 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFace-to-Music Translation Using a Distance-Preserving Generative Adversarial Network with an Auxiliary Discriminator
Paper and Code
Jun 24, 2020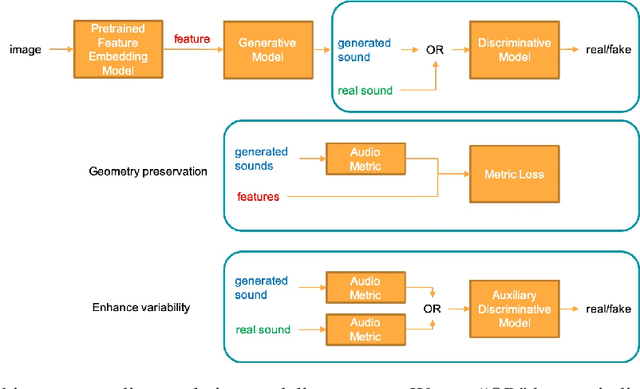



Learning a mapping between two unrelated domains-such as image and audio, without any supervision is a challenging task. In this work, we propose a distance-preserving generative adversarial model to translate images of human faces into an audio domain. The audio domain is defined by a collection of musical note sounds recorded by 10 different instrument families (NSynth \cite{nsynth2017}) and a distance metric where the instrument family class information is incorporated together with a mel-frequency cepstral coefficients (MFCCs) feature. To enforce distance-preservation, a loss term that penalizes difference between pairwise distances of the faces and the translated audio samples is used. Further, we discover that the distance preservation constraint in the generative adversarial model leads to reduced diversity in the translated audio samples, and propose the use of an auxiliary discriminator to enhance the diversity of the translations while using the distance preservation constraint. We also provide a visual demonstration of the results and numerical analysis of the fidelity of the translations. A video demo of our proposed model's learned translation is available in https://www.dropbox.com/s/the176w9obq8465/face_to_musical_note.mov?dl=0.