 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the optimization and pruning for Bayesian deep learning
Oct 24, 2022



The goal of Bayesian deep learning is to provide uncertainty quantification via the posterior distribution. However, exact inference over the weight space is computationally intractable due to the ultra-high dimensions of the neural network. Variational inference (VI) is a promising approach, but naive application on weight space does not scale well and often underperform on predictive accuracy. In this paper, we propose a new adaptive variational Bayesian algorithm to train neural networks on weight space that achieves high predictive accuracy. By showing that there is an equivalence to Stochastic Gradient Hamiltonian Monte Carlo(SGHMC) with preconditioning matrix, we then propose an MCMC within EM algorithm, which incorporates the spike-and-slab prior to capture the sparsity of the neural network. The EM-MCMC algorithm allows us to perform optimization and model pruning within one-shot. We evaluate our methods on CIFAR-10, CIFAR-100 and ImageNet datasets, and demonstrate that our dense model can reach the state-of-the-art performance and our sparse model perform very well compared to previously proposed pruning schemes.
Approximate Equivariance SO(3) Needlet Convolution
Jun 17, 2022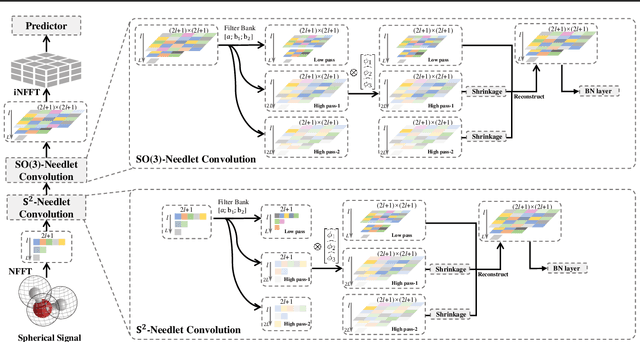


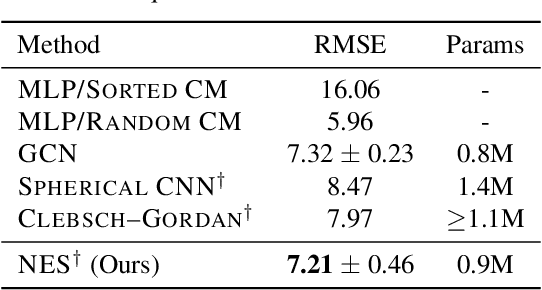
This paper develops a rotation-invariant needlet convolution for rotation group SO(3) to distill multiscale information of spherical signals. The spherical needlet transform is generalized from $\mathbb{S}^2$ onto the SO(3) group, which decomposes a spherical signal to approximate and detailed spectral coefficients by a set of tight framelet operators. The spherical signal during the decomposition and reconstruction achieves rotation invariance. Based on needlet transforms, we form a Needlet approximate Equivariance Spherical CNN (NES) with multiple SO(3) needlet convolutional layers. The network establishes a powerful tool to extract geometric-invariant features of spherical signals. The model allows sufficient network scalability with multi-resolution representation. A robust signal embedding is learned with wavelet shrinkage activation function, which filters out redundant high-pass representation while maintaining approximate rotation invariance. The NES achieves state-of-the-art performance for quantum chemistry regression and Cosmic Microwave Background (CMB) delensing reconstruction, which shows great potential for solving scientific challenges with high-resolution and multi-scale spherical signal representation.
CosmoVAE: Variational Autoencoder for CMB Image Inpainting
Jan 31, 2020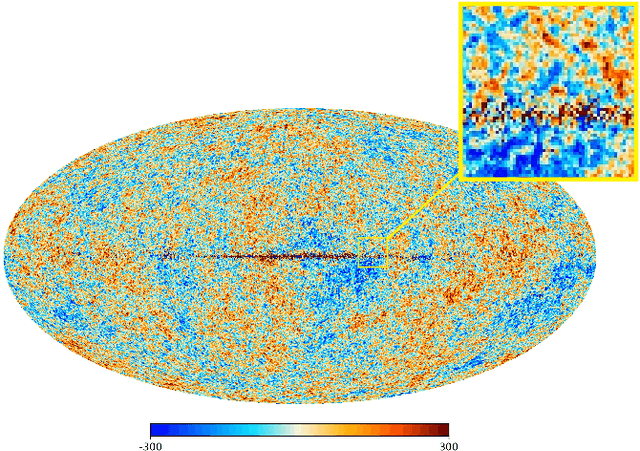
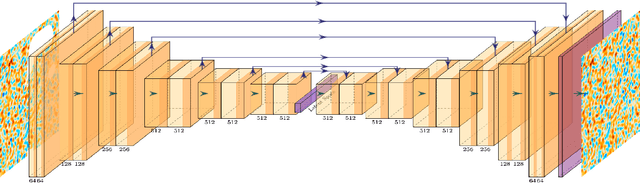
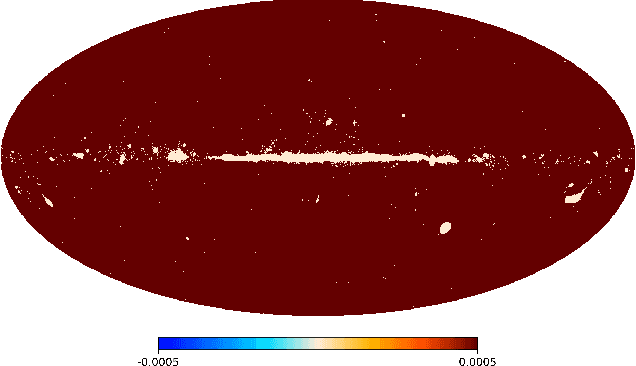
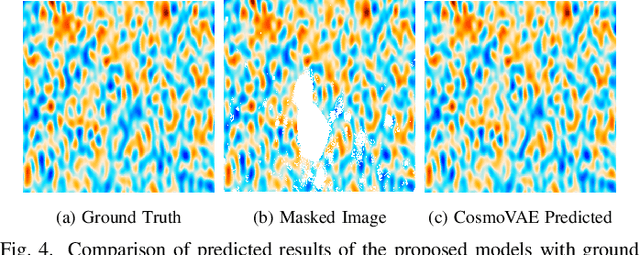
Cosmic microwave background radiation (CMB) is critical to the understanding of the early universe and precise estimation of cosmological constants. Due to the contamination of thermal dust noise in the galaxy, the CMB map that is an image on the two-dimensional sphere has missing observations, mainly concentrated on the equatorial region. The noise of the CMB map has a significant impact on the estimation precision for cosmological parameters. Inpainting the CMB map can effectively reduce the uncertainty of parametric estimation. In this paper, we propose a deep learning-based variational autoencoder --- CosmoVAE, to restoring the missing observations of the CMB map. The input and output of CosmoVAE are square images. To generate training, validation, and test data sets, we segment the full-sky CMB map into many small images by Cartesian projection. CosmoVAE assigns physical quantities to the parameters of the VAE network by using the angular power spectrum of the Gaussian random field as latent variables. CosmoVAE adopts a new loss function to improve the learning performance of the model, which consists of $\ell_1$ reconstruction loss, Kullback-Leibler divergence between the posterior distribution of encoder network and the prior distribution of latent variables, perceptual loss, and total-variation regularizer. The proposed model achieves state of the art performance for Planck \texttt{Commander} 2018 CMB map inpainting.
HaarPooling: Graph Pooling with Compressive Haar Basis
Sep 25, 2019
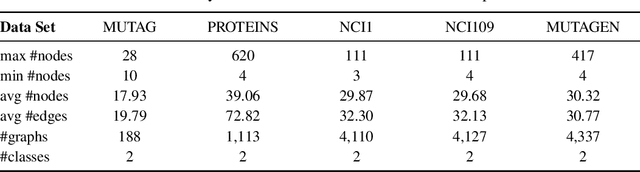
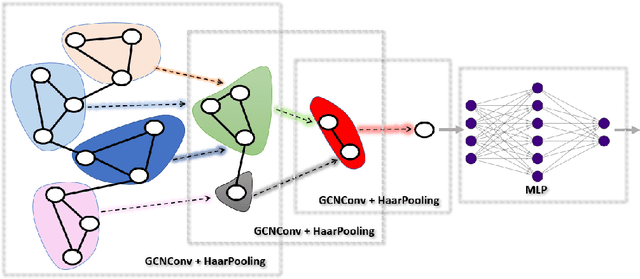

Deep Graph Neural Networks (GNNs) are instrumental in graph classification and graph-based regression tasks. In these tasks, graph pooling is a critical ingredient by which GNNs adapt to input graphs of varying size and structure. We propose a new graph pooling operation based on compressive Haar transforms, called HaarPooling. HaarPooling is computed following a chain of sequential clusterings of the input graph. The input of each pooling layer is transformed by the compressive Haar basis of the corresponding clustering. HaarPooling operates in the frequency domain by the synthesis of nodes in the same cluster and filters out fine detail information by compressive Haar transforms. Such transforms provide an effective characterization of the data and preserve the structure information of the input graph. By the sparsity of the Haar basis, the computation of HaarPooling is of linear complexity. The GNN with HaarPooling and existing graph convolution layers achieves state-of-the-art performance on diverse graph classification problems.