 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStatistical Mean Estimation with Coded Relayed Observations
May 14, 2025We consider a problem of statistical mean estimation in which the samples are not observed directly, but are instead observed by a relay (``teacher'') that transmits information through a memoryless channel to the decoder (``student''), who then produces the final estimate. We consider the minimax estimation error in the large deviations regime, and establish achievable error exponents that are tight in broad regimes of the estimation accuracy and channel quality. In contrast, two natural baseline methods are shown to yield strictly suboptimal error exponents. We initially focus on Bernoulli sources and binary symmetric channels, and then generalize to sub-Gaussian and heavy-tailed settings along with arbitrary discrete memoryless channels.
Memory-Efficient LLM Training by Various-Grained Low-Rank Projection of Gradients
May 03, 2025Building upon the success of low-rank adapter (LoRA), low-rank gradient projection (LoRP) has emerged as a promising solution for memory-efficient fine-tuning. However, existing LoRP methods typically treat each row of the gradient matrix as the default projection unit, leaving the role of projection granularity underexplored. In this work, we propose a novel framework, VLoRP, that extends low-rank gradient projection by introducing an additional degree of freedom for controlling the trade-off between memory efficiency and performance, beyond the rank hyper-parameter. Through this framework, we systematically explore the impact of projection granularity, demonstrating that finer-grained projections lead to enhanced stability and efficiency even under a fixed memory budget. Regarding the optimization for VLoRP, we present ProjFactor, an adaptive memory-efficient optimizer, that significantly reduces memory requirement while ensuring competitive performance, even in the presence of gradient accumulation. Additionally, we provide a theoretical analysis of VLoRP, demonstrating the descent and convergence of its optimization trajectory under both SGD and ProjFactor. Extensive experiments are conducted to validate our findings, covering tasks such as commonsense reasoning, MMLU, and GSM8K.
Memory-Efficient Gradient Unrolling for Large-Scale Bi-level Optimization
Jun 20, 2024

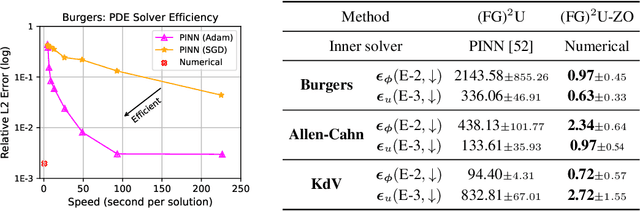

Bi-level optimization (BO) has become a fundamental mathematical framework for addressing hierarchical machine learning problems. As deep learning models continue to grow in size, the demand for scalable bi-level optimization solutions has become increasingly critical. Traditional gradient-based bi-level optimization algorithms, due to their inherent characteristics, are ill-suited to meet the demands of large-scale applications. In this paper, we introduce $\textbf{F}$orward $\textbf{G}$radient $\textbf{U}$nrolling with $\textbf{F}$orward $\textbf{F}$radient, abbreviated as $(\textbf{FG})^2\textbf{U}$, which achieves an unbiased stochastic approximation of the meta gradient for bi-level optimization. $(\text{FG})^2\text{U}$ circumvents the memory and approximation issues associated with classical bi-level optimization approaches, and delivers significantly more accurate gradient estimates than existing large-scale bi-level optimization approaches. Additionally, $(\text{FG})^2\text{U}$ is inherently designed to support parallel computing, enabling it to effectively leverage large-scale distributed computing systems to achieve significant computational efficiency. In practice, $(\text{FG})^2\text{U}$ and other methods can be strategically placed at different stages of the training process to achieve a more cost-effective two-phase paradigm. Further, $(\text{FG})^2\text{U}$ is easy to implement within popular deep learning frameworks, and can be conveniently adapted to address more challenging zeroth-order bi-level optimization scenarios. We provide a thorough convergence analysis and a comprehensive practical discussion for $(\text{FG})^2\text{U}$, complemented by extensive empirical evaluations, showcasing its superior performance in diverse large-scale bi-level optimization tasks.
Bias-Variance Trade-off in Physics-Informed Neural Networks with Randomized Smoothing for High-Dimensional PDEs
Nov 26, 2023While physics-informed neural networks (PINNs) have been proven effective for low-dimensional partial differential equations (PDEs), the computational cost remains a hurdle in high-dimensional scenarios. This is particularly pronounced when computing high-order and high-dimensional derivatives in the physics-informed loss. Randomized Smoothing PINN (RS-PINN) introduces Gaussian noise for stochastic smoothing of the original neural net model, enabling Monte Carlo methods for derivative approximation, eliminating the need for costly auto-differentiation. Despite its computational efficiency in high dimensions, RS-PINN introduces biases in both loss and gradients, negatively impacting convergence, especially when coupled with stochastic gradient descent (SGD). We present a comprehensive analysis of biases in RS-PINN, attributing them to the nonlinearity of the Mean Squared Error (MSE) loss and the PDE nonlinearity. We propose tailored bias correction techniques based on the order of PDE nonlinearity. The unbiased RS-PINN allows for a detailed examination of its pros and cons compared to the biased version. Specifically, the biased version has a lower variance and runs faster than the unbiased version, but it is less accurate due to the bias. To optimize the bias-variance trade-off, we combine the two approaches in a hybrid method that balances the rapid convergence of the biased version with the high accuracy of the unbiased version. In addition, we present an enhanced implementation of RS-PINN. Extensive experiments on diverse high-dimensional PDEs, including Fokker-Planck, HJB, viscous Burgers', Allen-Cahn, and Sine-Gordon equations, illustrate the bias-variance trade-off and highlight the effectiveness of the hybrid RS-PINN. Empirical guidelines are provided for selecting biased, unbiased, or hybrid versions, depending on the dimensionality and nonlinearity of the specific PDE problem.