 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTight Bounds on the Smallest Eigenvalue of the Neural Tangent Kernel for Deep ReLU Networks
Paper and Code
Dec 23, 2020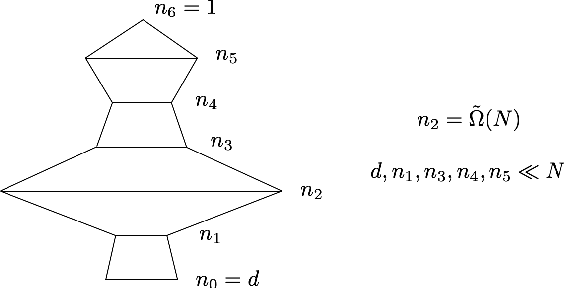
A recent line of work has analyzed the theoretical properties of deep neural networks via the Neural Tangent Kernel (NTK). In particular, the smallest eigenvalue of the NTK has been related to memorization capacity, convergence of gradient descent algorithms and generalization of deep nets. However, existing results either provide bounds in the two-layer setting or assume that the spectrum of the NTK is bounded away from 0 for multi-layer networks. In this paper, we provide tight bounds on the smallest eigenvalue of NTK matrices for deep ReLU networks, both in the limiting case of infinite widths and for finite widths. In the finite-width setting, the network architectures we consider are quite general: we require the existence of a wide layer with roughly order of $N$ neurons, $N$ being the number of data samples; and the scaling of the remaining widths is arbitrary (up to logarithmic factors). To obtain our results, we analyze various quantities of independent interest: we give lower bounds on the smallest singular value of feature matrices, and upper bounds on the Lipschitz constant of input-output feature maps.