 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning a Latent Pulse Shape Interface for Photoinjector Laser Systems
Feb 19, 2026Controlling the longitudinal laser pulse shape in photoinjectors of Free-Electron Lasers is a powerful lever for optimizing electron beam quality, but systematic exploration of the vast design space is limited by the cost of brute-force pulse propagation simulations. We present a generative modeling framework based on Wasserstein Autoencoders to learn a differentiable latent interface between pulse shaping and downstream beam dynamics. Our empirical findings show that the learned latent space is continuous and interpretable while maintaining high-fidelity reconstructions. Pulse families such as higher-order Gaussians trace coherent trajectories, while standardizing the temporal pulse lengths shows a latent organization correlated with pulse energy. Analysis via principal components and Gaussian Mixture Models reveals a well behaved latent geometry, enabling smooth transitions between distinct pulse types via linear interpolation. The model generalizes from simulated data to real experimental pulse measurements, accurately reconstructing pulses and embedding them consistently into the learned manifold. Overall, the approach reduces reliance on expensive pulse-propagation simulations and facilitates downstream beam dynamics simulation and analysis.
Dynamics-Aligned Shared Hypernetworks for Zero-Shot Actuator Inversion
Feb 06, 2026Zero-shot generalization in contextual reinforcement learning remains a core challenge, particularly when the context is latent and must be inferred from data. A canonical failure mode is actuator inversion, where identical actions produce opposite physical effects under a latent binary context. We propose DMA*-SH, a framework where a single hypernetwork, trained solely via dynamics prediction, generates a small set of adapter weights shared across the dynamics model, policy, and action-value function. This shared modulation imparts an inductive bias matched to actuator inversion, while input/output normalization and random input masking stabilize context inference, promoting directionally concentrated representations. We provide theoretical support via an expressivity separation result for hypernetwork modulation, and a variance decomposition with policy-gradient variance bounds that formalize how within-mode compression improves learning under actuator inversion. For evaluation, we introduce the Actuator Inversion Benchmark (AIB), a suite of environments designed to isolate discontinuous context-to-dynamics interactions. On AIB's held-out actuator-inversion tasks, DMA*-SH achieves zero-shot generalization, outperforming domain randomization by 111.8% and surpassing a standard context-aware baseline by 16.1%.
Oversquashing in GNNs through the lens of information contraction and graph expansion
Aug 06, 2022The quality of signal propagation in message-passing graph neural networks (GNNs) strongly influences their expressivity as has been observed in recent works. In particular, for prediction tasks relying on long-range interactions, recursive aggregation of node features can lead to an undesired phenomenon called "oversquashing". We present a framework for analyzing oversquashing based on information contraction. Our analysis is guided by a model of reliable computation due to von Neumann that lends a new insight into oversquashing as signal quenching in noisy computation graphs. Building on this, we propose a graph rewiring algorithm aimed at alleviating oversquashing. Our algorithm employs a random local edge flip primitive motivated by an expander graph construction. We compare the spectral expansion properties of our algorithm with that of an existing curvature-based non-local rewiring strategy. Synthetic experiments show that while our algorithm in general has a slower rate of expansion, it is overall computationally cheaper, preserves the node degrees exactly and never disconnects the graph.
Learning curves for Gaussian process regression with power-law priors and targets
Oct 23, 2021
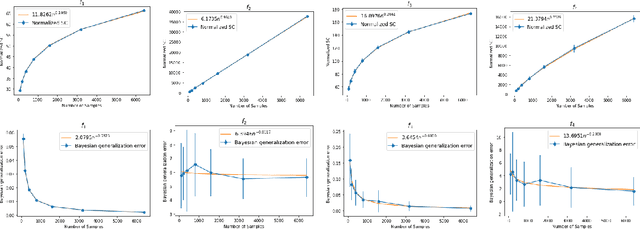
We study the power-law asymptotics of learning curves for Gaussian process regression (GPR). When the eigenspectrum of the prior decays with rate $\alpha$ and the eigenexpansion coefficients of the target function decay with rate $\beta$, we show that the generalization error behaves as $\tilde O(n^{\max\{\frac{1}{\alpha}-1, \frac{1-2\beta}{\alpha}\}})$ with high probability over the draw of $n$ input samples. Under similar assumptions, we show that the generalization error of kernel ridge regression (KRR) has the same asymptotics. Infinitely wide neural networks can be related to KRR with respect to the neural tangent kernel (NTK), which in several cases is known to have a power-law spectrum. Hence our methods can be applied to study the generalization error of infinitely wide neural networks. We present toy experiments demonstrating the theory.
Information Complexity and Generalization Bounds
May 04, 2021We present a unifying picture of PAC-Bayesian and mutual information-based upper bounds on the generalization error of randomized learning algorithms. As we show, Tong Zhang's information exponential inequality (IEI) gives a general recipe for constructing bounds of both flavors. We show that several important results in the literature can be obtained as simple corollaries of the IEI under different assumptions on the loss function. Moreover, we obtain new bounds for data-dependent priors and unbounded loss functions. Optimizing the bounds gives rise to variants of the Gibbs algorithm, for which we discuss two practical examples for learning with neural networks, namely, Entropy- and PAC-Bayes- SGD. Further, we use an Occam's factor argument to show a PAC-Bayesian bound that incorporates second-order curvature information of the training loss.
The Variational Deficiency Bottleneck
Oct 27, 2018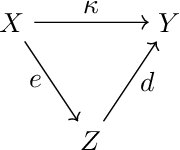
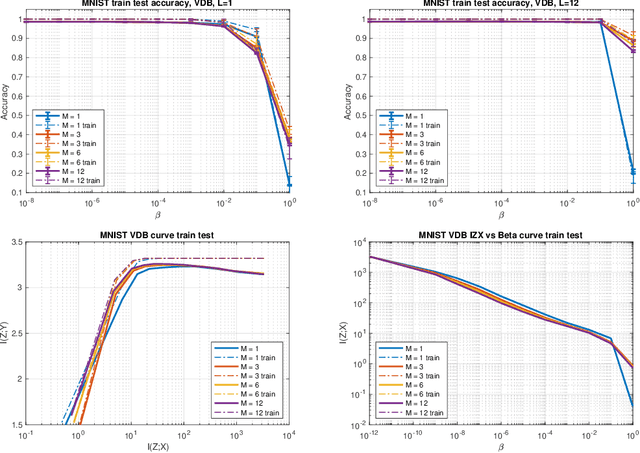
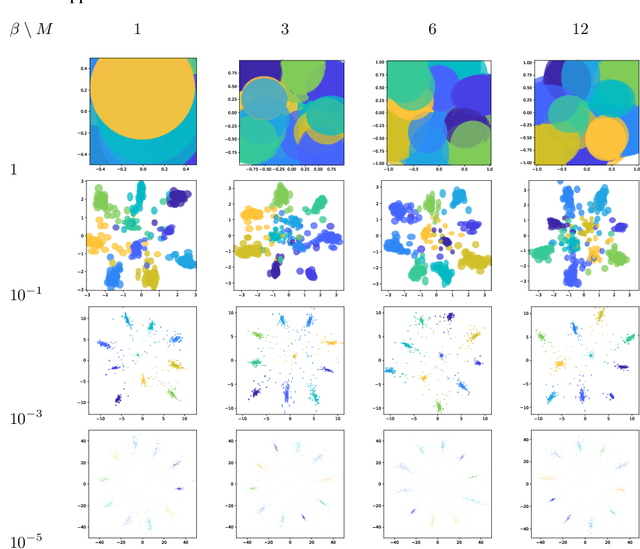
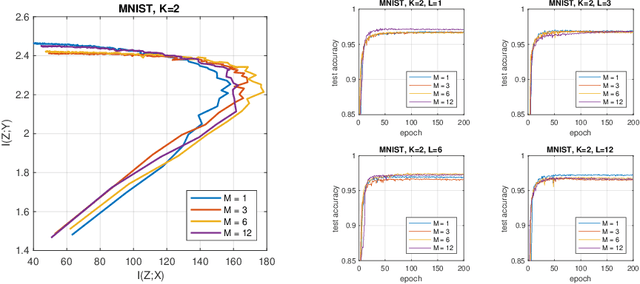
We introduce a bottleneck method for learning data representations based on channel deficiency, rather than the more traditional information sufficiency. A variational upper bound allows us to implement this method efficiently. The bound itself is bounded above by the variational information bottleneck objective, and the two methods coincide in the regime of single-shot Monte Carlo approximations. The notion of deficiency provides a principled way of approximating complicated channels by relatively simpler ones. The deficiency of one channel w.r.t. another has an operational interpretation in terms of the optimal risk gap of decision problems, capturing classification as a special case. Unsupervised generalizations are possible, such as the deficiency autoencoder, which can also be formulated in a variational form. Experiments demonstrate that the deficiency bottleneck can provide advantages in terms of minimal sufficiency as measured by information bottleneck curves, while retaining a good test performance in classification and reconstruction tasks.