 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVideo compression with low complexity CNN-based spatial resolution adaptation
Paper and Code
Jul 29, 2020
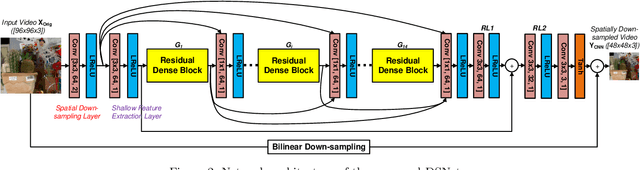
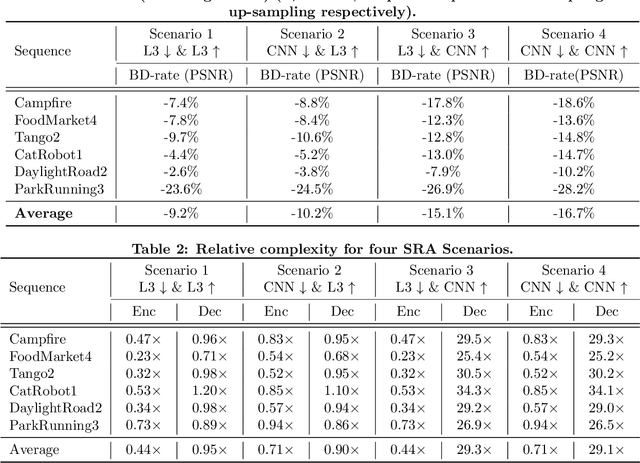
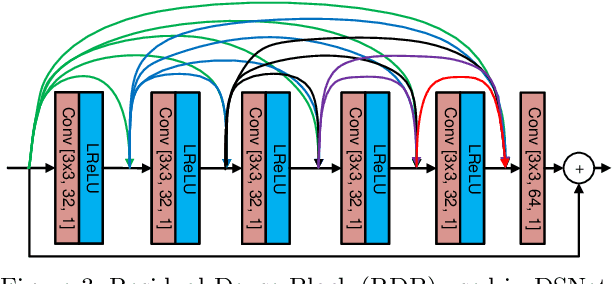
It has recently been demonstrated that spatial resolution adaptation can be integrated within video compression to improve overall coding performance by spatially down-sampling before encoding and super-resolving at the decoder. Significant improvements have been reported when convolutional neural networks (CNNs) were used to perform the resolution up-sampling. However, this approach suffers from high complexity at the decoder due to the employment of CNN-based super-resolution. In this paper, a novel framework is proposed which supports the flexible allocation of complexity between the encoder and decoder. This approach employs a CNN model for video down-sampling at the encoder and uses a Lanczos3 filter to reconstruct full resolution at the decoder. The proposed method was integrated into the HEVC HM 16.20 software and evaluated on JVET UHD test sequences using the All Intra configuration. The experimental results demonstrate the potential of the proposed approach, with significant bitrate savings (more than 10%) over the original HEVC HM, coupled with reduced computational complexity at both encoder (29%) and decoder (10%).