 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMemory-Efficient LLM Training by Various-Grained Low-Rank Projection of Gradients
May 03, 2025Building upon the success of low-rank adapter (LoRA), low-rank gradient projection (LoRP) has emerged as a promising solution for memory-efficient fine-tuning. However, existing LoRP methods typically treat each row of the gradient matrix as the default projection unit, leaving the role of projection granularity underexplored. In this work, we propose a novel framework, VLoRP, that extends low-rank gradient projection by introducing an additional degree of freedom for controlling the trade-off between memory efficiency and performance, beyond the rank hyper-parameter. Through this framework, we systematically explore the impact of projection granularity, demonstrating that finer-grained projections lead to enhanced stability and efficiency even under a fixed memory budget. Regarding the optimization for VLoRP, we present ProjFactor, an adaptive memory-efficient optimizer, that significantly reduces memory requirement while ensuring competitive performance, even in the presence of gradient accumulation. Additionally, we provide a theoretical analysis of VLoRP, demonstrating the descent and convergence of its optimization trajectory under both SGD and ProjFactor. Extensive experiments are conducted to validate our findings, covering tasks such as commonsense reasoning, MMLU, and GSM8K.
Exact Conversion of In-Context Learning to Model Weights in Linearized-Attention Transformers
Jun 06, 2024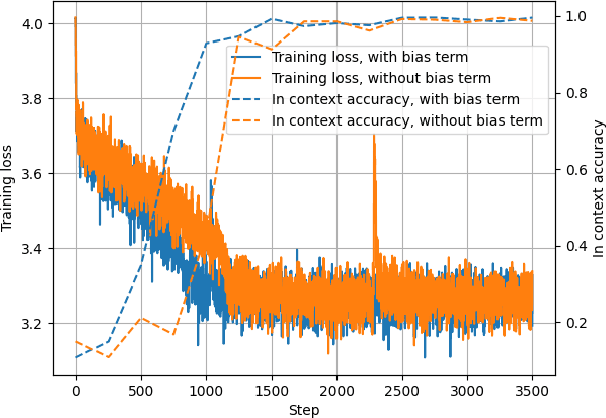
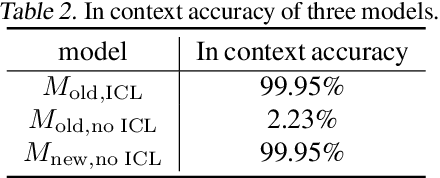

In-Context Learning (ICL) has been a powerful emergent property of large language models that has attracted increasing attention in recent years. In contrast to regular gradient-based learning, ICL is highly interpretable and does not require parameter updates. In this paper, we show that, for linearized transformer networks, ICL can be made explicit and permanent through the inclusion of bias terms. We mathematically demonstrate the equivalence between a model with ICL demonstration prompts and the same model with the additional bias terms. Our algorithm (ICLCA) allows for exact conversion in an inexpensive manner. Existing methods are not exact and require expensive parameter updates. We demonstrate the efficacy of our approach through experiments that show the exact incorporation of ICL tokens into a linear transformer. We further suggest how our method can be adapted to achieve cheap approximate conversion of ICL tokens, even in regular transformer networks that are not linearized. Our experiments on GPT-2 show that, even though the conversion is only approximate, the model still gains valuable context from the included bias terms.