 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNew Solutions on LLM Acceleration, Optimization, and Application
Jun 16, 2024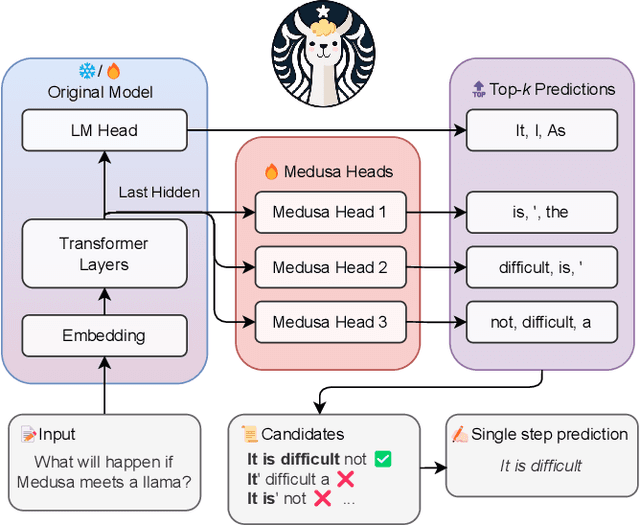
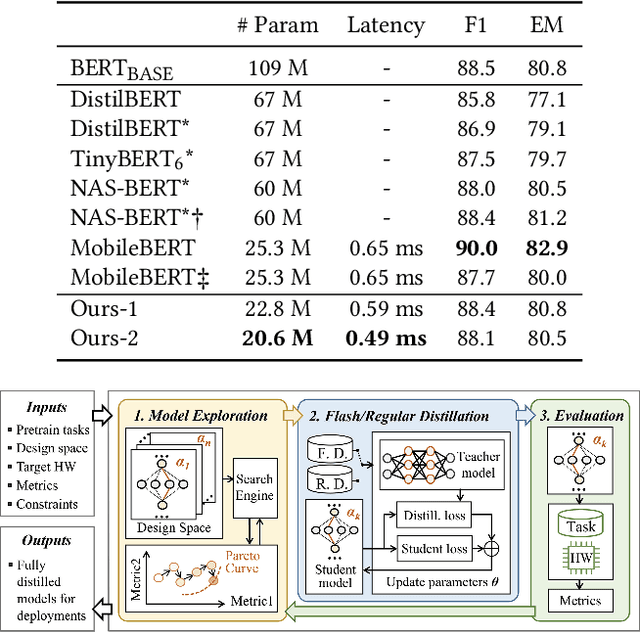
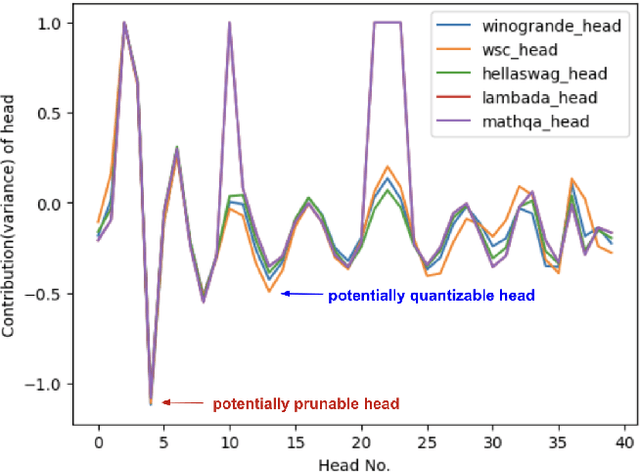
Large Language Models (LLMs) have become extremely potent instruments with exceptional capacities for comprehending and producing human-like text in a wide range of applications. However, the increasing size and complexity of LLMs present significant challenges in both training and deployment, leading to substantial computational and storage costs as well as heightened energy consumption. In this paper, we provide a review of recent advancements and research directions aimed at addressing these challenges and enhancing the efficiency of LLM-based systems. We begin by discussing algorithm-level acceleration techniques focused on optimizing LLM inference speed and resource utilization. We also explore LLM-hardware co-design strategies with a vision to improve system efficiency by tailoring hardware architectures to LLM requirements. Further, we delve into LLM-to-accelerator compilation approaches, which involve customizing hardware accelerators for efficient LLM deployment. Finally, as a case study to leverage LLMs for assisting circuit design, we examine LLM-aided design methodologies for an important task: High-Level Synthesis (HLS) functional verification, by creating a new dataset that contains a large number of buggy and bug-free codes, which can be essential for training LLMs to specialize on HLS verification and debugging. For each aspect mentioned above, we begin with a detailed background study, followed by the presentation of several novel solutions proposed to overcome specific challenges. We then outline future research directions to drive further advancements. Through these efforts, we aim to pave the way for more efficient and scalable deployment of LLMs across a diverse range of applications.
SnapKV: LLM Knows What You are Looking for Before Generation
Apr 22, 2024



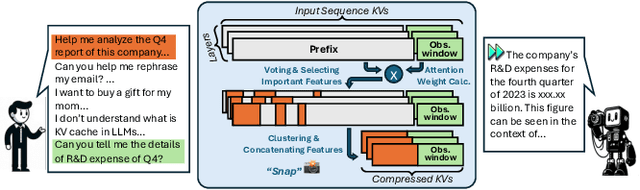
Large Language Models (LLMs) have made remarkable progress in processing extensive contexts, with the Key-Value (KV) cache playing a vital role in enhancing their performance. However, the growth of the KV cache in response to increasing input length poses challenges to memory and time efficiency. To address this problem, this paper introduces SnapKV, an innovative and fine-tuning-free approach that efficiently minimizes KV cache size while still delivering comparable performance in real-world applications. We discover that each attention head in the model consistently focuses on specific prompt attention features during generation. Meanwhile, this robust pattern can be obtained from an `observation' window located at the end of the prompts. Drawing on this insight, SnapKV automatically compresses KV caches by selecting clustered important KV positions for each attention head. Our approach significantly reduces the growing computational overhead and memory footprint when processing long input sequences. Specifically, SnapKV achieves a consistent decoding speed with a 3.6x increase in generation speed and an 8.2x enhancement in memory efficiency compared to baseline when processing inputs of 16K tokens. At the same time, it maintains comparable performance to baseline models across 16 long sequence datasets. Moreover, SnapKV can process up to 380K context tokens on a single A100-80GB GPU using HuggingFace implementation with minor changes, exhibiting only a negligible accuracy drop in the Needle-in-a-Haystack test. Further comprehensive studies suggest SnapKV's potential for practical applications.
Subgraph Extraction-based Feedback-guided Iterative Scheduling for HLS
Jan 22, 2024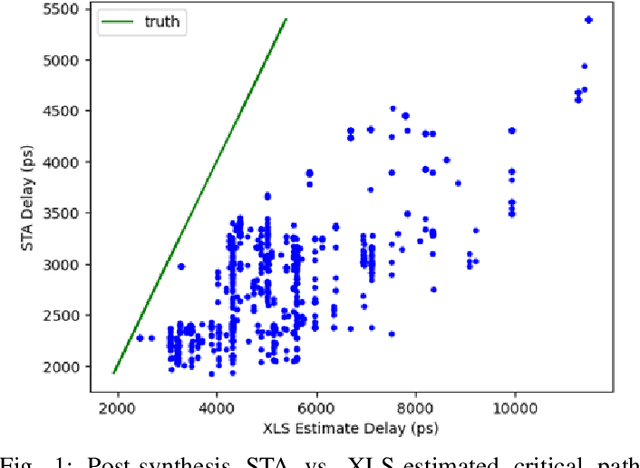
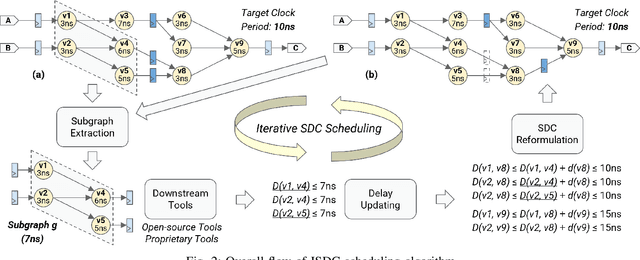
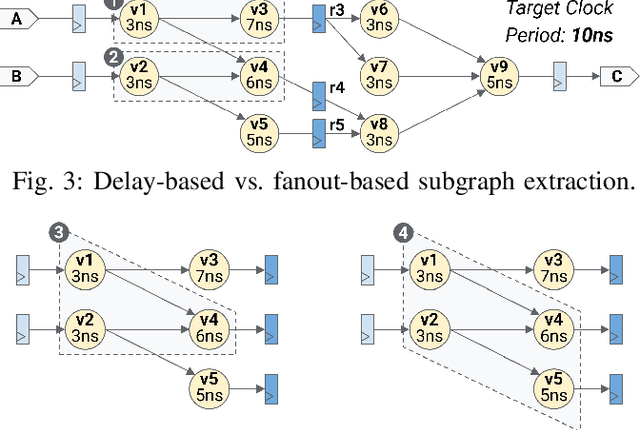

This paper proposes ISDC, a novel feedback-guided iterative system of difference constraints (SDC) scheduling algorithm for high-level synthesis (HLS). ISDC leverages subgraph extraction-based low-level feedback from downstream tools like logic synthesizers to iteratively refine HLS scheduling. Technical innovations include: (1) An enhanced SDC formulation that effectively integrates low-level feedback into the linear-programming (LP) problem; (2) A fanout and window-based subgraph extraction mechanism driving the feedback cycle; (3) A no-human-in-loop ISDC flow compatible with a wide range of downstream tools and process design kits (PDKs). Evaluation shows that ISDC reduces register usage by 28.5% against an industrial-strength open-source HLS tool.
HybridDNN: A Framework for High-Performance Hybrid DNN Accelerator Design and Implementation
Apr 08, 2020

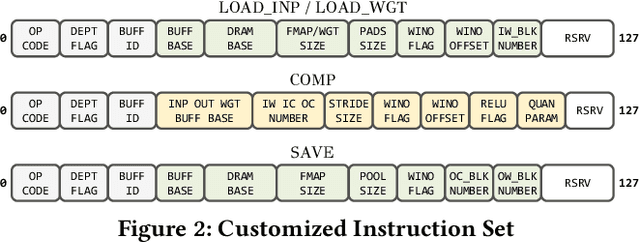
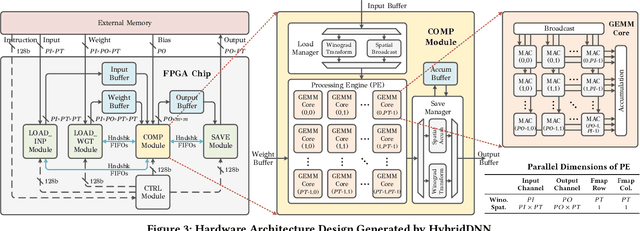
To speedup Deep Neural Networks (DNN) accelerator design and enable effective implementation, we propose HybridDNN, a framework for building high-performance hybrid DNN accelerators and delivering FPGA-based hardware implementations. Novel techniques include a highly flexible and scalable architecture with a hybrid Spatial/Winograd convolution (CONV) Processing Engine (PE), a comprehensive design space exploration tool, and a complete design flow to fully support accelerator design and implementation. Experimental results show that the accelerators generated by HybridDNN can deliver 3375.7 and 83.3 GOPS on a high-end FPGA (VU9P) and an embedded FPGA (PYNQ-Z1), respectively, which achieve a 1.8x higher performance improvement compared to the state-of-art accelerator designs. This demonstrates that HybridDNN is flexible and scalable and can target both cloud and embedded hardware platforms with vastly different resource constraints.