 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeText-Guided Coarse-to-Fine Fusion Network for Robust Remote Sensing Visual Question Answering
Nov 24, 2024
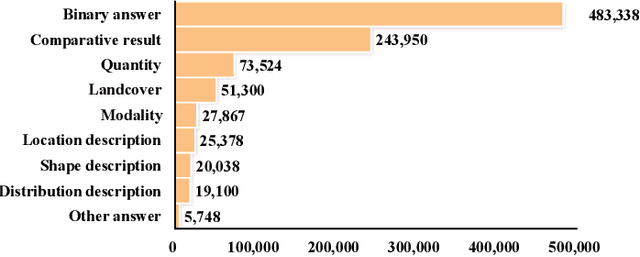

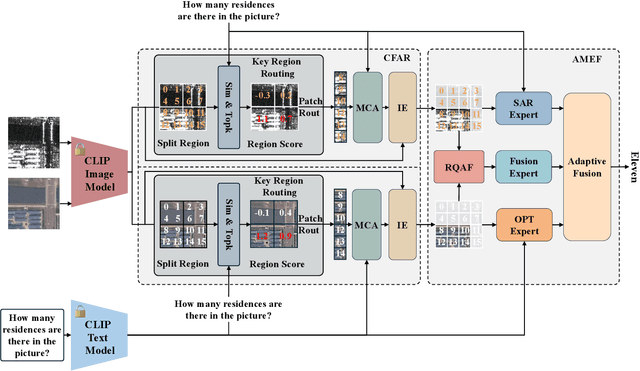
Remote Sensing Visual Question Answering (RSVQA) has gained significant research interest. However, current RSVQA methods are limited by the imaging mechanisms of optical sensors, particularly under challenging conditions such as cloud-covered and low-light scenarios. Given the all-time and all-weather imaging capabilities of Synthetic Aperture Radar (SAR), it is crucial to investigate the integration of optical-SAR images to improve RSVQA performance. In this work, we propose a Text-guided Coarse-to-Fine Fusion Network (TGFNet), which leverages the semantic relationships between question text and multi-source images to guide the network toward complementary fusion at the feature level. Specifically, we develop a Text-guided Coarse-to-Fine Attention Refinement (CFAR) module to focus on key areas related to the question in complex remote sensing images. This module progressively directs attention from broad areas to finer details through key region routing, enhancing the model's ability to focus on relevant regions. Furthermore, we propose an Adaptive Multi-Expert Fusion (AMEF) module that dynamically integrates different experts, enabling the adaptive fusion of optical and SAR features. In addition, we create the first large-scale benchmark dataset for evaluating optical-SAR RSVQA methods, comprising 6,008 well-aligned optical-SAR image pairs and 1,036,694 well-labeled question-answer pairs across 16 diverse question types, including complex relational reasoning questions. Extensive experiments on the proposed dataset demonstrate that our TGFNet effectively integrates complementary information between optical and SAR images, significantly improving the model's performance in challenging scenarios. The dataset is available at: https://github.com/mmic-lcl/. Index Terms: Remote Sensing Visual Question Answering, Multi-source Data Fusion, Multimodal, Remote Sensing, OPT-SAR.