 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCommunicative Learning with Natural Gestures for Embodied Navigation Agents with Human-in-the-Scene
Paper and Code
Aug 05, 2021
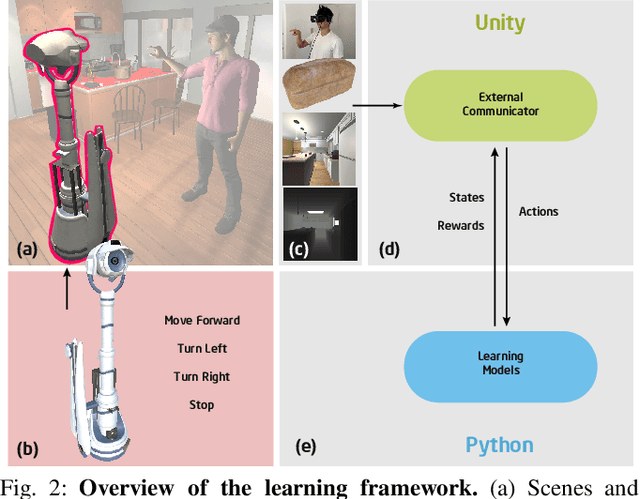
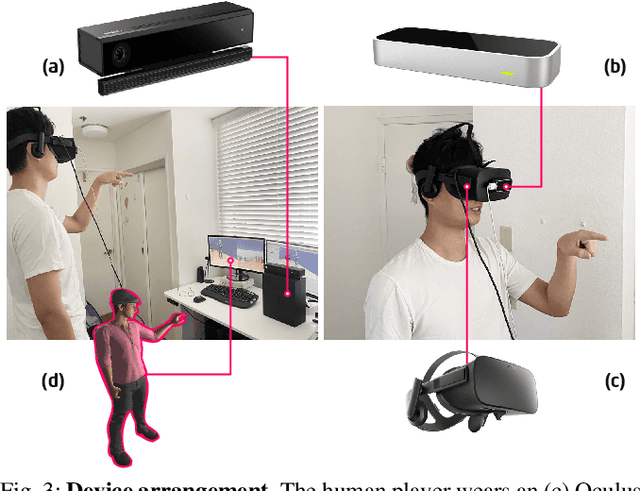
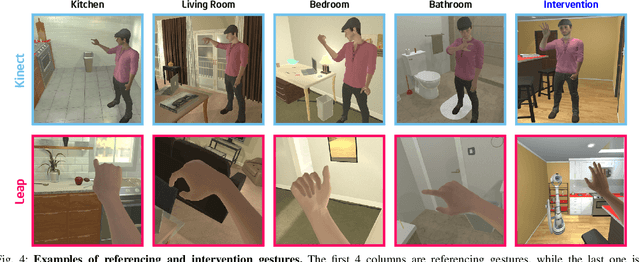
Human-robot collaboration is an essential research topic in artificial intelligence (AI), enabling researchers to devise cognitive AI systems and affords an intuitive means for users to interact with the robot. Of note, communication plays a central role. To date, prior studies in embodied agent navigation have only demonstrated that human languages facilitate communication by instructions in natural languages. Nevertheless, a plethora of other forms of communication is left unexplored. In fact, human communication originated in gestures and oftentimes is delivered through multimodal cues, e.g. "go there" with a pointing gesture. To bridge the gap and fill in the missing dimension of communication in embodied agent navigation, we propose investigating the effects of using gestures as the communicative interface instead of verbal cues. Specifically, we develop a VR-based 3D simulation environment, named Ges-THOR, based on AI2-THOR platform. In this virtual environment, a human player is placed in the same virtual scene and shepherds the artificial agent using only gestures. The agent is tasked to solve the navigation problem guided by natural gestures with unknown semantics; we do not use any predefined gestures due to the diversity and versatile nature of human gestures. We argue that learning the semantics of natural gestures is mutually beneficial to learning the navigation task--learn to communicate and communicate to learn. In a series of experiments, we demonstrate that human gesture cues, even without predefined semantics, improve the object-goal navigation for an embodied agent, outperforming various state-of-the-art methods.