 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptive Importance Sampling and Quasi-Monte Carlo Methods for 6G URLLC Systems
Mar 07, 2023
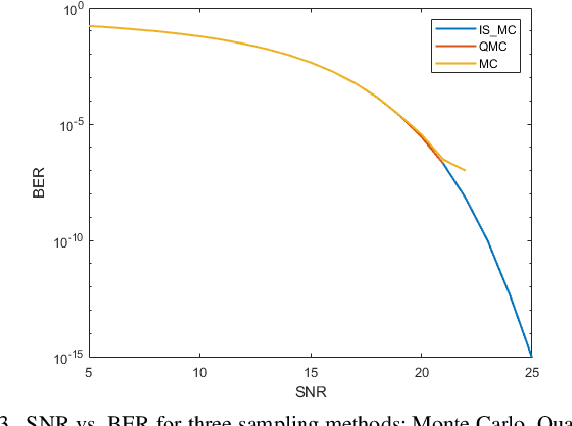
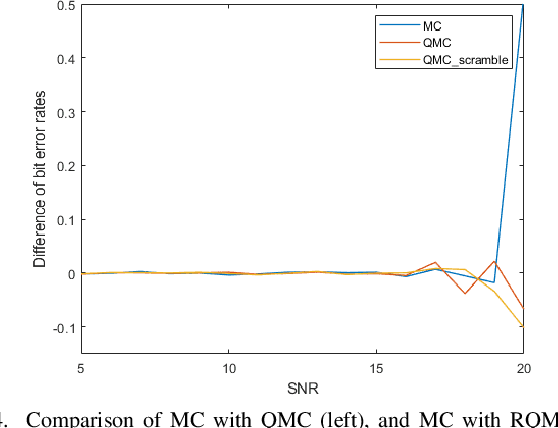
In this paper, we propose an efficient simulation method based on adaptive importance sampling, which can automatically find the optimal proposal within the Gaussian family based on previous samples, to evaluate the probability of bit error rate (BER) or word error rate (WER). These two measures, which involve high-dimensional black-box integration and rare-event sampling, can characterize the performance of coded modulation. We further integrate the quasi-Monte Carlo method within our framework to improve the convergence speed. The proposed importance sampling algorithm is demonstrated to have much higher efficiency than the standard Monte Carlo method in the AWGN scenario.
On the optimization and pruning for Bayesian deep learning
Oct 24, 2022



The goal of Bayesian deep learning is to provide uncertainty quantification via the posterior distribution. However, exact inference over the weight space is computationally intractable due to the ultra-high dimensions of the neural network. Variational inference (VI) is a promising approach, but naive application on weight space does not scale well and often underperform on predictive accuracy. In this paper, we propose a new adaptive variational Bayesian algorithm to train neural networks on weight space that achieves high predictive accuracy. By showing that there is an equivalence to Stochastic Gradient Hamiltonian Monte Carlo(SGHMC) with preconditioning matrix, we then propose an MCMC within EM algorithm, which incorporates the spike-and-slab prior to capture the sparsity of the neural network. The EM-MCMC algorithm allows us to perform optimization and model pruning within one-shot. We evaluate our methods on CIFAR-10, CIFAR-100 and ImageNet datasets, and demonstrate that our dense model can reach the state-of-the-art performance and our sparse model perform very well compared to previously proposed pruning schemes.