 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Survey of Automated Data Augmentation Algorithms for Deep Learning-based Image Classication Tasks
Paper and Code
Jun 14, 2022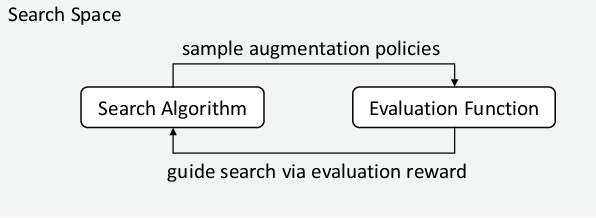
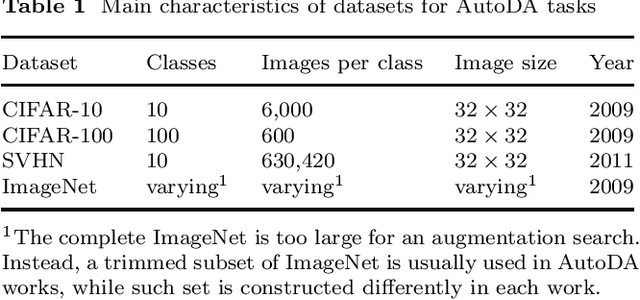
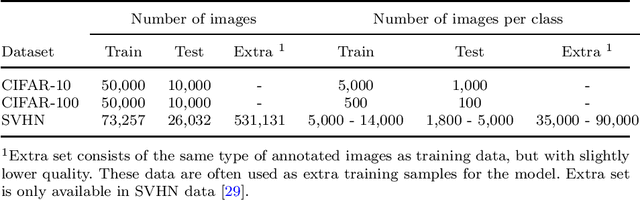
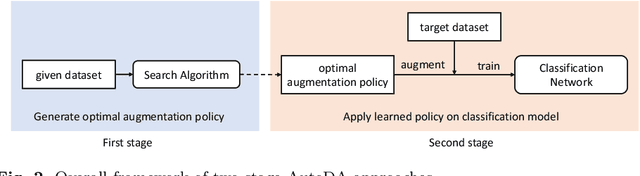
In recent years, one of the most popular techniques in the computer vision community has been the deep learning technique. As a data-driven technique, deep model requires enormous amounts of accurately labelled training data, which is often inaccessible in many real-world applications. A data-space solution is Data Augmentation (DA), that can artificially generate new images out of original samples. Image augmentation strategies can vary by dataset, as different data types might require different augmentations to facilitate model training. However, the design of DA policies has been largely decided by the human experts with domain knowledge, which is considered to be highly subjective and error-prone. To mitigate such problem, a novel direction is to automatically learn the image augmentation policies from the given dataset using Automated Data Augmentation (AutoDA) techniques. The goal of AutoDA models is to find the optimal DA policies that can maximize the model performance gains. This survey discusses the underlying reasons of the emergence of AutoDA technology from the perspective of image classification. We identify three key components of a standard AutoDA model: a search space, a search algorithm and an evaluation function. Based on their architecture, we provide a systematic taxonomy of existing image AutoDA approaches. This paper presents the major works in AutoDA field, discussing their pros and cons, and proposing several potential directions for future improvements.