 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLeveraging Reinforcement Learning, Genetic Algorithms and Transformers for background determination in particle physics
Sep 18, 2025



Experimental studies of beauty hadron decays face significant challenges due to a wide range of backgrounds arising from the numerous possible decay channels with similar final states. For a particular signal decay, the process for ascertaining the most relevant background processes necessitates a detailed analysis of final state particles, potential misidentifications, and kinematic overlaps, which, due to computational limitations, is restricted to the simulation of only the most relevant backgrounds. Moreover, this process typically relies on the physicist's intuition and expertise, as no systematic method exists. This paper has two primary goals. First, from a particle physics perspective, we present a novel approach that utilises Reinforcement Learning (RL) to overcome the aforementioned challenges by systematically determining the critical backgrounds affecting beauty hadron decay measurements. While beauty hadron physics serves as the case study in this work, the proposed strategy is broadly adaptable to other types of particle physics measurements. Second, from a Machine Learning perspective, we introduce a novel algorithm which exploits the synergy between RL and Genetic Algorithms (GAs) for environments with highly sparse rewards and a large trajectory space. This strategy leverages GAs to efficiently explore the trajectory space and identify successful trajectories, which are used to guide the RL agent's training. Our method also incorporates a transformer architecture for the RL agent to handle token sequences representing decays.
Fusing Convolutional Neural Network and Geometric Constraint for Image-based Indoor Localization
Jan 05, 2022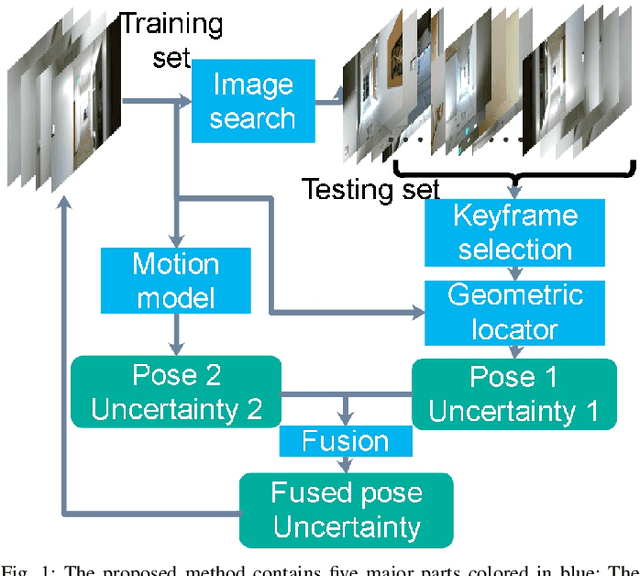
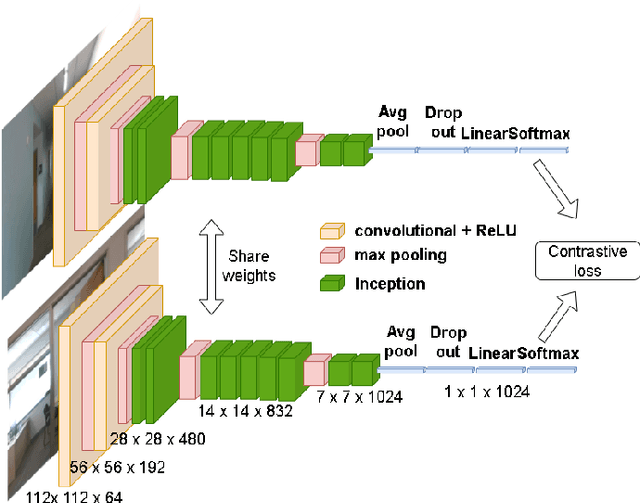
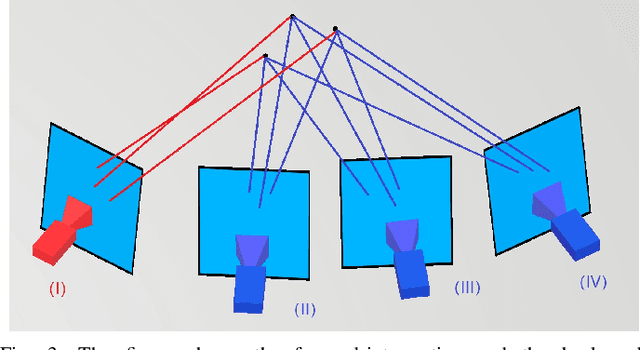

This paper proposes a new image-based localization framework that explicitly localizes the camera/robot by fusing Convolutional Neural Network (CNN) and sequential images' geometric constraints. The camera is localized using a single or few observed images and training images with 6-degree-of-freedom pose labels. A Siamese network structure is adopted to train an image descriptor network, and the visually similar candidate image in the training set is retrieved to localize the testing image geometrically. Meanwhile, a probabilistic motion model predicts the pose based on a constant velocity assumption. The two estimated poses are finally fused using their uncertainties to yield an accurate pose prediction. This method leverages the geometric uncertainty and is applicable in indoor scenarios predominated by diffuse illumination. Experiments on simulation and real data sets demonstrate the efficiency of our proposed method. The results further show that combining the CNN-based framework with geometric constraint achieves better accuracy when compared with CNN-only methods, especially when the training data size is small.
Face-to-Music Translation Using a Distance-Preserving Generative Adversarial Network with an Auxiliary Discriminator
Jun 24, 2020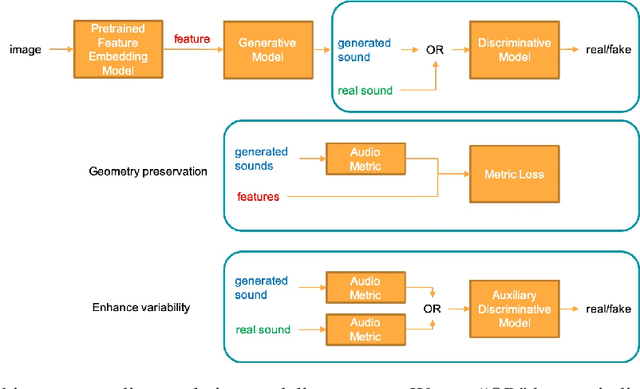



Learning a mapping between two unrelated domains-such as image and audio, without any supervision is a challenging task. In this work, we propose a distance-preserving generative adversarial model to translate images of human faces into an audio domain. The audio domain is defined by a collection of musical note sounds recorded by 10 different instrument families (NSynth \cite{nsynth2017}) and a distance metric where the instrument family class information is incorporated together with a mel-frequency cepstral coefficients (MFCCs) feature. To enforce distance-preservation, a loss term that penalizes difference between pairwise distances of the faces and the translated audio samples is used. Further, we discover that the distance preservation constraint in the generative adversarial model leads to reduced diversity in the translated audio samples, and propose the use of an auxiliary discriminator to enhance the diversity of the translations while using the distance preservation constraint. We also provide a visual demonstration of the results and numerical analysis of the fidelity of the translations. A video demo of our proposed model's learned translation is available in https://www.dropbox.com/s/the176w9obq8465/face_to_musical_note.mov?dl=0.
A closed-form solution to estimate uncertainty in non-rigid structure from motion
Jun 12, 2020
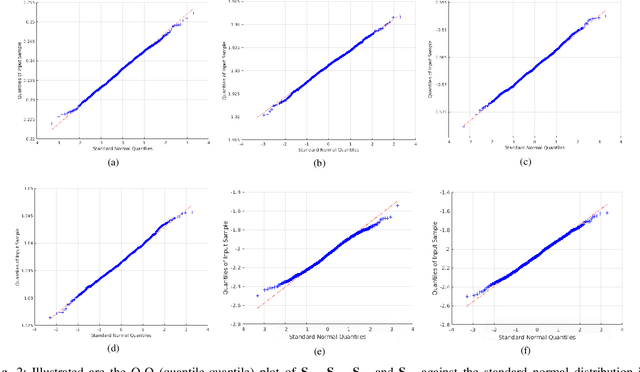

Semi-Definite Programming (SDP) with low-rank prior has been widely applied in Non-Rigid Structure from Motion (NRSfM). Based on a low-rank constraint, it avoids the inherent ambiguity of basis number selection in conventional base-shape or base-trajectory methods. Despite the efficiency in deformable shape reconstruction, it remains unclear how to assess the uncertainty of the recovered shape from the SDP process. In this paper, we present a statistical inference on the element-wise uncertainty quantification of the estimated deforming 3D shape points in the case of the exact low-rank SDP problem. A closed-form uncertainty quantification method is proposed and tested. Moreover, we extend the exact low-rank uncertainty quantification to the approximate low-rank scenario with a numerical optimal rank selection method, which enables solving practical application in SDP based NRSfM scenario. The proposed method provides an independent module to the SDP method and only requires the statistic information of the input 2D tracked points. Extensive experiments prove that the output 3D points have identical normal distribution to the 2D trackings, the proposed method and quantify the uncertainty accurately, and supports that it has desirable effects on routinely SDP low-rank based NRSfM solver.
Earballs: Neural Transmodal Translation
Jun 05, 2020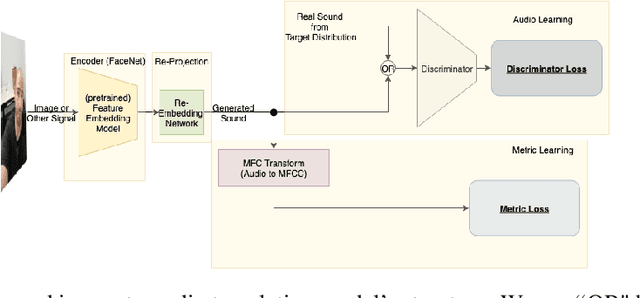
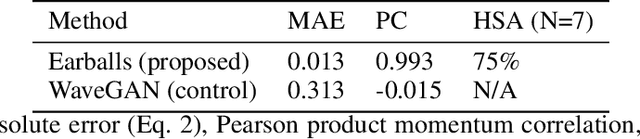


As is expressed in the adage "a picture is worth a thousand words", when using spoken language to communicate visual information, brevity can be a challenge. This work describes a novel technique for leveraging machine learned feature embeddings to translate visual (and other types of) information into a perceptual audio domain, allowing users to perceive this information using only their aural faculty. The system uses a pretrained image embedding network to extract visual features and embed them in a compact subset of Euclidean space -- this converts the images into feature vectors whose $L^2$ distances can be used as a meaningful measure of similarity. A generative adversarial network (GAN) is then used to find a distance preserving map from this metric space of feature vectors into the metric space defined by a target audio dataset equipped with either the Euclidean metric or a mel-frequency cepstrum-based psychoacoustic distance metric. We demonstrate this technique by translating images of faces into human speech-like audio. For both target audio metrics, the GAN successfully found a metric preserving mapping, and in human subject tests, users were able to accurately classify audio translations of faces.
Combining Deep Learning with Geometric Features for Image based Localization in the Gastrointestinal Tract
May 13, 2020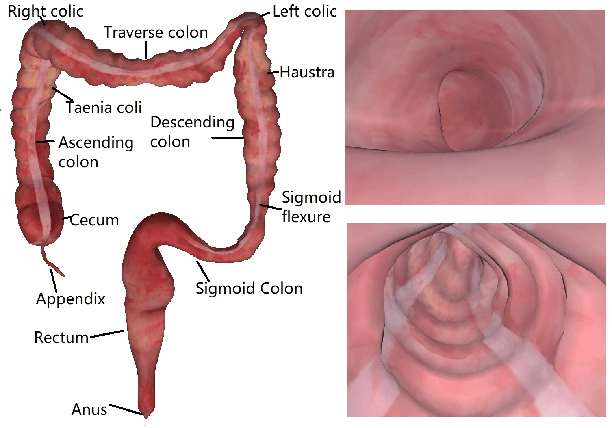

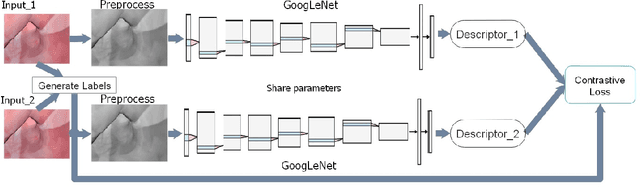
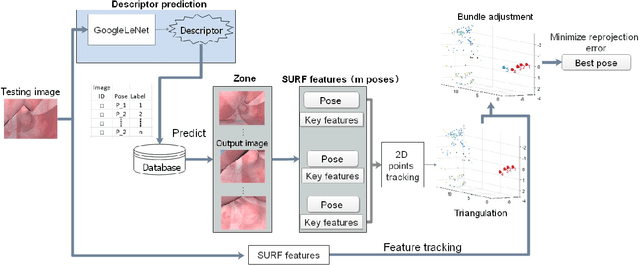
Tracking monocular colonoscope in the Gastrointestinal tract (GI) is a challenging problem as the images suffer from deformation, blurred textures, significant changes in appearance. They greatly restrict the tracking ability of conventional geometry based methods. Even though Deep Learning (DL) can overcome these issues, limited labeling data is a roadblock to state-of-art DL method. Considering these, we propose a novel approach to combine DL method with traditional feature based approach to achieve better localization with small training data. Our method fully exploits the best of both worlds by introducing a Siamese network structure to perform few-shot classification to the closest zone in the segmented training image set. The classified label is further adopted to initialize the pose of scope. To fully use the training dataset, a pre-generated triangulated map points within the zone in the training set are registered with observation and contribute to estimating the optimal pose of the test image. The proposed hybrid method is extensively tested and compared with existing methods, and the result shows significant improvement over traditional geometric based or DL based localization. The accuracy is improved by 28.94% (Position) and 10.97% (Orientation) with respect to state-of-art method.
QoS and Jamming-Aware Wireless Networking Using Deep Reinforcement Learning
Oct 13, 2019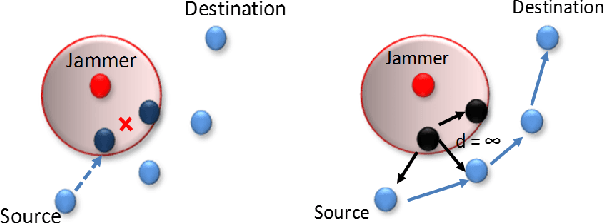
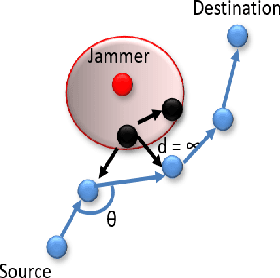
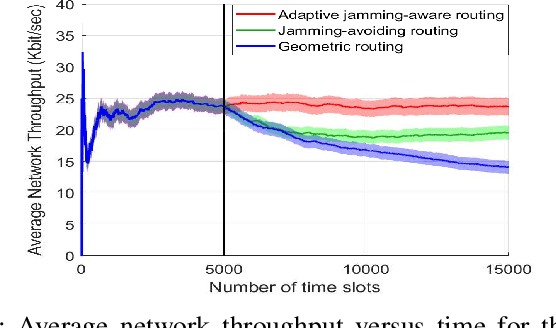
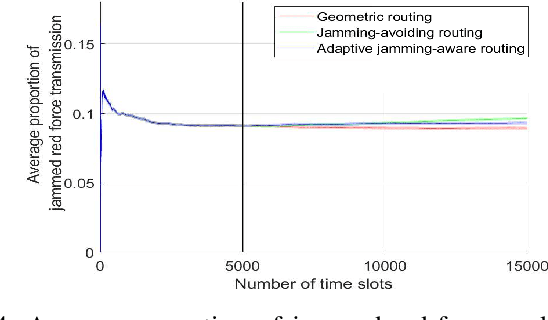
The problem of quality of service (QoS) and jamming-aware communications is considered in an adversarial wireless network subject to external eavesdropping and jamming attacks. To ensure robust communication against jamming, an interference-aware routing protocol is developed that allows nodes to avoid communication holes created by jamming attacks. Then, a distributed cooperation framework, based on deep reinforcement learning, is proposed that allows nodes to assess network conditions and make deep learning-driven, distributed, and real-time decisions on whether to participate in data communications, defend the network against jamming and eavesdropping attacks, or jam other transmissions. The objective is to maximize the network performance that incorporates throughput, energy efficiency, delay, and security metrics. Simulation results show that the proposed jamming-aware routing approach is robust against jamming and when throughput is prioritized, the proposed deep reinforcement learning approach can achieve significant (measured as three-fold) increase in throughput, compared to a benchmark policy with fixed roles assigned to nodes.
A Radio-Inertial Localization and Tracking System with BLE Beacons Prior Maps
Jul 26, 2018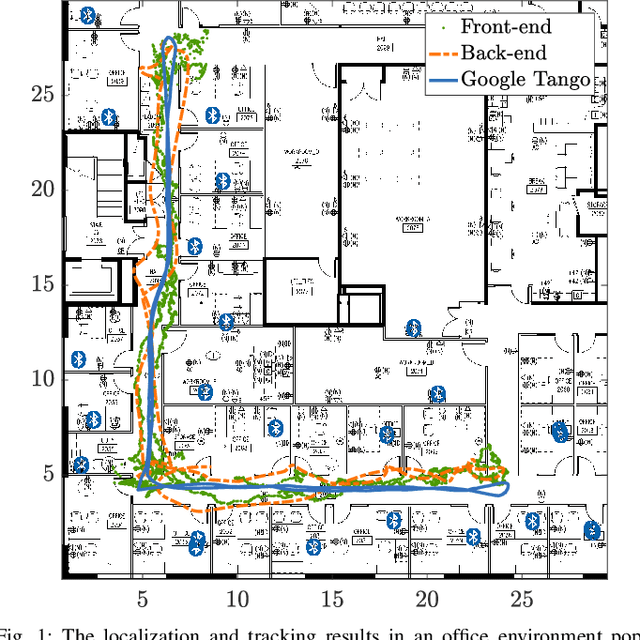
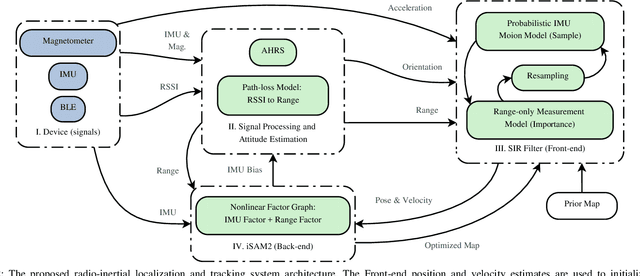
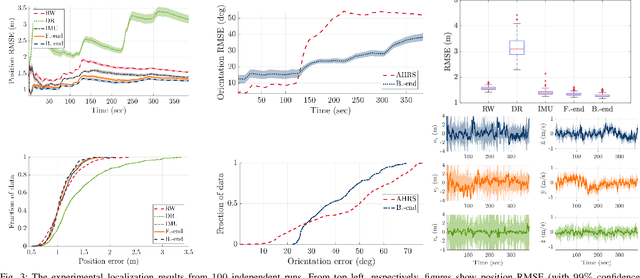

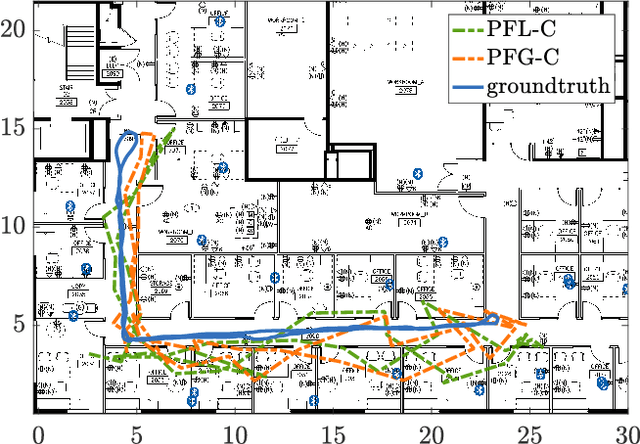
In this paper, we develop a system for the low-cost indoor localization and tracking problem using radio signal strength indicator, Inertial Measurement Unit (IMU), and magnetometer sensors. We develop a novel and simplified probabilistic IMU motion model as the proposal distribution of the sequential Monte-Carlo technique to track the robot trajectory. Our algorithm can globally localize and track a robot with a priori unknown location, given an informative prior map of the Bluetooth Low Energy (BLE) beacons. Also, we formulate the problem as an optimization problem that serves as the Back-end of the algorithm mentioned above (Front-end). Thus, by simultaneously solving for the robot trajectory and the map of BLE beacons, we recover a continuous and smooth trajectory of the robot, corrected locations of the BLE beacons, and the time-varying IMU bias. The evaluations achieved using hardware show that through the proposed closed-loop system the localization performance can be improved; furthermore, the system becomes robust to the error in the map of beacons by feeding back the optimized map to the Front-end.
Gaussian Processes Online Observation Classification for RSSI-based Low-cost Indoor Positioning Systems
Feb 20, 2017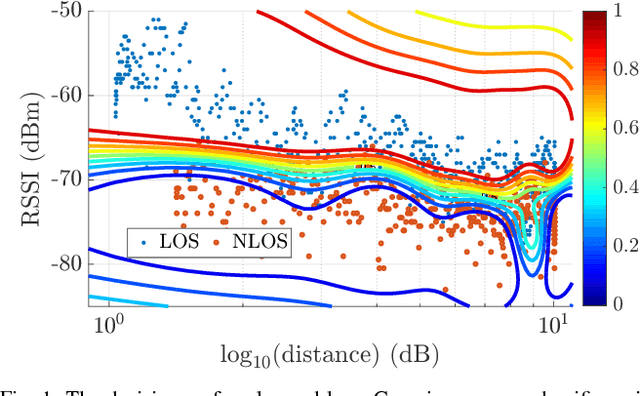
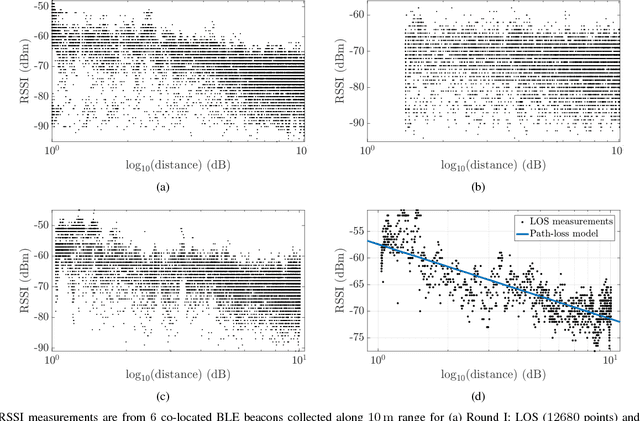
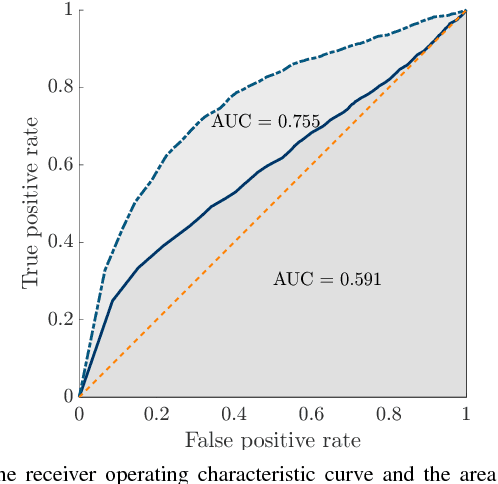
In this paper, we propose a real-time classification scheme to cope with noisy Radio Signal Strength Indicator (RSSI) measurements utilized in indoor positioning systems. RSSI values are often converted to distances for position estimation. However due to multipathing and shadowing effects, finding a unique sensor model using both parametric and non-parametric methods is highly challenging. We learn decision regions using the Gaussian Processes classification to accept measurements that are consistent with the operating sensor model. The proposed approach can perform online, does not rely on a particular sensor model or parameters, and is robust to sensor failures. The experimental results achieved using hardware show that available positioning algorithms can benefit from incorporating the classifier into their measurement model as a meta-sensor modeling technique.