 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEarballs: Neural Transmodal Translation
Paper and Code
Jun 05, 2020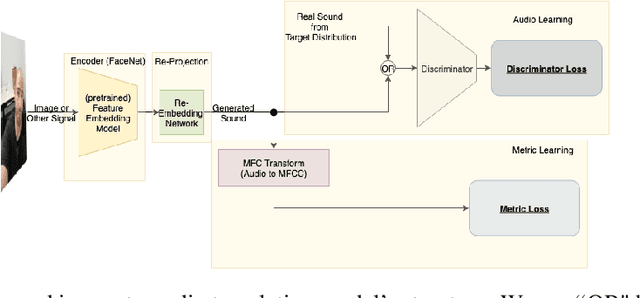
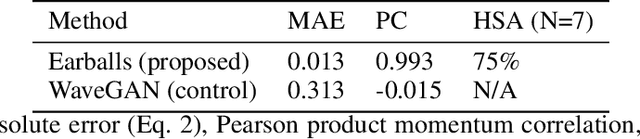


As is expressed in the adage "a picture is worth a thousand words", when using spoken language to communicate visual information, brevity can be a challenge. This work describes a novel technique for leveraging machine learned feature embeddings to translate visual (and other types of) information into a perceptual audio domain, allowing users to perceive this information using only their aural faculty. The system uses a pretrained image embedding network to extract visual features and embed them in a compact subset of Euclidean space -- this converts the images into feature vectors whose $L^2$ distances can be used as a meaningful measure of similarity. A generative adversarial network (GAN) is then used to find a distance preserving map from this metric space of feature vectors into the metric space defined by a target audio dataset equipped with either the Euclidean metric or a mel-frequency cepstrum-based psychoacoustic distance metric. We demonstrate this technique by translating images of faces into human speech-like audio. For both target audio metrics, the GAN successfully found a metric preserving mapping, and in human subject tests, users were able to accurately classify audio translations of faces.