 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeResponsible Multilingual Large Language Models: A Survey of Development, Applications, and Societal Impact
Paper and Code
Oct 23, 2024

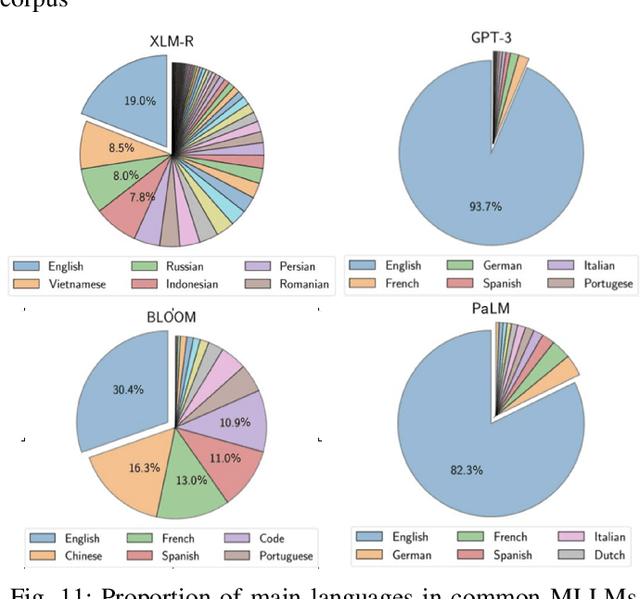

Multilingual Large Language Models (MLLMs) represent a pivotal advancement in democratizing artificial intelligence across linguistic boundaries. While theoretical foundations are well-established, practical implementation guidelines remain scattered. This work bridges this gap by providing a comprehensive end-to-end framework for developing and deploying MLLMs in production environments. We make three distinctive contributions: First, we present an actionable pipeline from data pre-processing through deployment, integrating insights from academic research and industrial applications. Second, using Llama2 as a case study, we provide detailed optimization strategies for enhancing multilingual capabilities, including curriculum learning approaches for balancing high-resource and low-resource languages, tokenization strategies, and effective sampling methods. Third, we offer an interdisciplinary analysis that considers technical, linguistic, and cultural perspectives in MLLM development. Our findings reveal critical challenges in supporting linguistic diversity, with 88.38% of world languages categorized as low-resource, affecting over a billion speakers. We examine practical solutions through real-world applications in customer service, search engines, and machine translation. By synthesizing theoretical frameworks with production-ready implementation strategies, this survey provides essential guidance for practitioners and researchers working to develop more inclusive and effective multilingual AI systems.