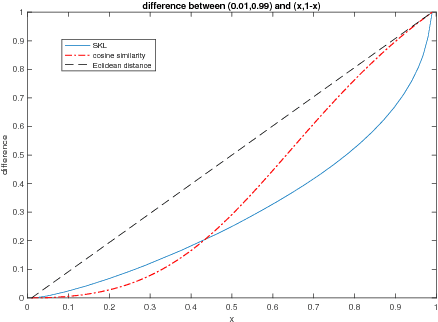
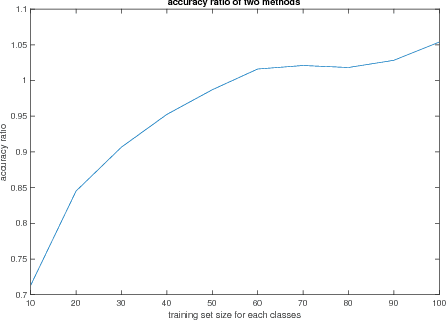
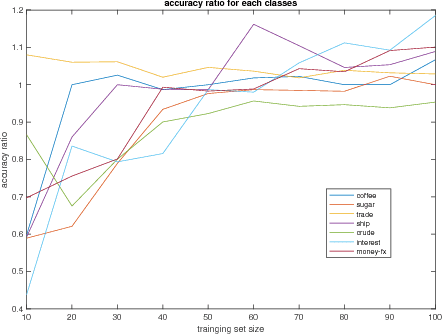

We define a new method to estimate centroid for text classification based on the symmetric KL-divergence between the distribution of words in training documents and their class centroids. Experiments on several standard data sets indicate that the new method achieves substantial improvements over the traditional classifiers.
Convergence of Krasulina Scheme
Aug 28, 2018
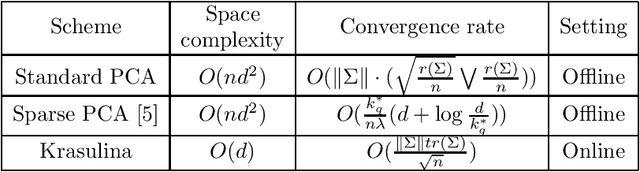
Principal component analysis (PCA) is one of the most commonly used statistical procedures with a wide range of applications. Consider the points $X_1, X_2,..., X_n$ are vectors drawn i.i.d. from a distribution with mean zero and covariance $\Sigma$, where $\Sigma$ is unknown. Let $A_n = X_nX_n^T$, then $E[A_n] = \Sigma$. This paper consider the problem of finding the least eigenvalue and eigenvector of matrix $\Sigma$. A classical such estimator are due to Krasulina\cite{krasulina_method_1969}. We are going to state the convergence proof of Krasulina for the least eigenvalue and corresponding eigenvector, and then find their convergence rate.