 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNüwa: Mending the Spatial Integrity Torn by VLM Token Pruning
Feb 03, 2026Vision token pruning has proven to be an effective acceleration technique for the efficient Vision Language Model (VLM). However, existing pruning methods demonstrate excellent performance preservation in visual question answering (VQA) and suffer substantial degradation on visual grounding (VG) tasks. Our analysis of the VLM's processing pipeline reveals that strategies utilizing global semantic similarity and attention scores lose the global spatial reference frame, which is derived from the interactions of tokens' positional information. Motivated by these findings, we propose $\text{Nüwa}$, a two-stage token pruning framework that enables efficient feature aggregation while maintaining spatial integrity. In the first stage, after the vision encoder, we apply three operations, namely separation, alignment, and aggregation, which are inspired by swarm intelligence algorithms to retain information-rich global spatial anchors. In the second stage, within the LLM, we perform text-guided pruning to retain task-relevant visual tokens. Extensive experiments demonstrate that $\text{Nüwa}$ achieves SOTA performance on multiple VQA benchmarks (from 94% to 95%) and yields substantial improvements on visual grounding tasks (from 7% to 47%).
NeuroPath: Neurobiology-Inspired Path Tracking and Reflection for Semantically Coherent Retrieval
Nov 18, 2025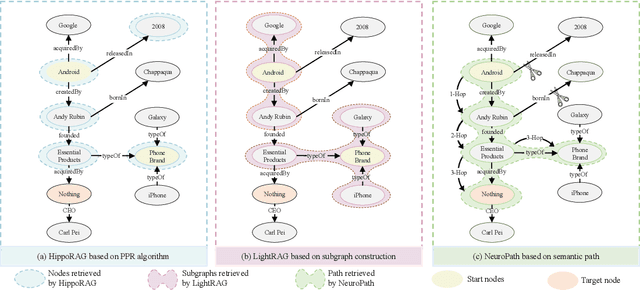
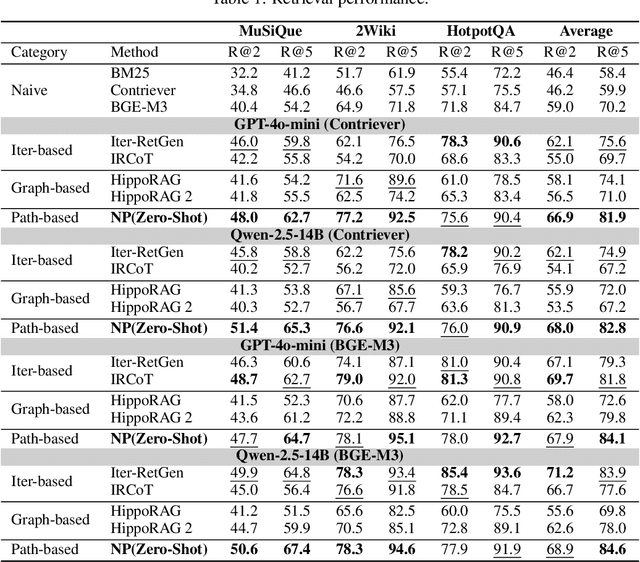
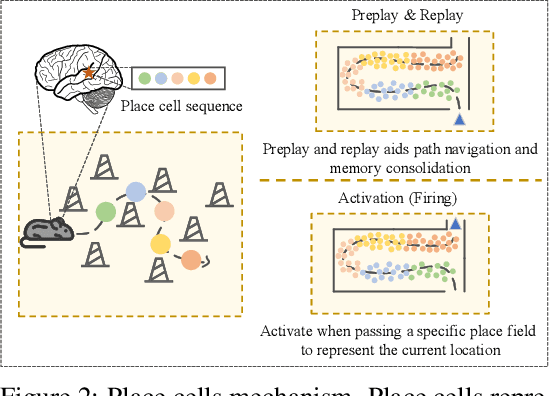
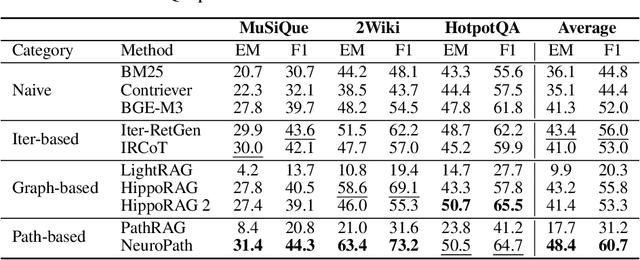
Retrieval-augmented generation (RAG) greatly enhances large language models (LLMs) performance in knowledge-intensive tasks. However, naive RAG methods struggle with multi-hop question answering due to their limited capacity to capture complex dependencies across documents. Recent studies employ graph-based RAG to capture document connections. However, these approaches often result in a loss of semantic coherence and introduce irrelevant noise during node matching and subgraph construction. To address these limitations, we propose NeuroPath, an LLM-driven semantic path tracking RAG framework inspired by the path navigational planning of place cells in neurobiology. It consists of two steps: Dynamic Path Tracking and Post-retrieval Completion. Dynamic Path Tracking performs goal-directed semantic path tracking and pruning over the constructed knowledge graph (KG), improving noise reduction and semantic coherence. Post-retrieval Completion further reinforces these benefits by conducting second-stage retrieval using intermediate reasoning and the original query to refine the query goal and complete missing information in the reasoning path. NeuroPath surpasses current state-of-the-art baselines on three multi-hop QA datasets, achieving average improvements of 16.3% on recall@2 and 13.5% on recall@5 over advanced graph-based RAG methods. Moreover, compared to existing iter-based RAG methods, NeuroPath achieves higher accuracy and reduces token consumption by 22.8%. Finally, we demonstrate the robustness of NeuroPath across four smaller LLMs (Llama3.1, GLM4, Mistral0.3, and Gemma3), and further validate its scalability across tasks of varying complexity. Code is available at https://github.com/KennyCaty/NeuroPath.
GraphCogent: Overcoming LLMs' Working Memory Constraints via Multi-Agent Collaboration in Complex Graph Understanding
Aug 17, 2025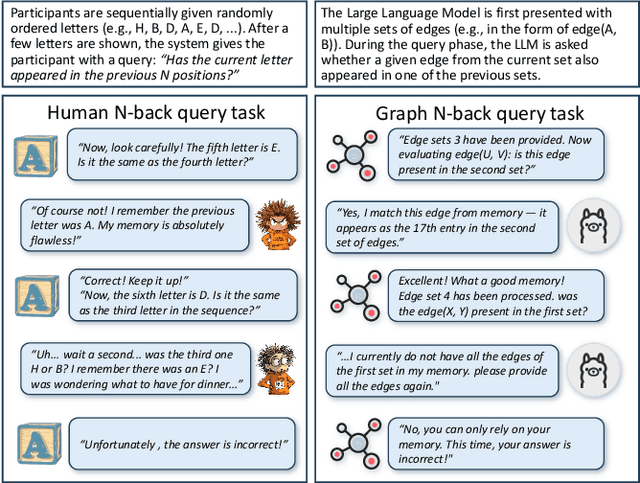
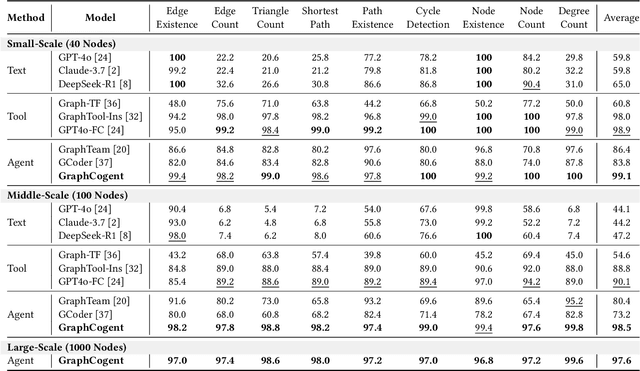
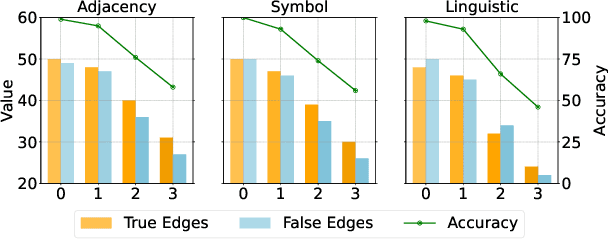

Large language models (LLMs) show promising performance on small-scale graph reasoning tasks but fail when handling real-world graphs with complex queries. This phenomenon stems from LLMs' inability to effectively process complex graph topology and perform multi-step reasoning simultaneously. To address these limitations, we propose GraphCogent, a collaborative agent framework inspired by human Working Memory Model that decomposes graph reasoning into specialized cognitive processes: sense, buffer, and execute. The framework consists of three modules: Sensory Module standardizes diverse graph text representations via subgraph sampling, Buffer Module integrates and indexes graph data across multiple formats, and Execution Module combines tool calling and model generation for efficient reasoning. We also introduce Graph4real, a comprehensive benchmark contains with four domains of real-world graphs (Web, Social, Transportation, and Citation) to evaluate LLMs' graph reasoning capabilities. Our Graph4real covers 21 different graph reasoning tasks, categorized into three types (Structural Querying, Algorithmic Reasoning, and Predictive Modeling tasks), with graph scales that are 10 times larger than existing benchmarks. Experiments show that Llama3.1-8B based GraphCogent achieves a 50% improvement over massive-scale LLMs like DeepSeek-R1 (671B). Compared to state-of-the-art agent-based baseline, our framework outperforms by 20% in accuracy while reducing token usage by 80% for in-toolset tasks and 30% for out-toolset tasks. Code will be available after review.
DimGrow: Memory-Efficient Field-level Embedding Dimension Search
May 19, 2025Key feature fields need bigger embedding dimensionality, others need smaller. This demands automated dimension allocation. Existing approaches, such as pruning or Neural Architecture Search (NAS), require training a memory-intensive SuperNet that enumerates all possible dimension combinations, which is infeasible for large feature spaces. We propose DimGrow, a lightweight approach that eliminates the SuperNet requirement. Starting training model from one dimension per feature field, DimGrow can progressively expand/shrink dimensions via importance scoring. Dimensions grow only when their importance consistently exceed a threshold, ensuring memory efficiency. Experiments on three recommendation datasets verify the effectiveness of DimGrow while it reduces training memory compared to SuperNet-based methods.
ShuffleGate: An Efficient and Self-Polarizing Feature Selection Method for Large-Scale Deep Models in Industry
Mar 12, 2025

Deep models in industrial applications rely on thousands of features for accurate predictions, such as deep recommendation systems. While new features are introduced to capture evolving user behavior, outdated or redundant features often remain, significantly increasing storage and computational costs. To address this issue, feature selection methods are widely adopted to identify and remove less important features. However, existing approaches face two major challenges: (1) they often require complex Hyperparameter (Hp) tuning, making them difficult to employ in practice, and (2) they fail to produce well-separated feature importance scores, which complicates straightforward feature removal. Moreover, the impact of removing unimportant features can only be evaluated through retraining the model, a time-consuming and resource-intensive process that severely hinders efficient feature selection. To solve these challenges, we propose a novel feature selection approach, Shuffle-Gate. In particular, it shuffles all feature values across instances simultaneously and uses a gating mechanism that allows the model to dynamically learn the weights for combining the original and shuffled inputs. Notably, it can generate well-separated feature importance scores and estimate the performance without retraining the model, while introducing only a single Hp. Experiments on four public datasets show that our approach outperforms state-of-the-art methods in selecting the top half of the feature set for model retraining. Moreover, it has been successfully integrated into the daily iteration of Bilibili's search models across various scenarios, where it significantly reduces feature set size and computational resource usage, while maintaining comparable performance.
GradStop: Exploring Training Dynamics in Unsupervised Outlier Detection through Gradient Cohesion
Dec 11, 2024



Unsupervised Outlier Detection (UOD) is a critical task in data mining and machine learning, aiming to identify instances that significantly deviate from the majority. Without any label, deep UOD methods struggle with the misalignment between the model's direct optimization goal and the final performance goal of Outlier Detection (OD) task. Through the perspective of training dynamics, this paper proposes an early stopping algorithm to optimize the training of deep UOD models, ensuring they perform optimally in OD rather than overfitting the entire contaminated dataset. Inspired by UOD mechanism and inlier priority phenomenon, where intuitively models fit inliers more quickly than outliers, we propose GradStop, a sampling-based label-free algorithm to estimate model's real-time performance during training. First, a sampling method generates two sets: one likely containing more outliers and the other more inliers, then a metric based on gradient cohesion is applied to probe into current training dynamics, which reflects model's performance on OD task. Experimental results on 4 deep UOD algorithms and 47 real-world datasets and theoretical proofs demonstrate the effectiveness of our proposed early stopping algorithm in enhancing the performance of deep UOD models. Auto Encoder (AE) enhanced by GradStop achieves better performance than itself, other SOTA UOD methods, and even ensemble AEs. Our method provides a robust and effective solution to the problem of performance degradation during training, enabling deep UOD models to achieve better potential in anomaly detection tasks.
EntropyStop: Unsupervised Deep Outlier Detection with Loss Entropy
May 21, 2024



Unsupervised Outlier Detection (UOD) is an important data mining task. With the advance of deep learning, deep Outlier Detection (OD) has received broad interest. Most deep UOD models are trained exclusively on clean datasets to learn the distribution of the normal data, which requires huge manual efforts to clean the real-world data if possible. Instead of relying on clean datasets, some approaches directly train and detect on unlabeled contaminated datasets, leading to the need for methods that are robust to such conditions. Ensemble methods emerged as a superior solution to enhance model robustness against contaminated training sets. However, the training time is greatly increased by the ensemble. In this study, we investigate the impact of outliers on the training phase, aiming to halt training on unlabeled contaminated datasets before performance degradation. Initially, we noted that blending normal and anomalous data causes AUC fluctuations, a label-dependent measure of detection accuracy. To circumvent the need for labels, we propose a zero-label entropy metric named Loss Entropy for loss distribution, enabling us to infer optimal stopping points for training without labels. Meanwhile, we theoretically demonstrate negative correlation between entropy metric and the label-based AUC. Based on this, we develop an automated early-stopping algorithm, EntropyStop, which halts training when loss entropy suggests the maximum model detection capability. We conduct extensive experiments on ADBench (including 47 real datasets), and the overall results indicate that AutoEncoder (AE) enhanced by our approach not only achieves better performance than ensemble AEs but also requires under 1\% of training time. Lastly, our proposed metric and early-stopping approach are evaluated on other deep OD models, exhibiting their broad potential applicability.
Unleashing the Potential of Unsupervised Deep Outlier Detection through Automated Training Stopping
May 26, 2023Outlier detection (OD) has received continuous research interests due to its wide applications. With the development of deep learning, increasingly deep OD algorithms are proposed. Despite the availability of numerous deep OD models, existing research has reported that the performance of deep models is extremely sensitive to the configuration of hyperparameters (HPs). However, the selection of HPs for deep OD models remains a notoriously difficult task due to the lack of any labels and long list of HPs. In our study. we shed light on an essential factor, training time, that can introduce significant variation in the performance of deep model. Even the performance is stable across other HPs, training time itself can cause a serious HP sensitivity issue. Motivated by this finding, we are dedicated to formulating a strategy to terminate model training at the optimal iteration. Specifically, we propose a novel metric called loss entropy to internally evaluate the model performance during training while an automated training stopping algorithm is devised. To our knowledge, our approach is the first to enable reliable identification of the optimal training iteration during training without requiring any labels. Our experiments on tabular, image datasets show that our approach can be applied to diverse deep models and datasets. It not only enhances the robustness of deep models to their HPs, but also improves the performance and reduces plenty of training time compared to naive training.
Are we really making much progress in unsupervised graph outlier detection? Revisiting the problem with new insight and superior method
Oct 24, 2022A large number of studies on Graph Outlier Detection (GOD) have emerged in recent years due to its wide applications, in which Unsupervised Node Outlier Detection (UNOD) on attributed networks is an important area. UNOD focuses on detecting two kinds of typical outliers in graphs: the structural outlier and the contextual outlier. Most existing works conduct the experiments based on the datasets with injected outliers. However, we find that the most widely-used outlier injection approach has a serious data leakage issue. By only utilizing such data leakage, a simple approach can achieve the state-of-the-art performance in detecting outliers. In addition, we observe that most existing algorithms have performance drops with varied injection settings. The other major issue is on balanced detection performance between the two types of outliers, which has not been considered by existing studies. In this paper, we analyze the cause of the data leakage issue in depth since the injection approach is a building block to advance UNOD. Moreover, we devise a novel variance-based model to detect structural outliers, which is more robust to different injection settings. On top of this, we propose a new framework, Variance-based Graph Outlier Detection (VGOD), which combines our variance-based model and attribute reconstruction model to detect outliers in a balanced way. Finally, we conduct extensive experiments to demonstrate the effectiveness and the efficiency of VGOD. The results on 5 real-world datasets validate that VGOD achieves not only the best performance in detecting outliers but also a balanced detection performance between structural and contextual outliers.