 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnder-Parameterized Double Descent for Ridge Regularized Least Squares Denoising of Data on a Line
Paper and Code
May 24, 2023
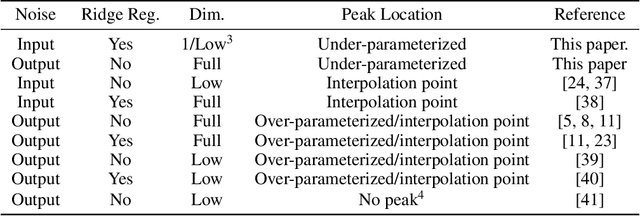
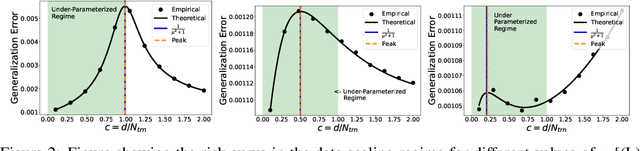
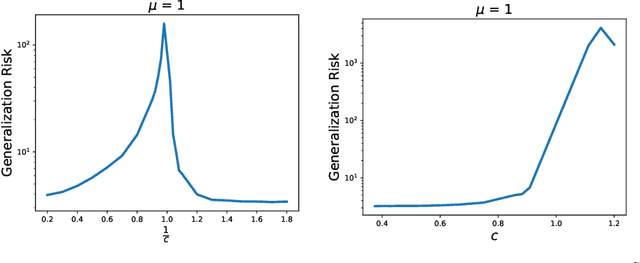
The relationship between the number of training data points, the number of parameters in a statistical model, and the generalization capabilities of the model has been widely studied. Previous work has shown that double descent can occur in the over-parameterized regime, and believe that the standard bias-variance trade-off holds in the under-parameterized regime. In this paper, we present a simple example that provably exhibits double descent in the under-parameterized regime. For simplicity, we look at the ridge regularized least squares denoising problem with data on a line embedded in high-dimension space. By deriving an asymptotically accurate formula for the generalization error, we observe sample-wise and parameter-wise double descent with the peak in the under-parameterized regime rather than at the interpolation point or in the over-parameterized regime. Further, the peak of the sample-wise double descent curve corresponds to a peak in the curve for the norm of the estimator, and adjusting $\mu$, the strength of the ridge regularization, shifts the location of the peak. We observe that parameter-wise double descent occurs for this model for small $\mu$. For larger values of $\mu$, we observe that the curve for the norm of the estimator has a peak but that this no longer translates to a peak in the generalization error. Moreover, we study the training error for this problem. The considered problem setup allows for studying the interaction between two regularizers. We provide empirical evidence that the model implicitly favors using the ridge regularizer over the input data noise regularizer. Thus, we show that even though both regularizers regularize the same quantity, i.e., the norm of the estimator, they are not equivalent.