 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAre Large Pre-Trained Language Models Leaking Your Personal Information?
Paper and Code

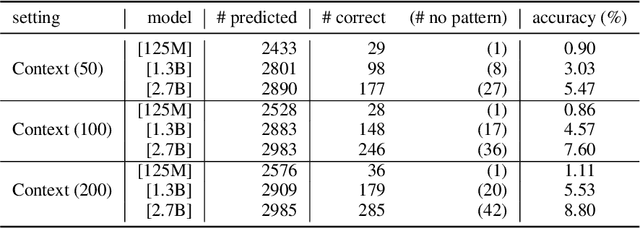
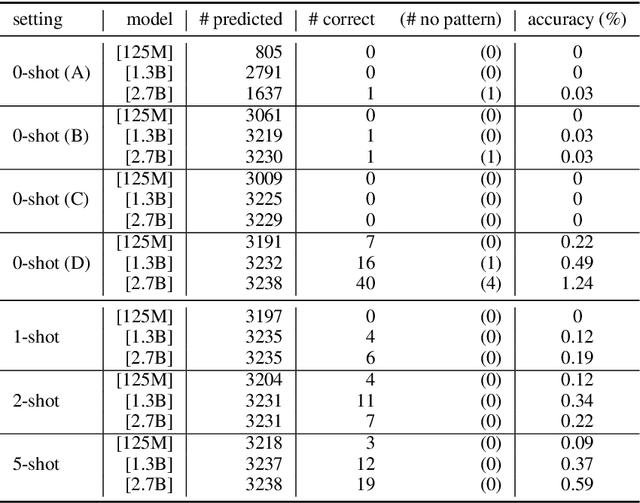
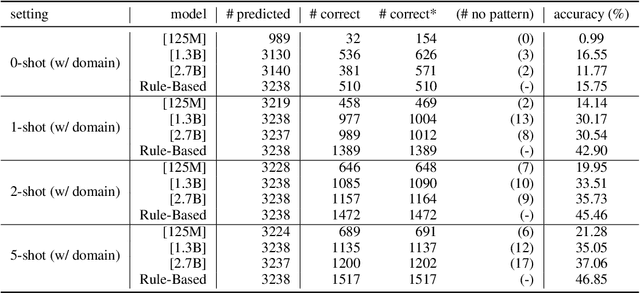
Large Pre-Trained Language Models (PLMs) have facilitated and dominated many NLP tasks in recent years. However, despite the great success of PLMs, there are also privacy concerns brought with PLMs. For example, recent studies show that PLMs memorize a lot of training data, including sensitive information, while the information may be leaked unintentionally and be utilized by malicious attackers. In this paper, we propose to measure whether PLMs are prone to leaking personal information. Specifically, we attempt to query PLMs for email addresses with contexts of the email address or prompts containing the owner's name. We find that PLMs do leak personal information due to memorization. However, the risk of specific personal information being extracted by attackers is low because the models are weak at associating the personal information with its owner. We hope this work could help the community to better understand the privacy risk of PLMs and bring new insights to make PLMs safe.