 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Segment Attentive Embedding for Duration Robust Speaker Verification
Paper and Code
Nov 01, 2018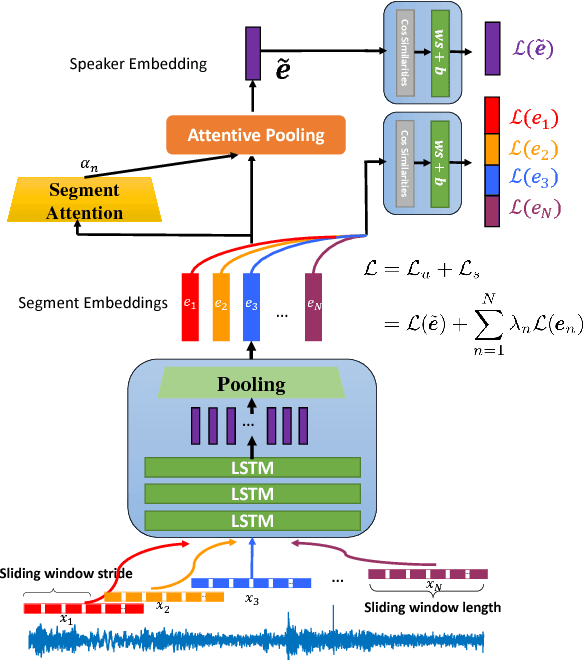

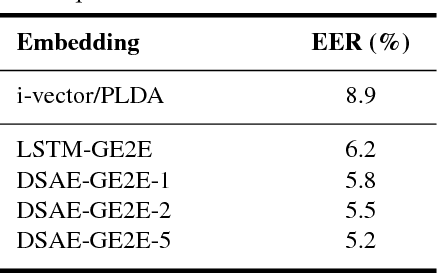
LSTM-based speaker verification usually uses a fixed-length local segment randomly truncated from an utterance to learn the utterance-level speaker embedding, while using the average embedding of all segments of a test utterance to verify the speaker, which results in a critical mismatch between testing and training. This mismatch degrades the performance of speaker verification, especially when the durations of training and testing utterances are very different. To alleviate this issue, we propose the deep segment attentive embedding method to learn the unified speaker embeddings for utterances of variable duration. Each utterance is segmented by a sliding window and LSTM is used to extract the embedding of each segment. Instead of only using one local segment, we use the whole utterance to learn the utterance-level embedding by applying an attentive pooling to the embeddings of all segments. Moreover, the similarity loss of segment-level embeddings is introduced to guide the segment attention to focus on the segments with more speaker discriminations, and jointly optimized with the similarity loss of utterance-level embeddings. Systematic experiments on Tongdun and VoxCeleb show that the proposed method significantly improves robustness of duration variant and achieves the relative Equal Error Rate reduction of 50% and 11.54% , respectively.