 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuantifying Association Capabilities of Large Language Models and Its Implications on Privacy Leakage
May 22, 2023



The advancement of large language models (LLMs) brings notable improvements across various applications, while simultaneously raising concerns about potential private data exposure. One notable capability of LLMs is their ability to form associations between different pieces of information, but this raises concerns when it comes to personally identifiable information (PII). This paper delves into the association capabilities of language models, aiming to uncover the factors that influence their proficiency in associating information. Our study reveals that as models scale up, their capacity to associate entities/information intensifies, particularly when target pairs demonstrate shorter co-occurrence distances or higher co-occurrence frequencies. However, there is a distinct performance gap when associating commonsense knowledge versus PII, with the latter showing lower accuracy. Despite the proportion of accurately predicted PII being relatively small, LLMs still demonstrate the capability to predict specific instances of email addresses and phone numbers when provided with appropriate prompts. These findings underscore the potential risk to PII confidentiality posed by the evolving capabilities of LLMs, especially as they continue to expand in scale and power.
Are Large Pre-Trained Language Models Leaking Your Personal Information?
May 25, 2022
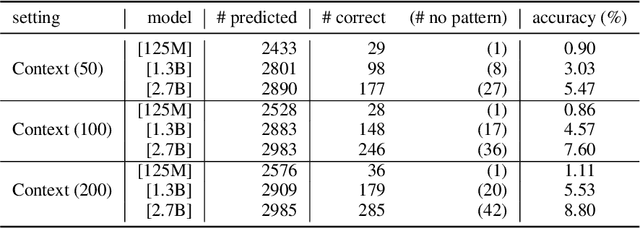
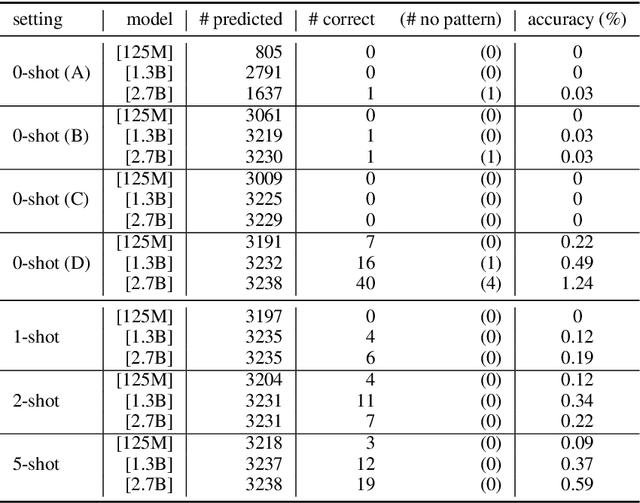
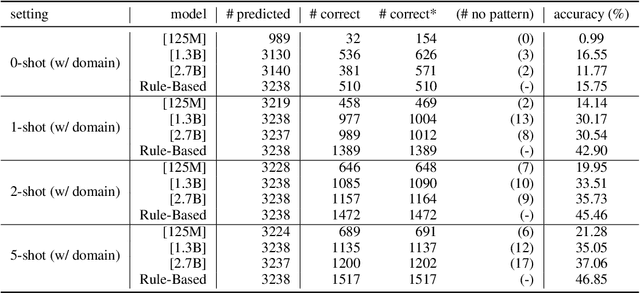
Large Pre-Trained Language Models (PLMs) have facilitated and dominated many NLP tasks in recent years. However, despite the great success of PLMs, there are also privacy concerns brought with PLMs. For example, recent studies show that PLMs memorize a lot of training data, including sensitive information, while the information may be leaked unintentionally and be utilized by malicious attackers. In this paper, we propose to measure whether PLMs are prone to leaking personal information. Specifically, we attempt to query PLMs for email addresses with contexts of the email address or prompts containing the owner's name. We find that PLMs do leak personal information due to memorization. However, the risk of specific personal information being extracted by attackers is low because the models are weak at associating the personal information with its owner. We hope this work could help the community to better understand the privacy risk of PLMs and bring new insights to make PLMs safe.
CDM: Combining Extraction and Generation for Definition Modeling
Nov 14, 2021
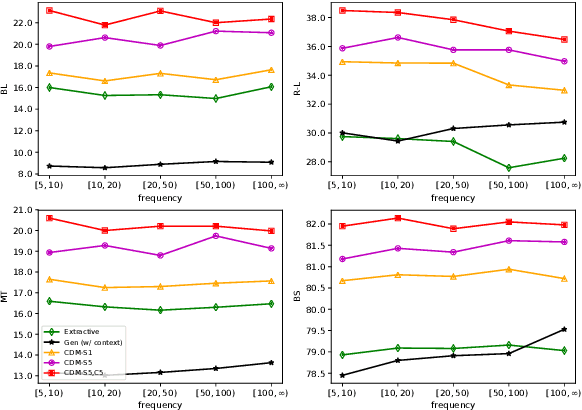
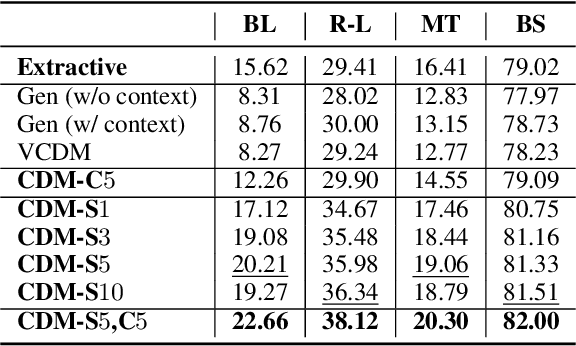
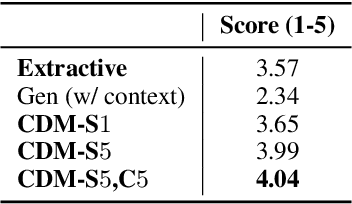
Definitions are essential for term understanding. Recently, there is an increasing interest in extracting and generating definitions of terms automatically. However, existing approaches for this task are either extractive or abstractive - definitions are either extracted from a corpus or generated by a language generation model. In this paper, we propose to combine extraction and generation for definition modeling: first extract self- and correlative definitional information of target terms from the Web and then generate the final definitions by incorporating the extracted definitional information. Experiments demonstrate our framework can generate high-quality definitions for technical terms and outperform state-of-the-art models for definition modeling significantly.