 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFace-to-Music Translation Using a Distance-Preserving Generative Adversarial Network with an Auxiliary Discriminator
Jun 24, 2020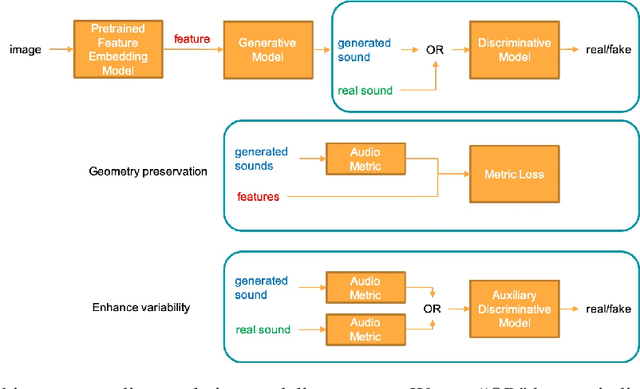



Learning a mapping between two unrelated domains-such as image and audio, without any supervision is a challenging task. In this work, we propose a distance-preserving generative adversarial model to translate images of human faces into an audio domain. The audio domain is defined by a collection of musical note sounds recorded by 10 different instrument families (NSynth \cite{nsynth2017}) and a distance metric where the instrument family class information is incorporated together with a mel-frequency cepstral coefficients (MFCCs) feature. To enforce distance-preservation, a loss term that penalizes difference between pairwise distances of the faces and the translated audio samples is used. Further, we discover that the distance preservation constraint in the generative adversarial model leads to reduced diversity in the translated audio samples, and propose the use of an auxiliary discriminator to enhance the diversity of the translations while using the distance preservation constraint. We also provide a visual demonstration of the results and numerical analysis of the fidelity of the translations. A video demo of our proposed model's learned translation is available in https://www.dropbox.com/s/the176w9obq8465/face_to_musical_note.mov?dl=0.
Earballs: Neural Transmodal Translation
Jun 05, 2020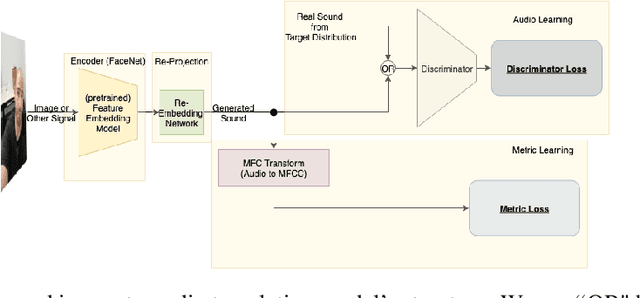
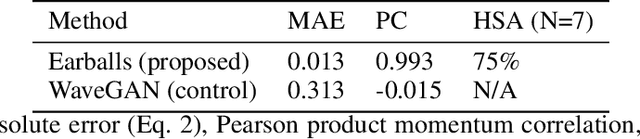


As is expressed in the adage "a picture is worth a thousand words", when using spoken language to communicate visual information, brevity can be a challenge. This work describes a novel technique for leveraging machine learned feature embeddings to translate visual (and other types of) information into a perceptual audio domain, allowing users to perceive this information using only their aural faculty. The system uses a pretrained image embedding network to extract visual features and embed them in a compact subset of Euclidean space -- this converts the images into feature vectors whose $L^2$ distances can be used as a meaningful measure of similarity. A generative adversarial network (GAN) is then used to find a distance preserving map from this metric space of feature vectors into the metric space defined by a target audio dataset equipped with either the Euclidean metric or a mel-frequency cepstrum-based psychoacoustic distance metric. We demonstrate this technique by translating images of faces into human speech-like audio. For both target audio metrics, the GAN successfully found a metric preserving mapping, and in human subject tests, users were able to accurately classify audio translations of faces.
Combining Deep Learning with Geometric Features for Image based Localization in the Gastrointestinal Tract
May 13, 2020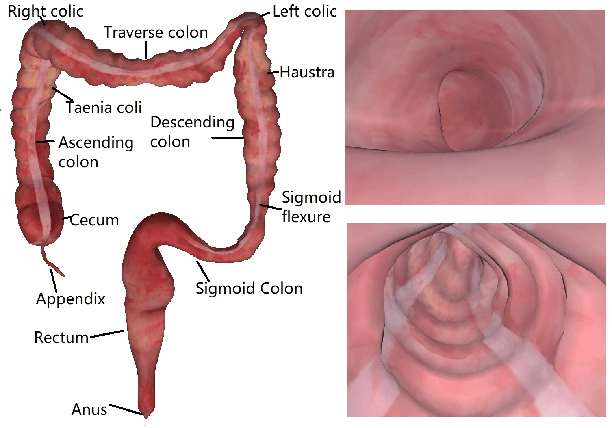

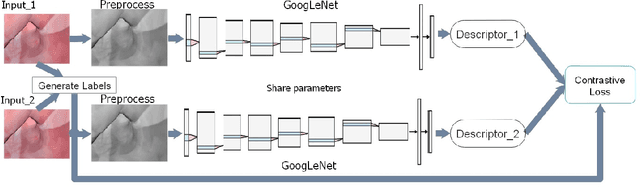
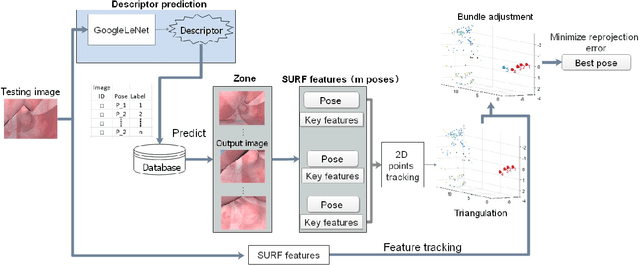
Tracking monocular colonoscope in the Gastrointestinal tract (GI) is a challenging problem as the images suffer from deformation, blurred textures, significant changes in appearance. They greatly restrict the tracking ability of conventional geometry based methods. Even though Deep Learning (DL) can overcome these issues, limited labeling data is a roadblock to state-of-art DL method. Considering these, we propose a novel approach to combine DL method with traditional feature based approach to achieve better localization with small training data. Our method fully exploits the best of both worlds by introducing a Siamese network structure to perform few-shot classification to the closest zone in the segmented training image set. The classified label is further adopted to initialize the pose of scope. To fully use the training dataset, a pre-generated triangulated map points within the zone in the training set are registered with observation and contribute to estimating the optimal pose of the test image. The proposed hybrid method is extensively tested and compared with existing methods, and the result shows significant improvement over traditional geometric based or DL based localization. The accuracy is improved by 28.94% (Position) and 10.97% (Orientation) with respect to state-of-art method.