 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMemory-Efficient Gradient Unrolling for Large-Scale Bi-level Optimization
Paper and Code
Jun 20, 2024

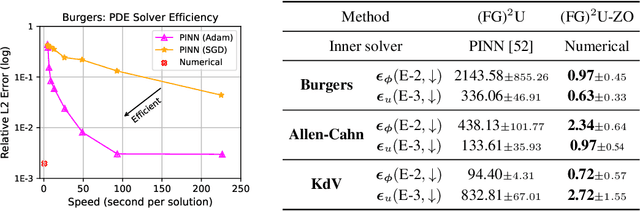

Bi-level optimization (BO) has become a fundamental mathematical framework for addressing hierarchical machine learning problems. As deep learning models continue to grow in size, the demand for scalable bi-level optimization solutions has become increasingly critical. Traditional gradient-based bi-level optimization algorithms, due to their inherent characteristics, are ill-suited to meet the demands of large-scale applications. In this paper, we introduce $\textbf{F}$orward $\textbf{G}$radient $\textbf{U}$nrolling with $\textbf{F}$orward $\textbf{F}$radient, abbreviated as $(\textbf{FG})^2\textbf{U}$, which achieves an unbiased stochastic approximation of the meta gradient for bi-level optimization. $(\text{FG})^2\text{U}$ circumvents the memory and approximation issues associated with classical bi-level optimization approaches, and delivers significantly more accurate gradient estimates than existing large-scale bi-level optimization approaches. Additionally, $(\text{FG})^2\text{U}$ is inherently designed to support parallel computing, enabling it to effectively leverage large-scale distributed computing systems to achieve significant computational efficiency. In practice, $(\text{FG})^2\text{U}$ and other methods can be strategically placed at different stages of the training process to achieve a more cost-effective two-phase paradigm. Further, $(\text{FG})^2\text{U}$ is easy to implement within popular deep learning frameworks, and can be conveniently adapted to address more challenging zeroth-order bi-level optimization scenarios. We provide a thorough convergence analysis and a comprehensive practical discussion for $(\text{FG})^2\text{U}$, complemented by extensive empirical evaluations, showcasing its superior performance in diverse large-scale bi-level optimization tasks.