 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMutualFormer: Multi-Modality Representation Learning via Mutual Transformer
Paper and Code
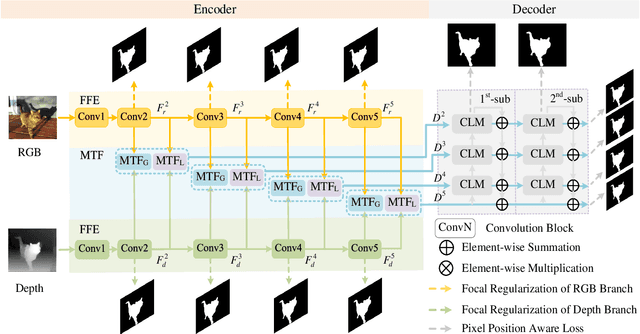
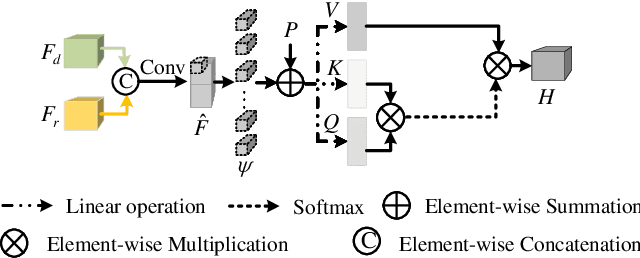
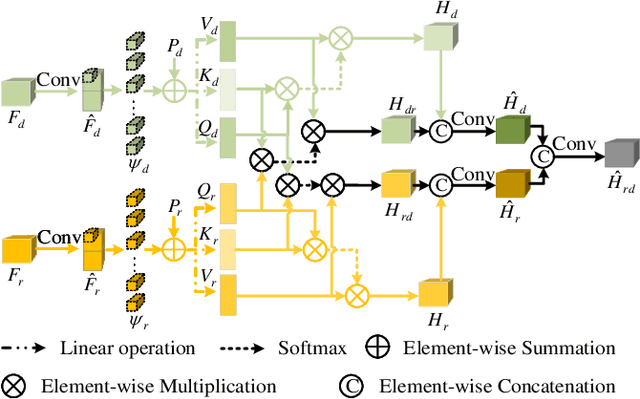
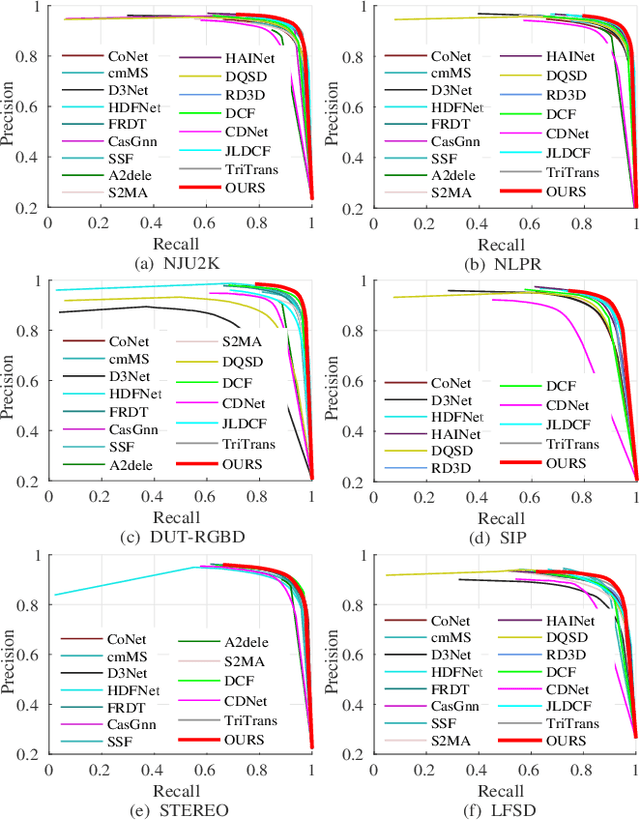
Aggregating multi-modality data to obtain accurate and reliable data representation attracts more and more attention. The pristine researchers generally adopt the CNN to extract features of independent modality and aggregate them with a fusion module. However, the overall performance is becoming saturated due to limited local convolutional features. Recent studies demonstrate that Transformer models usually work comparable or even better than CNN for multi-modality task, but they simply adopt concatenation or cross-attention for feature fusion which may just obtain sub-optimal results. In this work, we re-thinking the self-attention based Transformer and propose a novel MutualFormer for multi-modality data fusion and representation. The core of MutualFormer is the design of both token mixer and modality mixer to conduct the communication among both tokens and modalities. Specifically, it contains three main modules, i.e., i) Self-attention (SA) for intra-modality token mixer, ii) Cross-diffusion attention (CDA) for inter-modality mixer and iii) Aggregation module. The main advantage of the proposed CDA is that it is defined based on individual domain similarities in the metric space which thus can naturally avoid the issue of domain/modality gap in cross-modality similarities computation. We successfully apply the MutualFormer to the saliency detection problem and propose a novel approach to obtain the reinforced features of RGB and Depth images. Extensive experiments on six popular datasets demonstrate that our model achieves comparable results with 16 SOTA models.