 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhy Does ChatGPT Fall Short in Answering Questions Faithfully?
Paper and Code
Apr 20, 2023
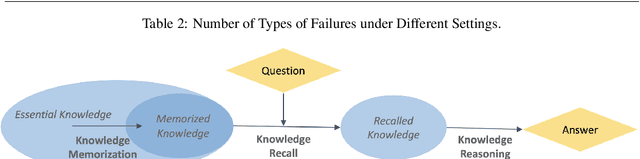

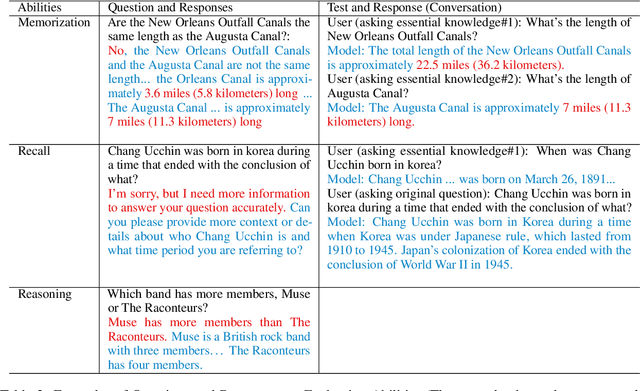
Recent advancements in Large Language Models, such as ChatGPT, have demonstrated significant potential to impact various aspects of human life. However, ChatGPT still faces challenges in aspects like faithfulness. Taking question answering as a representative application, we seek to understand why ChatGPT falls short in answering questions faithfully. To address this question, we attempt to analyze the failures of ChatGPT in complex open-domain question answering and identifies the abilities under the failures. Specifically, we categorize ChatGPT's failures into four types: comprehension, factualness, specificity, and inference. We further pinpoint three critical abilities associated with QA failures: knowledge memorization, knowledge association, and knowledge reasoning. Additionally, we conduct experiments centered on these abilities and propose potential approaches to enhance faithfulness. The results indicate that furnishing the model with fine-grained external knowledge, hints for knowledge association, and guidance for reasoning can empower the model to answer questions more faithfully.