 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHybridDNN: A Framework for High-Performance Hybrid DNN Accelerator Design and Implementation
Apr 08, 2020

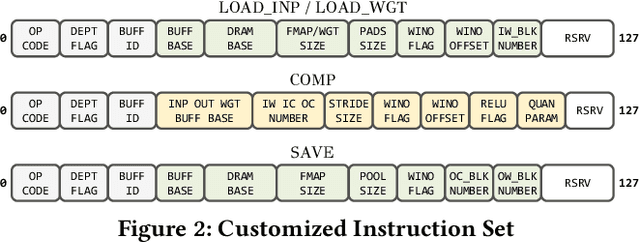
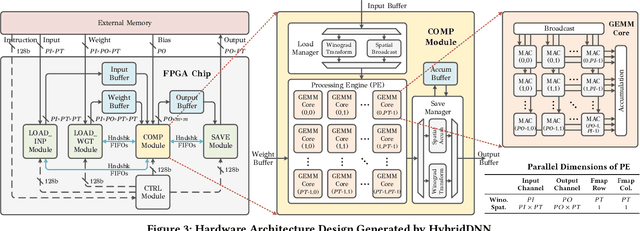
To speedup Deep Neural Networks (DNN) accelerator design and enable effective implementation, we propose HybridDNN, a framework for building high-performance hybrid DNN accelerators and delivering FPGA-based hardware implementations. Novel techniques include a highly flexible and scalable architecture with a hybrid Spatial/Winograd convolution (CONV) Processing Engine (PE), a comprehensive design space exploration tool, and a complete design flow to fully support accelerator design and implementation. Experimental results show that the accelerators generated by HybridDNN can deliver 3375.7 and 83.3 GOPS on a high-end FPGA (VU9P) and an embedded FPGA (PYNQ-Z1), respectively, which achieve a 1.8x higher performance improvement compared to the state-of-art accelerator designs. This demonstrates that HybridDNN is flexible and scalable and can target both cloud and embedded hardware platforms with vastly different resource constraints.